Preparing for your MongoDB Deployment: Indexing, Data Migration & Instance Selection
MongoDB Atlas radically simplifies the operation of MongoDB. As with any hosted database as a service there are still decisions you need to take to ensure the best performance and availability for your application. This blog series provides a series of recommendations that will serve as a solid foundation for getting the most out of the MongoDB Atlas service.
We’ll cover four main areas over this series of blog posts:
- In part 1, we got started by preparing for our deployment, focusing specifically on schema design and application access patterns.
- In this part 2 post, we’ll discuss additional considerations as you prepare for your deployment, including indexing, data migration and instance selection.
- In part 3, we’ll dive into how you scale your MongoDB Atlas deployment, and achieve your required availability SLAs.
- In the final part 4, we’ll wrap up with best practices for operational management and ensuring data security.
If you want to get a head start and learn about all of these topics now, just go ahead and download the MongoDB Atlas Best Practices guide.
Indexing
Like most database management systems, indexes are a crucial mechanism for optimizing MongoDB query performance. While indexes will improve the performance of some operations by one or more orders of magnitude, they incur overhead to updates, disk space, and memory usage. Users should always create indexes to support queries, but should not maintain indexes that queries do not use. This is particularly important for deployments that support insert-heavy (or writes which modify indexed values) workloads.
To understand the effectiveness of the existing indexes being used, an $indexStats aggregation stage can be used to determine how frequently each index is used. This information can also be accessed through MongoDB Compass.
Query Optimization
Queries are automatically optimized by MongoDB to make evaluation of the query as efficient as possible. Evaluation normally includes the selection of data based on predicates, and the sorting of data based on the sort criteria provided. The query optimizer selects the best indexes to use by periodically running alternate query plans and selecting the index with the best performance for each query type. The results of this empirical test are stored as a cached query plan and periodically updated.
MongoDB provides an explain plan capability that shows information about how a query will be, or was, resolved, including:
- The number of documents returned
- The number of documents read
- Which indexes were used
- Whether the query was covered, meaning no documents needed to be read to return results
- Whether an in-memory sort was performed, which indicates an index would be beneficial
- The number of index entries scanned
- How long the query took to resolve in milliseconds (when using the executionStats mode)
- Which alternative query plans were rejected (when using the allPlansExecution mode)
The explain plan will show 0 milliseconds if the query was resolved in less than 1 ms, which is typical in well-tuned systems. When the explain plan is called, prior cached query plans are abandoned, and the process of testing multiple indexes is repeated to ensure the best possible plan is used. The query plan can be calculated and returned without first having to run the query. This enables DBAs to review which plan will be used to execute the query, without having to wait for the query to run to completion. The feedback from explain() will help you understand whether your query is performing optimally.
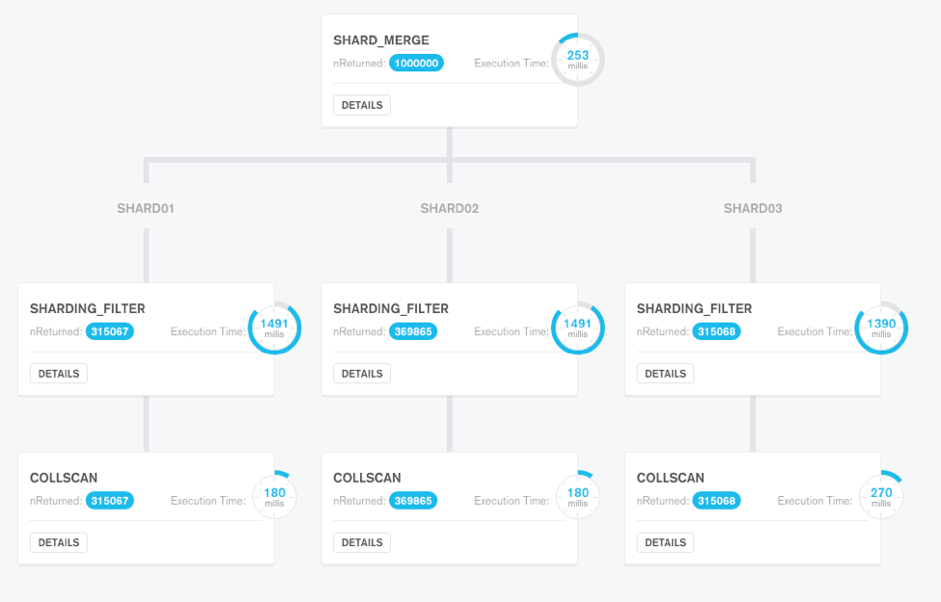
*Figure 1: MongoDB Compass visual explain plan*
MongoDB Compass also provides rich query plan visualizations to assist engineering teams to quickly access and optimize query execution.
Profiling
MongoDB provides a profiling capability called Database Profiler, which logs fine-grained information about database operations. The profiler can be enabled to log information for all events or only those events whose duration exceeds a configurable threshold (whose default is 100 ms). Profiling data is stored in a capped collection where it can easily be searched for relevant events. It may be easier to query this collection than parsing the log files.
