Preparing for your MongoDB Deployment: Schema Design & Access Patterns
MongoDB Atlas radically simplifies the operation of MongoDB. As with any hosted database as a service there are still decisions you need to take to ensure the best performance and availability for your application. This blog series provides a number of recommendations that will serve as a solid foundation for getting the most out of the MongoDB Atlas service.
We’ll cover four main areas over this series of blog posts:
- In this part 1 post, we’ll get started with preparing for your deployment, focusing specifically on schema design and application access patterns.
- In part 2, we’ll discuss additional considerations as you prepare for your deployment, including indexing, data migration, and instance selection.
- In part 3, we’ll dive into how you scale your MongoDB Atlas deployment, and achieve your required availability SLAs.
- In the final part 4, we’ll wrap up with best practices for operational management and ensuring data security.
If you want to get a head start and learn about all of these topics now, just go ahead and download the MongoDB Atlas Best Practices guide.
So What is MongoDB Atlas?
MongoDB Atlas provides all of the features of MongoDB, without the operational heavy lifting required for any new application. MongoDB Atlas is available on-demand through a pay-as-you-go model and billed on an hourly basis, letting you focus on your code and your customers.
It’s easy to get started – use a simple GUI to select the appropriate instance size, geographic region, and features you need. MongoDB Atlas provides:
- Security features to protect access to your data
- Built in replication for always-on availability, tolerating complete data center failure
- Backups and point in time recovery to protect against data corruption
- Fine-grained monitoring to help you know when to scale. Additional instances can be provisioned with the push of a button
- Automated patching and one-click upgrades for new major versions of the database, enabling you to take advantage of the latest and greatest MongoDB features
- A choice of cloud providers, regions, and billing options
MongoDB Atlas is versatile. It’s great for everything from a quick Proof of Concept, to test/QA environments, to complete production clusters. If you decide you want to bring operations back under your control, it is easy to move your databases onto your own infrastructure and manage them using MongoDB Ops Manager or MongoDB Cloud Manager. The user experience across MongoDB Atlas, Cloud Manager, and Ops Manager is consistent, ensuring that disruption is minimal if you decide to migrate to your own infrastructure.
So now that you know what MongoDB Atlas is, let’s get started preparing for our deployment.
Schema Design
Developers and data architects should work together to develop the right data model, and they should invest time in this exercise early in the project. The requirements of the application should drive the data model, updates, and queries of your MongoDB system. Given MongoDB's dynamic schema, developers and data architects can continue to iterate on the data model throughout the development and deployment processes to optimize performance and storage efficiency, as well as support the addition of new application features. All of this can be done without expensive schema migrations.
Document Model
MongoDB stores data as documents in a binary representation called BSON. The BSON encoding extends the popular JSON representation to include additional types such as int, long, and date. BSON documents contain one or more fields, and each field contains a value of a specific data type, including arrays, sub-documents and binary data. It may be helpful to think of documents as roughly equivalent to rows in a relational database, and fields as roughly equivalent to columns. However, MongoDB documents tend to have all related data for a given record or object in a single document, whereas in a relational database that data is usually normalized across rows in many tables. For example, data that belongs to a parent-child relationship in two RDBMS tables can frequently be collapsed (embedded) into a single document in MongoDB. For operational applications, the document model makes JOINs redundant in many cases.
Where possible, store all data for a record in a single document. MongoDB provides ACID compliance at the document level. When data for a record is stored in a single document the entire record can be retrieved in a single seek operation, which is very efficient. In some cases it may not be practical to store all data in a single document, or it may negatively impact other operations. Make the trade-offs that are best for your application.
Rather than storing a large array of items in an indexed field, storing groups of values across multiple fields results in more efficient updates.
Collections
Collections are groupings of documents. Typically all documents in a collection have similar or related purposes for an application. It may be helpful to think of collections as being analogous to tables in a relational database.
Dynamic Schema & Document Validation
MongoDB documents can vary in structure. For example, documents that describe users might all contain the user id and the last date they logged into the system, but only some of these documents might contain the user's shipping address, and perhaps some of those contain multiple shipping addresses. MongoDB does not require that all documents conform to the same structure. Furthermore, there is no need to declare the structure of documents to the system – documents are self-describing.
DBAs and developers have the option to define Document Validation rules for a collection – enabling them to enforce checks on selected parts of a document's structure, data types, data ranges, and the presence of mandatory fields. As a result, DBAs can apply data governance standards, while developers maintain the benefits of a flexible document model. These are covered in the blog post Document Validation: Adding Just the Right Amount of Control Over Your Documents.
Indexes
MongoDB uses B-tree indexes to optimize queries. Indexes are defined on a collection’s document fields. MongoDB includes support for many indexes, including compound, geospatial, TTL, text search, sparse, partial, unique, and others. For more information see the section on indexing in the 2nd instalment of this blog series.
Transactions
Atomicity of updates may influence the schema for your application. MongoDB guarantees ACID compliant updates to data at the document level. It is not possible to update multiple documents in a single atomic operation, however the ability to embed related data into MongoDB documents eliminates this requirement in many cases. For use cases that do require multiple documents to be updated atomically, it is possible to implement Two Phase Commit logic in the application.
Visualizing your Schema: MongoDB Compass
The MongoDB Compass GUI allows users to understand the structure of existing data in the database and perform ad hoc queries against it – all with zero knowledge of MongoDB's query language. Typical users could include architects building a new MongoDB project or a DBA who has inherited a database from an engineering team, and who must now maintain it in production. You need to understand what kind of data is present, define what indexes might be appropriate, and identify if Document Validation rules should be added to enforce a consistent document structure.
