Hello Everybody,
Last week, we talked about Realm Relationships and types and how they are implemented client-side (on mobile).
This week I will focus on Realm Sync and discuss the differences between Partition-based Sync and Flexible Sync. This will help you choose the best approach for syncing your mobile data to MongoDB Atlas.
Create your Cluster and Realm App
Please feel free to follow previous realm-bytes on understanding cluster configuration . After creating your cluster, you create a Realm App and link to cluster
Enabling Sync
There are two ways to enable Sync in your mobile application:
Generate Schema if you have data in Atlas
When you have data in Atlas already or can load it easily, Realm will generate your client data models for you. There is also a Sync guide available on your application Dashboard page. The guide explains how to configure your collections for Realm Sync
Turn Development Mode On
If you aren’t starting with data, Development Mode can be very useful for getting started quickly – it allows you to build your mobile app from scratch and sync your data to Atlas. Once you have finished creating your client data models, development mode can be turned off and it will lock in a backend schema based on the models that you’ve created.
Sync Types
There are two Sync Types: Flexible Sync and Partition Based.
Partition Based
Partition-based Sync allows you to choose a single field called a Partition Key across all collections to divide Atlas data into partitions based on the field’s value.
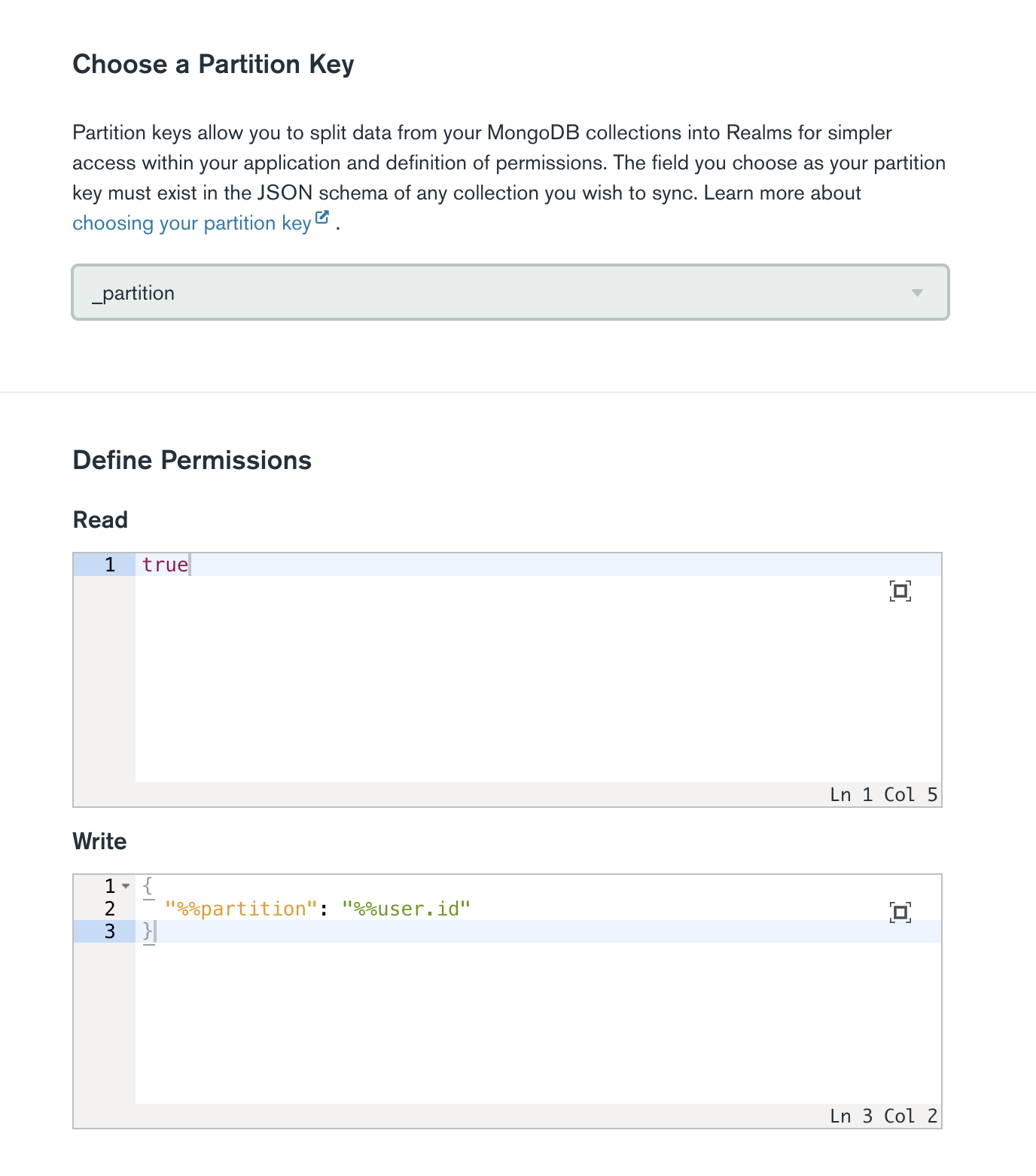