Primary and Secondary Indexes
A unique index on the _id attribute is created for all documents. MongoDB will automatically create the _id field and assign a unique value if the value is not be specified when the document is inserted. All user-defined indexes are secondary indexes. MongoDB includes support for many types of secondary indexes that can be declared on any field(s) in the document, including fields within arrays and sub-documents. Index options include:
- Compound indexes
- Geospatial indexes
- Text search indexes
- Unique indexes
- Array indexes
- TTL indexes
- Sparse indexes
- Partial Indexes
- Hash indexes
You can learn more about each of these indexes from the MongoDB Architecture Guide
Index Creation Options
Indexes and data are updated synchronously in MongoDB, thus ensuring queries on indexes never return stale or deleted data. The appropriate indexes should be determined as part of the schema design process. By default creating an index is a blocking operation in MongoDB. Because the creation of indexes can be time and resource intensive, MongoDB provides an option for creating new indexes as a background operation on both the primary and secondary members of a replica set. When the background option is enabled, the total time to create an index will be greater than if the index was created in the foreground, but it will still be possible to query the database while creating indexes.
In addition, multiple indexes can be built concurrently in the background. Refer to the Build Index on Replica Sets documentation to learn more about considerations for index creation and on-going maintenance.
Common Mistakes Regarding Indexes
The following tips may help to avoid some common mistakes regarding indexes:
- Use a compound index rather than index intersection: For best performance when querying via multiple predicates, compound indexes will generally be a better option.
- Compound indexes: Compound indexes are defined and ordered by field. So, if a compound index is defined for last name, first name and city, queries that specify last name or last name and first name will be able to use this index, but queries that try to search based on city will not be able to benefit from this index. Remove indexes that are prefixes of other indexes.
- Low selectivity indexes: An index should radically reduce the set of possible documents to select from. For example, an index on a field that indicates gender is not as beneficial as an index on zip code, or even better, phone number.
- Regular expressions: Indexes are ordered by value, hence leading wildcards are inefficient and may result in full index scans. Trailing wildcards can be efficient if there are sufficient case-sensitive leading characters in the expression.
- Negation: Inequality queries can be inefficient with respect to indexes. Like most database systems, MongoDB does not index the absence of values and negation conditions may require scanning all documents. If negation is the only condition and it is not selective (for example, querying an orders table, where 99% of the orders are complete, to identify those that have not been fulfilled), all records will need to be scanned.
- Eliminate unnecessary indexes: Indexes are resource-intensive: even with they consume RAM, and as fields are updated their associated indexes must be maintained, incurring additional disk I/O overhead. To understand the effectiveness of the existing indexes being used, an $indexStats aggregation stage can be used to determine how frequently each index is used. If there are indexes that are not used then removing them will reduce storage and speed up writes.
Working Sets
MongoDB makes extensive use of RAM to speed up database operations. In MongoDB, all data is read and manipulated through in-memory representations of the data. Reading data from memory is measured in nanoseconds and reading data from disk is measured in milliseconds, thus reading from memory is orders of magnitude faster than reading from disk.
The set of data and indexes that are accessed during normal operations is called the working set. It is best practice that the working set fits in RAM. It may be the case the working set represents a fraction of the entire database, such as in applications where data related to recent events or popular products is accessed most commonly.
When MongoDB attempts to access data that has not been loaded in RAM, it must be read from disk. If there is free memory then the operating system can locate the data on disk and load it into memory directly. However, if there is no free memory, MongoDB must write some other data from memory to disk, and then read the requested data into memory. This process can be time consuming and significantly slower than accessing data that is already resident in memory.
Some operations may inadvertently purge a large percentage of the working set from memory, which adversely affects performance. For example, a query that scans all documents in the database, where the database is larger than available RAM on the server, will cause documents to be read into memory and may lead to portions of the working set being written out to disk. Other examples include various maintenance operations such as compacting or repairing a database and rebuilding indexes.
If your database working set size exceeds the available RAM of your system, consider provisioning an instance with larger RAM capacity (scaling up) or sharding the database across additional instances (scaling out). Scaling is an automated, on-line operation which is launched by selecting the new configuration after clicking the CONFIGURE button in MongoDB Atlas (Figure 1). For a discussion on this topic, refer to the section on Sharding Best Practices in part 3 of the blog series. It is easier to implement sharding before the system’s resources are consumed, so capacity planning is an important element in successful project delivery.
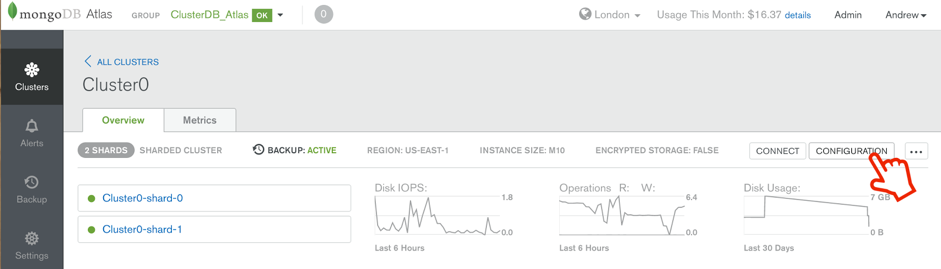
*Figure 2: Reconfiguring the MongoDB Atlas Cluster*
Data Migration
Users should assess how best to model their data for their applications rather than simply importing the flat file exports of their legacy systems. In a traditional relational database environment, data tends to be moved between systems using delimited flat files such as CSV. While it is possible to ingest data into MongoDB from CSV files, this may in fact only be the first step in a data migration process. It is typically the case that MongoDB's document data model provides advantages and alternatives that do not exist in a relational data model.
