Day 20: 4 Small Node.js API Projects to Kickstart Your Learning
If you’re diving into APIs with Node.js, building small projects is the best way to solidify your understanding. Here are four beginner-friendly projects that cover different aspects of API development, from handling requests to working with external libraries.
1. URL Shortener
What You’ll Learn: Express routing, database integration, and URL handling.
Create an API that shortens long URLs and redirects users when they access the short version. Use a database like MongoDB or a simple JSON file to store mappings between short and long URLs. This project helps you understand CRUD operations and URL handling in APIs.
2. Rate Limiter (Protection Against Cyber Attacks)
What You’ll Learn: Middleware, security, and request limiting.
Implement a rate limiter API that prevents excessive requests from a single IP address within a certain timeframe. Use libraries like express-rate-limit to control access and protect against brute-force attacks. This project introduces you to API security and middleware usage.
3. PDF Merger
What You’ll Learn: File handling, working with external libraries, and HTTP uploads.
Build an API that accepts multiple PDF files and merges them into one. Use libraries like pdf-lib or pdf-merger-js to combine files. This project teaches you how to handle file uploads and process documents on the backend.
4. YouTube Downloader
What You’ll Learn: Working with third-party APIs, streaming, and file downloads.
Develop an API that downloads YouTube videos as MP4 or MP3 files using ytdl-core . Users can provide a YouTube URL, and the API will return a downloadable file. This project gives you experience with external APIs, response streaming, and file handling.
Final Thoughts
Each of these projects introduces key API development concepts while keeping things manageable for beginners. Once you complete them, try adding authentication, caching, or deploying them online to gain more real-world experience. Happy coding!
Day 21: Unlocking the Power of Clustering Algorithms in E-Commerce
In the fast-paced world of e-commerce, understanding customer behavior is crucial for success. One powerful tool that helps businesses make sense of vast amounts of data is clustering algorithms—a type of machine learning that groups similar data points together. But how exactly does this work, and why is it important for online stores?
What Is a Clustering Algorithm?
Clustering is an unsupervised learning technique that automatically detects patterns in data by grouping similar items together. Popular clustering algorithms include K-Means, DBSCAN, and Hierarchical Clustering, each with unique strengths in handling different types of data.
How Clustering Improves E-Commerce
Customer Segmentation: By analyzing purchasing behavior, clustering can categorize customers into distinct groups—such as budget shoppers, luxury buyers, or frequent purchasers—allowing for personalized marketing strategies.
Product Recommendations: Clustering helps identify items often bought together, enhancing recommendation engines to suggest relevant products, increasing cross-selling and upselling opportunities.
Dynamic Pricing: By grouping customers based on purchasing power, stores can implement targeted pricing strategies to maximize sales and customer retention.
Fraud Detection: Clustering algorithms can detect unusual spending patterns, flagging potential fraudulent transactions for further review.
Inventory Management: Retailers can group products based on demand trends, ensuring optimal stock levels and reducing waste.
The Future of Clustering in E-Commerce
As artificial intelligence advances, clustering algorithms will become even more refined, enabling hyper-personalized shopping experiences and smarter business strategies. For e-commerce stores, leveraging clustering isn’t just an advantage—it’s a necessity in the age of data-driven retail.
Would you like a deeper dive into any of these applications?
Day 22: # Unlocking the Secrets of Node.js: How the Event Loop and Asynchronous Magic Power Modern Apps
Node.js, the JavaScript runtime that powers everything from startups to tech giants like Netflix and LinkedIn, is built on a foundation of asynchronous programming. But what makes it so fast and efficient? The answer lies in two key concepts: the Event Loop and Advanced Asynchronous Patterns. Let’s break down the science behind these powerful mechanisms.
1. The Event Loop: The Brain of Node.js
At the core of Node.js is the Event Loop, a single-threaded, non-blocking mechanism that allows it to handle thousands of simultaneous connections with ease. Here’s how it works:
The Phases of the Event Loop
The Event Loop operates in a series of phases, each responsible for specific tasks:
Timers: Executes callbacks scheduled by setTimeout and setInterval.
Pending Callbacks: Handles I/O callbacks deferred to the next loop iteration.
Poll: Retrieves new I/O events and executes their callbacks.
Check: Executes setImmediate callbacks.
Close Callbacks: Handles cleanup tasks, like closing sockets.
This cyclical process ensures that Node.js can juggle multiple tasks efficiently without getting bogged down.
Microtasks vs. Macrotasks
The Event Loop also distinguishes between microtasks (e.g., Promise callbacks) and macrotasks (e.g., setTimeout). Microtasks are executed immediately after the current operation, while macrotasks wait for the next cycle. This prioritization ensures that critical tasks are handled promptly.