Partition Key
This plays an important role in partition-based Sync. If you have opted for “Generate Schema” in the previous step, you can choose one of the fields from your Schema to split the data across your MongoDB collections into partitions/Realms based on the value. If you opted for Development mode and you are creating your application from scratch, make sure to choose a field that either exists in your client application schema or you create a new one.
For complex use-cases, please refer Partitioning Strategies documentation
Sync Permissions
Sync permissions is another important concept. This can vary depending on your use-case. For example if I have to use the Book and Author model explained previously, I would want users to read all information but write in their own private realm. For different use-cases, check Sync Permissions and Rules documentation.
Please Note - When you have Sync enabled on your cluster. Sync Permissions will serve as the permissions for all requests in the application.
Below is a snapshot of a random key and permissions for Book Author Model
Flexible Sync
Flexible Sync is in preview but offers far more flexibility in data synchronization across devices and MongoDB Atlas.
Please Note: Flexible Sync requires MongoDB 5.0 and above
Flexible Sync uses subscriptions and permissions to determine which data to sync with your Realm App.
Some basic terminology used in Flexible Sync is explained below:
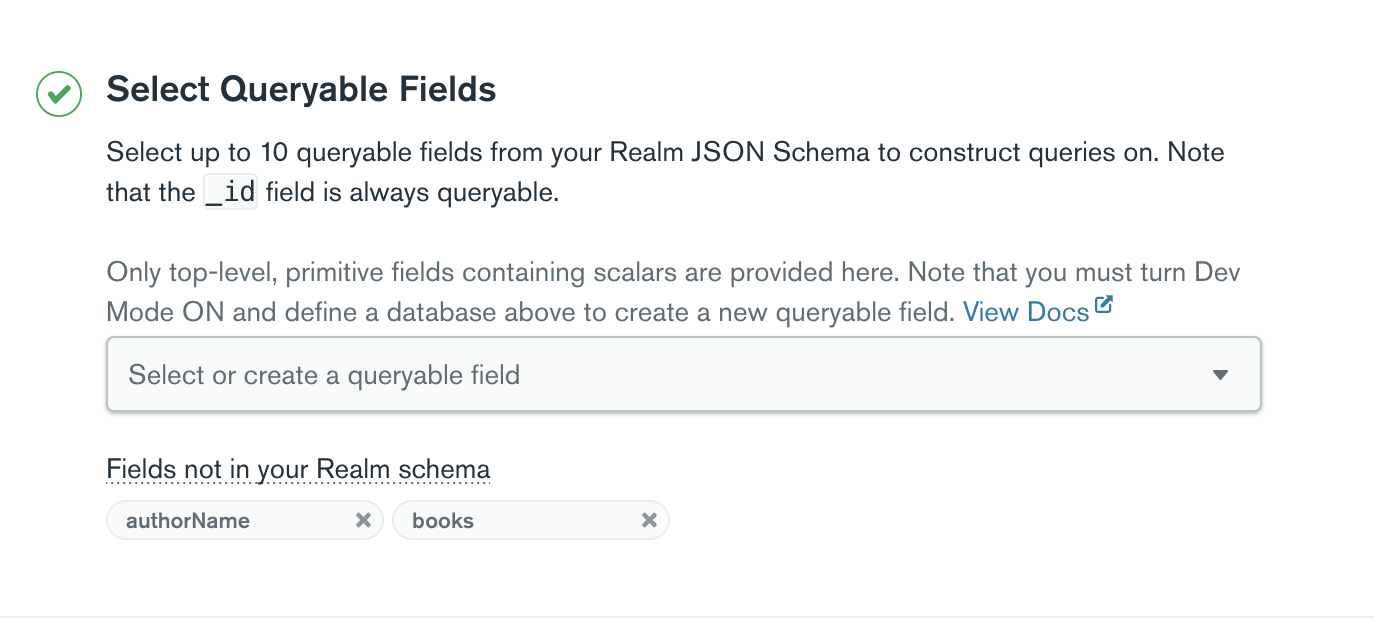
Queryable Fields