There are many options to migrate data from flat files into rich JSON documents, including mongoimport, custom scripts, ETL tools and from within an application itself which can read from the existing RDBMS and then write a JSON version of the document back to MongoDB.
Other tools such as mongodump and mongorestore, or MongoDB Atlas backups are useful for moving data between different MongoDB systems. The use of mongodump and mongorestore to migrate an application and its data to MongoDB Atlas is described in the post – Migrating Data to MongoDB Atlas.
MongoDB Atlas Instance Selection
The following recommendations are only intended to provide high-level guidance for hardware for a MongoDB deployment. The specific configuration of your hardware will be dependent on your data, queries, performance SLA, and availability requirements.
Memory
As with most databases, MongoDB performs best when the working set (indexes and most frequently accessed data) fits in RAM. Sufficient RAM is the most important factor for instance selection; other optimizations may not significantly improve the performance of the system if there is insufficient RAM. When selecting which MongoDB Atlas instance size to use, opt for one that has sufficient RAM to hold the full working data set (or the appropriate subset if sharding).
If your working set exceeds the available RAM, consider using a larger instance type or adding additional shards to your system.
Storage
Using faster storage can increase database performance and latency consistency. Each node must be configured with sufficient storage for the full data set, or for the subset to be stored in a single shard. The storage speed and size can be set when picking the MongoDB Atlas instance during cluster creation or reconfiguration.
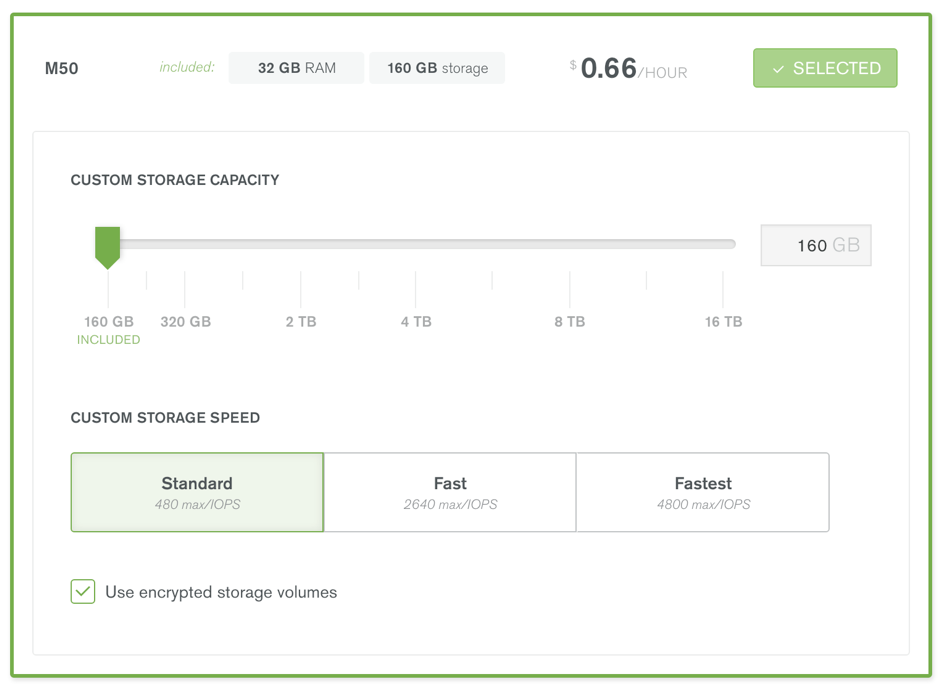
*Figure 3: Select instance size and storage size & speed*
Data volumes can optionally be encrypted which increases security at the expense of reduced performance.
CPU
MongoDB Atlas instances are multi-threaded and can take advantage of many CPU cores. Specifically, the total number of active threads (i.e., concurrent operations) relative to the number of CPUs can impact performance:
- Throughput increases as the number of concurrent active operations increases up to and beyond the number of CPUs
- Throughput eventually decreases as the number of concurrent active operations exceeds the number of CPUs by some threshold amount
The threshold amount depends on your application. You can determine the optimum number of concurrent active operations for your application by experimenting and measuring throughput.
The larger MongoDB Atlas instances include more virtual CPUs and so should be considered for highly concurrent workloads.
Next Steps
That’s a wrap for part 2 of the MongoDB Atlas best practices blog series. In Part 3, we’ll dive into scaling your MongoDB Atlas cluster, and achieving continuous availability