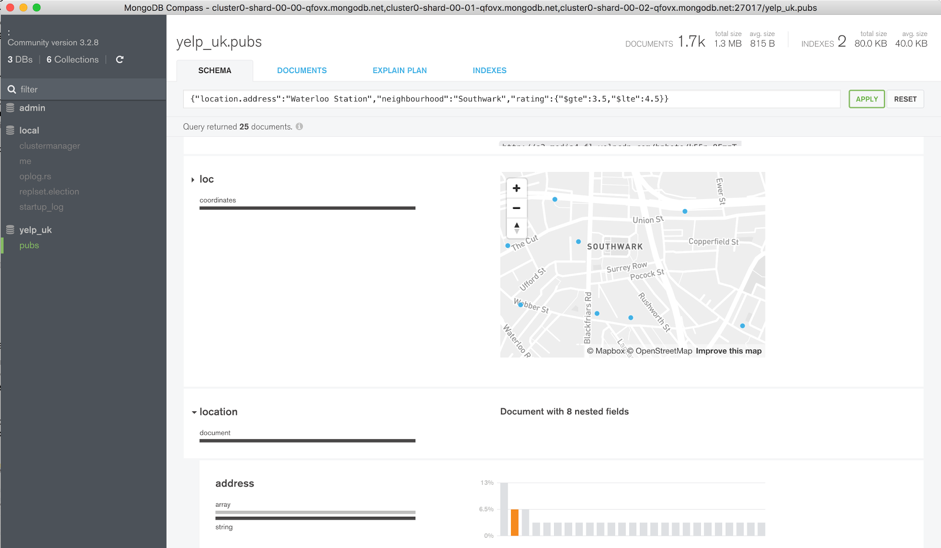
*Figure 1: View schema & interactively build and execute database queries with MongoDB Compass*
Without MongoDB Compass, users wishing to understand the shape of their data would have to connect to the MongoDB shell and write queries to reverse engineer the document structure, field names, and data types. Similarly, anyone wanting to run custom queries on the data would need to understand MongoDB's query language.
MongoDB Compass can be used for free during development and it is also available for production use with MongoDB Professional or MongoDB Enterprise Advanced subscriptions.
Application Access Patterns
Schema design has a huge influence on database performance. How the application accesses the data can also have a major impact.
Searching on indexed attributes is typically the single most important pattern as it avoids collection scans. Taking it a step further, using covered queries avoids the need to access the collection data altogether. Covered queries return results from the indexes directly without accessing documents and are therefore very efficient. For a query to be covered, all the fields included in the query must be present in an index, and all the fields returned by the query must also be present in that index. To determine whether a query is a covered query, use the explain() method. If the explain() output displays true for the indexOnly field, the query is covered by an index, and MongoDB queries only that index to match the query and return the results.
Rather than retrieving the entire document in your application, updating fields, then saving the document back to the database, instead issue the update to specific fields. This has the advantage of less network usage and reduced database overhead.
Document Size
The maximum BSON document size in MongoDB is 16 MB. Users should avoid certain application patterns that would allow documents to grow unbounded. For example, in an e-commerce application it would be difficult to estimate how many reviews each product might receive from customers. Furthermore, it is typically the case that only a subset of reviews is displayed to a user, such as the most popular or the most recent reviews. Rather than modeling the product and customer reviews as a single document it would be better to model each review or groups of reviews as a separate document with a reference to the product document; while also storing the key reviews in the product document for fast access.
In practice most documents are a few kilobytes or less. Consider documents more like rows in a table than the tables themselves. Rather than maintaining lists of records in a single document, instead make each record a document. For large media items, such as video or images, consider using GridFS, a convention implemented by all the drivers that automatically stores the binary data across many smaller documents
Field names are repeated across documents and consume space – RAM in particular. By using smaller field names your data will consume less space, which allows for a larger number of documents to fit in RAM.
Data Lifecycle Management
MongoDB provides features to facilitate the management of data lifecycles, including Time to Live indexes, and capped collections.
Time to Live (TTL)
If documents in a collection should only persist for a pre-defined period of time, the TTL feature can be used to automatically delete documents of a certain age rather than scheduling a process to check the age of all documents and run a series of deletes. For example, if user sessions should only exist for one hour, the TTL can be set to 3600 seconds for a date field called lastActivity that exists in documents used to track user sessions and their last interaction with the system. A background thread will automatically check all these documents and delete those that have been idle for more than 3600 seconds. Another example use case for TTL is a price quote that should automatically expire after a period of time.
Capped Collections
In some cases a rolling window of data should be maintained in the system based on data size. Capped collections are fixed-size collections that support high-throughput inserts and reads based on insertion order. A capped collection behaves like a circular buffer: data is inserted into the collection, that insertion order is preserved, and when the total size reaches the threshold of the capped collection, the oldest documents are deleted to make room for the newest documents. For example, store log information from a high-volume system in a capped collection to quickly retrieve the most recent log entries.
Dropping a Collection
It is very efficient to drop a collection in MongoDB. If your data lifecycle management requires periodically deleting large volumes of documents, it may be best to model those documents as a single collection. Dropping a collection is much more efficient than removing all documents or a large subset of a collection, just as dropping a table is more efficient than deleting all the rows in a table in a relational database.
Disk space is automatically reclaimed after a collection is dropped.
Next Steps
That’s a wrap for part 1 of the MongoDB Atlas best practices blog series. In Part 2, we’ll continue along the path of preparing for our first deployment by discussing indexing and data migration.