Hey Jan! How is it going?
I’m having the same issue 
I don’t have a solution for this apart of changing the database type or applying try and catches everywhere the database client fires a query - sad -. However, I wanted to share my thoughts in case somebody else faces the same issue.
In my case, our team is running a NodeJs container + Prisma.io ORM to handle the database work over a GCP Cloud Run instance too.
This issue arises very consistently when multiple queries hit the db serverless instance - around 3 read consecutive/parallel operations would trigger it fairly easily and consistently -, causing the same Broken pipe error you have found.
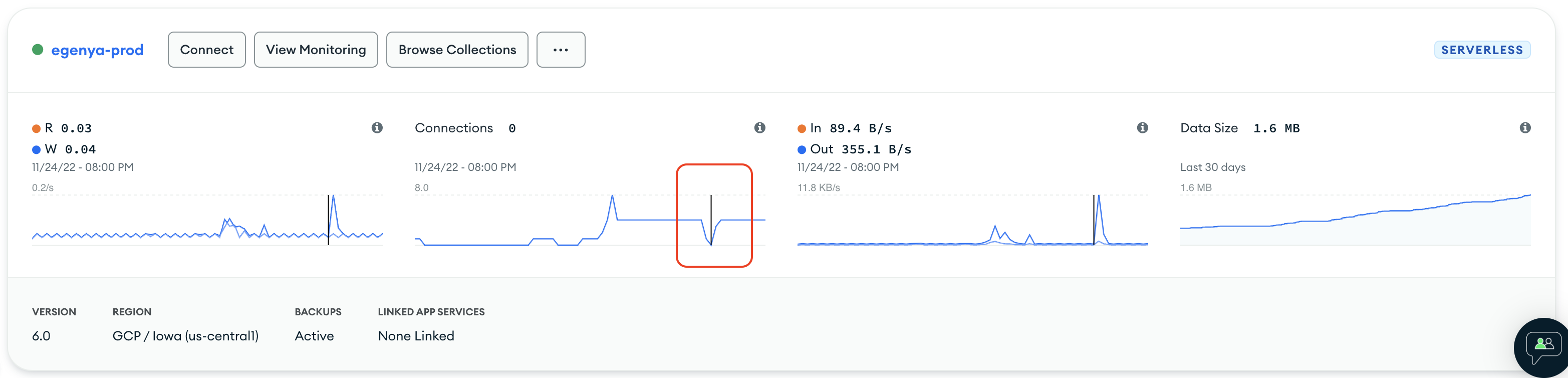
My hypothesis is that the issue lies on how serverless instances are handling connections and its consequent scaling/provisioning whenever a query tries to hit the db. Looking at the charts mongodb atlas provides, I found that that error matches a connection drop on the database side (see the snapshot attached).
This connection, of course, would have been closed by the db itself. Open thoughts:
1.- GCP Cloud Run runs containers, which means that connections pools would be set and used/reused as long as the container is active and running while using MongoClient. Not knowing what specifically triggers a mongodb serverless instantiation, leaves me thinking if those reused connections could be causing this if, for example, mongodb serverless expect 1 query = 1 connection.
2.- In my case, 3 queries are being fired, where the third one more often is the one that gets this Broken Pipe error. I wonder if queries 1 and 2 gets its own connection while the latter gets, let’s say, connection 1 reused and that could cause mongodb serverless to close the connection (e.g. 1 connection = 1 response and then closes).
3.- I haven’t found documentation on any of this nor options to configure the scaling behaviour of mongodb serverless instances. I’ve read that min connections could be set at the client side on this doc https://www.mongodb.com/docs/manual/reference/connection-string/#mongodb-urioption-urioption.minPoolSize
4.- Nevertheless, that’s an option for the client side and I don’t know if that could impact somehow the behaviour of mongodb serverless scaling (one way i think it could affect tho, is if the connections on the pool gets to 0 on the client for X ms while opening a new one and that somehow indicates mongodb serverless instance to scale down, dropping the connections and causing the consequent error)
It’d be nice to have someone form mongodb to give some light on these issues. I know that serverless instances are now in preview, so we’re aware stuff like this can happen.
In the meantime, to stays in the safe side, we’ve moved prod to a shared cluster, and it’s working like a charm.
Hope this helps get the discussion moving