Day 41: What Are Microservices
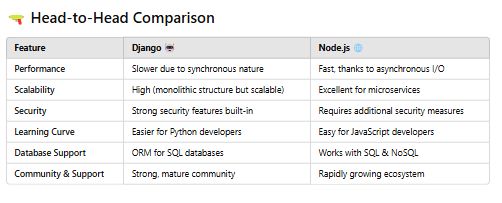
Microservices are an architectural style for building software applications that divide a large, monolithic application into smaller, independently deployable services. Each microservice focuses on a specific business function and communicates with other microservices through well-defined APIs (usually HTTP or messaging queues).
Here are the key characteristics of microservices:
- Independent Deployment: Each microservice is a standalone unit that can be developed, tested, deployed, and scaled independently. This makes it easier to maintain and update individual components without affecting the entire application.
- Focused on a Specific Function: A microservice is designed around a specific business capability (e.g., user authentication, payment processing, product catalog). This allows for better alignment with the organization’s needs and easier adaptation over time.
- Loose Coupling: Microservices are loosely coupled, meaning changes in one service have minimal impact on others. This promotes flexibility and ease of updates and scalability.
- Technology Diversity: Since microservices are independent, each service can be built using different technologies, frameworks, or programming languages, depending on the needs of that service. This allows teams to choose the best tool for each job.
- Scalability: Microservices can be scaled individually, meaning you can allocate more resources to a specific service (e.g., payment processing) without affecting other services. This improves overall system performance and efficiency.
- Resilience: If one microservice fails, it doesn’t bring down the entire system. This is often achieved through techniques like redundancy, failover mechanisms, and graceful degradation.
- Data Management: Microservices often manage their own database, reducing dependency on a single, centralized database. This enables each service to control its data model and structure, making it easier to manage and scale.
- Communication: Microservices communicate with each other through lightweight protocols like REST, gRPC, or messaging systems (e.g., Kafka, RabbitMQ). This ensures that services can share data and collaborate to perform more complex tasks.