This refers to the fields in your client schema that your application can query. These queries will define the data that is synced down to your device and replace the concept of partitions. When you configure Flexible Sync on the backend, the field names are specified there. You can choose upto 10 queryable fields.
If you choose development mode, you can create fields that are part of your client schema. For example, for Book and Author model, I created the following queryable fields
Subscriptions
The query and its metadata are represented by a subscription. For flexible sync, it sends an RQL (Realm Query Language) query that the client app is trying to sync on in comparison to the partition key sent in the Partition-based Sync. Flexible Sync does not support all the operators available in RQL. See Flexible Sync RQL limitations for details.
Flexible Sync allows you to define a query in the client, and sync only the objects that match the query. When the client-side makes a query, Realm searches the server-side data set for documents matching the query.
The respective Realm SDKs provide a Subscription API to modify the queries. For example, if you are syncing on [author == “Rowling”] and [isRead ==true], you can remove the second query, add another one or update one of these, and the server will re-sync with the new data.
Rules and Permissions
Flexible Sync has a more powerful permission system and can be applied on a per-document level in comparison to partition-based permission systems that do not offer granular filtering.
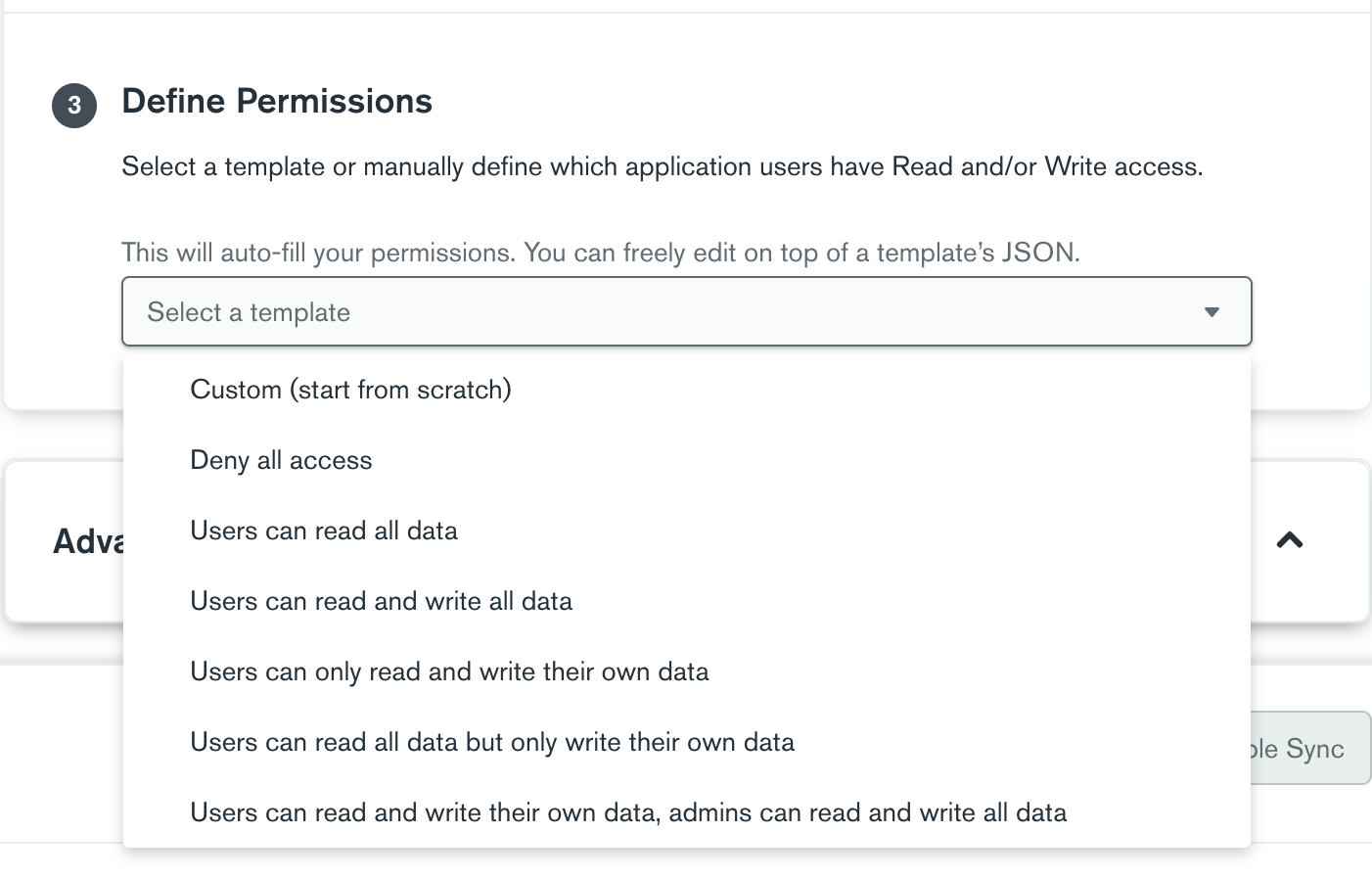
