In relational databases there are built-in features that are useful data modeling
Setting default values for null information when information is missing as a convention.
Persisted Calculated column that gets updated when any of the columns in the definition of the calculated change during an update, it recalculated by the engine.
Relational Trigger equivalent in MongoDB?
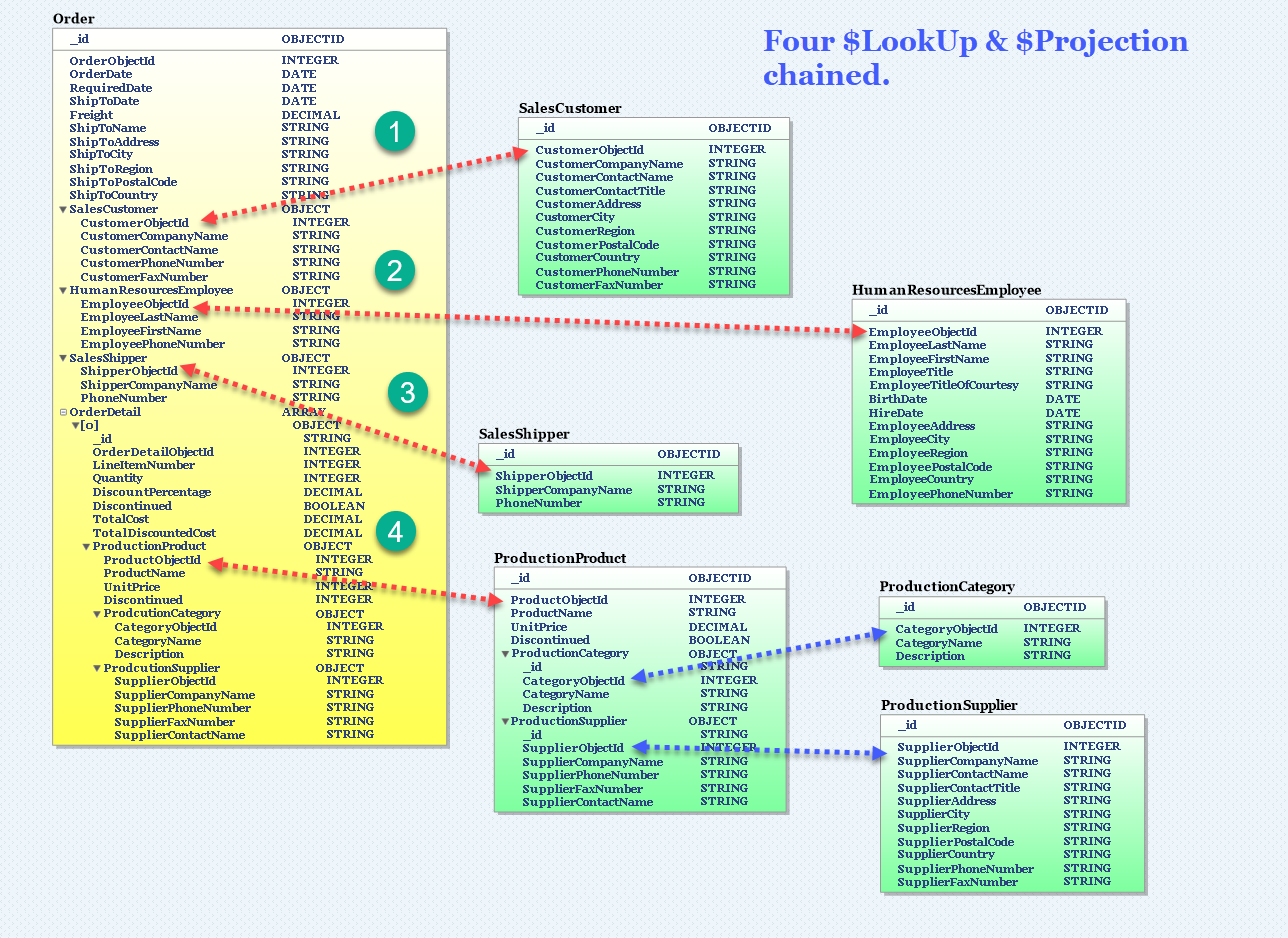
Mongodb pipeline aggregation (lookup + projection) chaining for embedding multiple subdocuments?
See image
Atlas Triggers for a pre-built solution using JavaScript functions or Change Streams for on-premise or alternative language support.
This schema seems rather normalised, but you could perform multiple $lookup stages starting from the Order collection. I would consider whether your typical use case needs to fetch all of the data for an order in a single aggregation or if you could denormalise some common fields and perhaps run a few separate queries to optimise retrieval efficiency.
In an ordering system context, I also expect details like unit price and supplier address should either be associated with a specific order or versioned. You would not want to retrospectively change some details for orders that have already been processed.
I recommend reviewing common patterns and anti-patterns to see what may be applicable to your use case:
If you want to get into further detail on specific aggregation pipelines, it would be best to start a new topic for each including more tangible details such as sample documents, your current aggregation pipeline and explain output, versions of driver and MongoDB server used, and any specific challenges you are encountering.
As a general principle (not specific to MongoDB), database queries will be more efficient if you minimise the amount of merging and transformation required to fetch results for common queries.
It from a TSQL database which was denormalized to embed subdocuments that were deemed necessary to create a transactional order with 1 or more detail lines. The green tables are lookup or maintenance tables that are the latest state of information which would pull the “cherry picked fields” necessary to be encapsulated in an order. Clearly, at the time of order I would lookup (the various "Collection"ObjectId from within the Order and the $Lookup & $Projection to pull in the appropriate data.
I will review your suggestions on common patterns and anti-patterns to see what may be applicable to my use case: