Dear @Jason_Tran, thanks for the update.
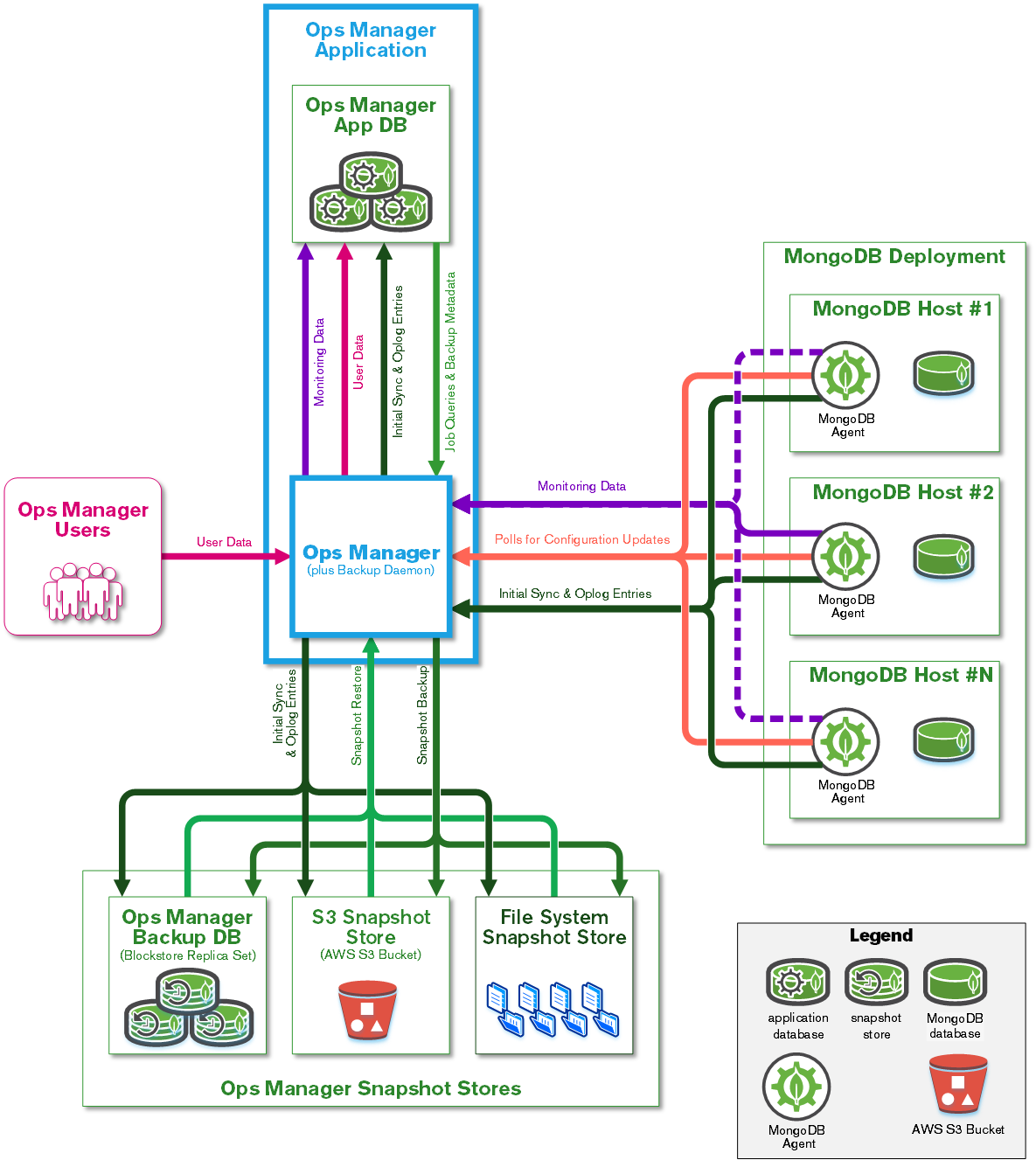
When I saw the architecture picture for OpsManager, I thought ops manager deployment was able to interact with external MongoDB clusters/deployments like we have in Atlas MongoDB service. Something like an intercommunication between existing clusters to maintain them, monitor them, and backing up them, without matter if those clusters already do exist previously to the ops manager deployment or are outside of its scope. I was wrong then.
With your information, and looking at the architecture picture, It seems then, MongoDB Ops Manager involves their own MongoDB database deployments with MongoDB agents beside them to allow this communication with Ops Manager to get their features, including backup daemon.
So if we want to involve an automated backup solution for mongo clusters (aka, mongo clusters intended as MongoDB deployments), then … do those clusters should be created within MongoOps Manager deployment context?
If so, then those mongo deployments will not have to do with atlas service, they will be indeed part of the MongoOps service deployment
I ask this because I am interacting with the Atlas MongoAPI right now to create restore jobs to allow me to download snapshots.
One solution I had in mind is to download these snapshots via API and store them somewhere, then upload them to an external storage like AWS S3 or Azure storage accounts.
This is an approach that I will need to be script it indeed to automated, and under a cloud-native solution perspective, I will have to think about doing it within a VM instance to store the snapshots and upload them after. Or perhaps a couple of containers to download them and store them in a PVC inside k8s and restore them if needed
The thing is I really need to do this via API and not using a mongodump / mongorestore approach since my data on atlas is growing and at some point, and I heard we can experience some performance problems since all data dumped via mongodump has to be read into memory by the MongoDB server and it backus the data and index definitions.
When connected to a MongoDB instance, mongodump can adversely affect mongod performance. If your data is larger than system memory, the queries will push the working set out of memory, causing page faults.
I found this on the mongodb docs
Another thing is since my atlas cluster has three replicaset nodes (1 primary and two secondaries) perhaps a mongodump / mongorestore approach against the secondary nodes could be something sustainable? I am not sure, since the data in the short term will be GB for every snapshot, and the memory ram is just 2gb. I wouldl have to scale the cluster (M10 plan actually)
So to sum up, Is mongo ops manager just useful when we raise a mongo deployment databases using MongoOps manager from the beginning right?