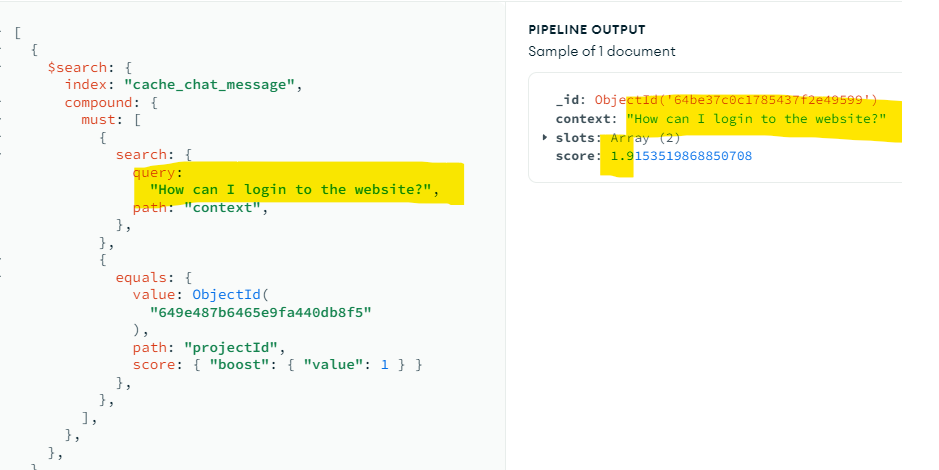
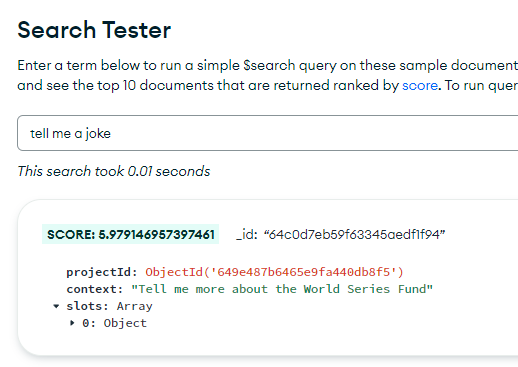
Hi, how can I set returned score to be not affected by length ? Not sure it is affected by search term or the value stored.
I’m trying to use AtlasSearch to do text similarity.
Then I use a score threshold to determine if the text is similar.
Is this the best way? Or should I use Text Index?
Here is my pipelines:
[
{
$search: {
index: "cache_chat_message",
compound: {
must: [
{
search: {
query:
"Help me choose a good fund",
path: "context",
},
},
{
equals: {
value: ObjectId(
"649e487b6465e9fa440db8f5"
),
path: "projectId",
score: { "boost": { "value": 1 } }
},
},
],
},
},
},
{
$project: {
_id: 1,
slots: 1,
context: 1,
score: {
$meta: "searchScore",
},
},
},
{
$limit:
/**
* Provide the number of documents to limit.
*/
2,
},
]
Attached example. If I change the query and context, the score will even though they are exact match, making it difficult to determine the similarity