Dear Mongo community
I have a cluster on MongoDB atlas cloud service. It is deployed on azure cloud and I have enabled cloud backups in this way:
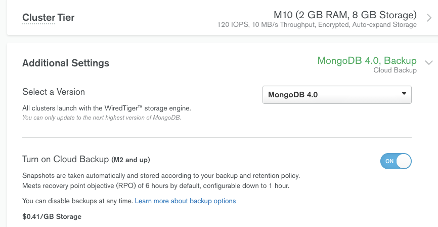
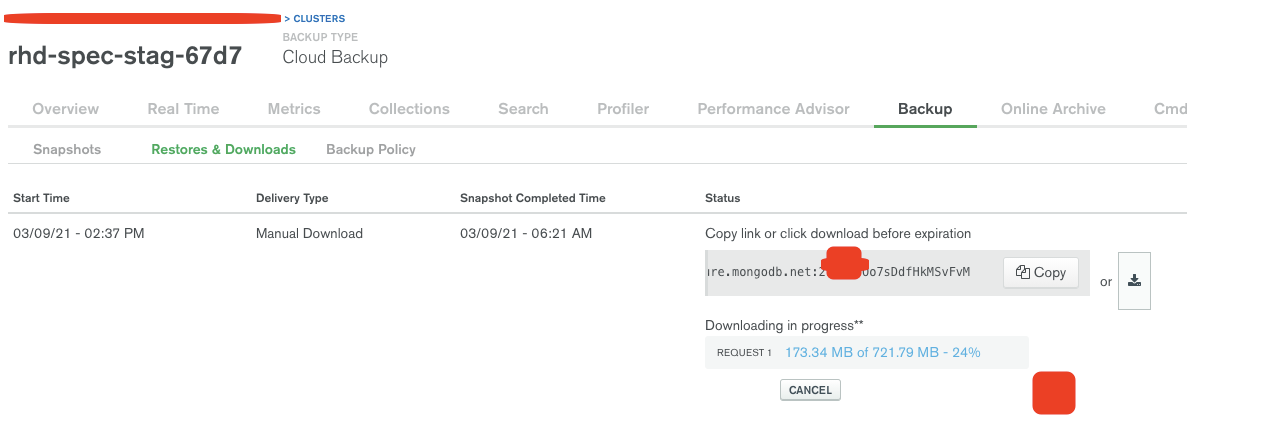
So my cluster is creating frequently snapshots. My objective is to move those snapshots outside the cluster scope since if for some reason the cluster is deleted, the snapshots will be removed as well.
I see we can upload mongodump’s or mongoexport’s to amazon s3 buckets, there are plenty of tutorials out there. In addition, I’ve realized, I don’t want to execute mongodump’s of my collections from a script, since the snapshots already do exists on cloud backup on atlas service.
I have been reading some documentation and I found several ways to try to move data to external storage but seems that using the mongo API to get the snapshots created and transfer them is a good option here. However, I got confused about which option to use:
-
I got this cloud manager, mongo documentation link to get the snapshots for one cluster but it seems it uses this endpoint:
https://cloud.mongodb.com/api/public/v1.0 -
And I found this atlas mongo documentation link to download the snapshots via API Resources but it uses this endpoint:
https://cloud.mongodb.com/api/atlas/v1.0
Both endpoints are completely different. Considering my cluster is on atlas service, any of them could works for me to interact with my cluster via API?
On the other hand, having said this, I am also wondering:
ok, by calling the APIs I can get all snapshots but is not clear for me if they are transported directly to AWS S3 buckets when a get/post and upload to s3 operations actions takes place.
So, can I transfer an existing snapshot from mongo to s3 without downloading it first?
Do we need to care about temporary storage in between along this process?
I mentioned this because once I am dealing with GB of data, will be reliable to trust in a direct transport from mongo to s3?
If so I am afraid a security private network link or service endpoint should be used to get the proper bandwidth for this operation transport Am I right here?
I am not entirely sure if is possible to avoid the downloading process, I would say not.
What is the best option to move my snapshots collections to an external storage service like s3 or azure storage accounts?