The Danger of Blocking the Loop
While the Event Loop is powerful, it’s not invincible. Long-running synchronous code can block the loop, causing delays. To avoid this, developers use techniques like offloading tasks to worker threads or leveraging asynchronous APIs.
Node.js has evolved far beyond simple callback functions. Today, developers use advanced patterns to write cleaner, more efficient code. Here are some of the most powerful techniques:
Promises and Async/Await
Promises and async/await have revolutionized asynchronous programming in Node.js. Promises allow you to chain operations and handle errors gracefully, while async/await makes asynchronous code look and behave like synchronous code. For example:
This approach simplifies complex workflows and improves readability.
Event Emitters: The Power of Events
Node.js’s EventEmitter class enables event-driven programming, where actions trigger specific events. This pattern is ideal for building real-time applications like chat systems or live notifications. For example:
Streams are a cornerstone of Node.js, allowing you to process large datasets piece by piece without loading everything into memory. Whether you’re reading a file or processing real-time data, streams ensure optimal performance. For example:
javascript
Copy
const fs = require(‘fs’); const readStream = fs.createReadStream(‘largefile.txt’); readStream.on(‘data’, (chunk) => { console.log(Received ${chunk.length} bytes of data.); }); readStream.on(‘end’, () => { console.log(‘No more data to read.’); });
Why This Matters
Understanding the Event Loop and advanced asynchronous patterns isn’t just for experts—it’s essential for anyone building modern applications. These concepts enable Node.js to handle massive workloads, deliver real-time experiences, and scale effortlessly.
As the demand for faster, more responsive apps grows, mastering these techniques will be key to staying ahead in the world of software development.
What’s Next?
The world of Node.js is vast, and there’s always more to explore. From worker threads for parallel processing to N-API for building native addons, the possibilities are endless. Stay tuned for more insights into the science of Node.js!
This version is concise, engaging, and written in a style similar to Science Daily. Let me know if you’d like to tweak it further!v
Day 23: The Power of Small Projects: How Building a To-Do List Can Solidify Your Understanding of a New Tech Stack
When learning a new framework or technology stack, it’s tempting to dive headfirst into ambitious, large-scale projects. After all, isn’t that the best way to prove your skills? While big projects can be rewarding, they often come with a steep learning curve and can leave beginners overwhelmed. This is where small, focused projects—like building a to-do list application—come into play. Not only do they provide a manageable way to practice, but they also help solidify your understanding of how different components of a framework tie together. For those learning the MERN stack (MongoDB, Express.js, React, and Node.js), a to-do list is the perfect starting point.
Why Small Projects Matter
Small projects act as building blocks for your knowledge. They allow you to focus on specific concepts without the distraction of unnecessary complexity. For example, a to-do list app might seem simple, but it encapsulates many of the core concepts required to build larger applications. By working on such a project, you can break down the MERN stack into digestible pieces and understand how each part—routes, controllers, models, and front-end components—interacts with the others.
Breaking Down the MERN Stack with a To-Do List
Let’s take a closer look at how building a to-do list app can help you understand the MERN stack:
1. MongoDB: Understanding Data Models
In a to-do list app, you’ll need to store tasks, which might include fields like title, description, dueDate, and completed. This is a great opportunity to learn how to design a simple schema in MongoDB.
By working with MongoDB, you’ll understand how data is structured, how to perform CRUD (Create, Read, Update, Delete) operations, and how to connect your database to your backend using Mongoose (a popular MongoDB ODM for Node.js).
2. Express.js: Routing and Controllers
Express.js is the backbone of the backend in the MERN stack. A to-do list app requires basic routes like:
GET /tasks to fetch all tasks.
POST /tasks to create a new task.
PUT /tasks/:id to update a task.
DELETE /tasks/:id to delete a task.
By implementing these routes, you’ll learn how to structure your backend, handle HTTP requests, and connect routes to controllers. Controllers act as the middle layer between your routes and your database, helping you understand the separation of concerns in backend development.
3. React: Front-End Components and State Management
On the front end, React allows you to build a dynamic user interface. For a to-do list, you’ll create components like TaskList, TaskItem, and AddTaskForm.
You’ll also learn how to manage state using React’s useState or useReducer hooks. For example, when a user adds a new task, you’ll update the state to reflect the change and re-render the component.
This hands-on experience with React will help you understand how to structure components, pass props, and manage user interactions.
4. Node.js: Bringing It All Together
Node.js serves as the runtime environment for your backend. By building a to-do list app, you’ll learn how to set up a Node.js server, handle API requests, and connect your backend to your front end.
You’ll also gain experience with essential tools like npm or yarn for package management and nodemon for automatic server restarts during development.