When you set up permissions on the backend, you can choose from a provided template or design your own permissions from scratch.
For the Book and Author model, I chose “Users can read all data but only write their own data” from the provided options below:
The JSON expression for the selected permission is as below and this will be applied to all collections in the database
{
"rules": {},
"defaultRoles": [
{
"name": "owner-write",
"applyWhen": {},
"read": true,
"write": {
"owner_id": "%%user.id"
}
}
]
}
If there is a requirement to apply more granular rules, those can be applied in the following way
{
defaultRoles: [],
rules: {
Author: [
{ name: "role1", applyWhen: { userId: "abc" }, read: true, write: { field1.user == %%user.id } },
{ name: "role2", applyWhen: true, read: true, write: { field1.user == %%user.id } },
]
}
}
To Note
- The order in which the roles are listed is important. The role that returns true (in apply when condition) is selected at connection time and persists for the entire session. Once the role is selected, the read/write permissions are used to evaluate permissions per document.
- If a collection has write permissions, then read is automatically true, even if “read” evaluates to false for a document.
- The queries can be thought of as logical “AND” of the client’s subscriptions and the read permissions for the role assigned to the client
Please refer to Flexible Sync Role Strategies for more information.
I hope the information provided is helpful. Please feel free to share your experience, thoughts of using Realm Sync Types and Modes.
Until next week…
Cheers ![]()