How It All Ties Together
One of the most challenging aspects of learning a full-stack framework is understanding how the front end, backend, and database interact. A to-do list app provides a clear example of this interaction:
Front End (React): The user interacts with the app by adding, editing, or deleting tasks. These actions trigger API calls to the backend.
Back End (Express.js and Node.js): The backend receives the API requests, processes them (e.g., validating data), and interacts with the database to perform the necessary operations.
Database (MongoDB): The database stores the tasks and sends the requested data back to the backend, which then returns it to the front end.
By building this flow in a small project, you’ll see how data moves through the stack and how each layer depends on the others. This foundational knowledge is crucial before tackling more complex projects.
Conclusion
Before diving into large-scale projects, take the time to build small, focused applications like a to-do list. These projects serve as a practical way to solidify your understanding of the MERN stack and how its components—routes, controllers, models, and front-end logic—work together. By mastering the basics, you’ll be better equipped to tackle more ambitious projects in the future. Remember, every big project is just a collection of small, well-understood pieces working in harmony. Start small, build your knowledge, and watch your skills grow!
Day 24: Framing Your Software Engineering Portfolio as a Solution to Problems
In the competitive field of software engineering, standing out requires more than just showcasing technical skills. Reframing your portfolio as a collection of solutions to real-world problems can make a powerful impression. Employers and clients increasingly value engineers who understand and address user or business pain points, not just those who write code.
Why the Problem-Solution Approach Works
Presenting your projects as solutions shifts the focus from what you built to why it matters. For example, instead of saying, “I built a task management app,” say, “I created a task management app to help remote teams streamline collaboration and reduce missed deadlines.” This approach demonstrates your ability to solve problems and deliver impact.
How to Reframe Your Portfolio
Define the Problem
Clearly state the issue each project addresses. Was it inefficiency, poor user experience, or a lack of tools?
Highlight the Solution
Explain how your project solved the problem. Focus on outcomes, such as improved productivity or user satisfaction.
Showcase Results
Use metrics, testimonials, or visuals to demonstrate the impact of your work.
By framing your portfolio around problems and solutions, you position yourself as a problem-solver, not just a coder—making you a more compelling candidate for jobs, freelance gigs, or entrepreneurial ventures.
Day 26: Why MongoDB is the Future of Scalable Databases
As digital applications grow in complexity and scale, traditional relational databases struggle to keep up. Enter MongoDB—an innovative NoSQL database designed for flexibility, performance, and horizontal scalability.
The Power of Horizontal Scaling
Unlike traditional SQL databases that require vertical scaling (upgrading a single server), MongoDB distributes data across multiple machines through sharding. This means businesses can handle massive workloads by simply adding more servers—an approach used by tech giants like Netflix and eBay to maintain seamless performance.
Schema Flexibility for Modern Applications
MongoDB stores data in BSON (Binary JSON) format, allowing for a dynamic schema. This is particularly useful for AI-driven platforms, IoT, and real-time analytics, where data structures frequently change.
Performance Meets Reliability
With built-in replication and automatic failover, MongoDB ensures data redundancy and high availability. Even if one server fails, data remains accessible—making it a top choice for businesses that require 24/7 uptime.
How Much Does MongoDB Cost?
MongoDB is open-source, but hosting and scaling influence costs. Self-hosted setups require server investments (~$3,000–$5,000 upfront + maintenance). MongoDB Atlas (Cloud) starts free but scales with usage—small applications cost ~$50–$200/month, while enterprise solutions range from $5,000 to $50,000/month, depending on traffic and storage needs.
The Future of Data Management
From startups to enterprises, MongoDB’s ability to scale seamlessly while maintaining speed and reliability makes it a game-changer in database management. As businesses demand more flexibility and performance, MongoDB continues to lead the way.
Day 27: The Future of Web Development: How AI is Reshaping the Digital Landscape
Web development has always been a field defined by rapid evolution, but the rise of artificial intelligence (AI) is accelerating this transformation like never before. From automating repetitive tasks to enabling entirely new ways of building and interacting with websites, AI is poised to redefine how developers work and how users experience the web.
AI-Powered Development Tools
One of the most immediate impacts of AI on web development is the emergence of intelligent tools that streamline the coding process. Platforms like GitHub Copilot and ChatGPT are already helping developers write code faster by generating snippets, debugging errors, and even suggesting entire functions. These tools don’t replace developers—they empower them to focus on creativity and problem-solving rather than boilerplate code.
AI is also making web development more accessible. No-code and low-code platforms, powered by AI, allow non-developers to create functional websites and applications. Tools like Wix ADI and Framer AI use machine learning to design layouts, optimize user experiences, and even generate content, democratizing web development for a broader audience.
Smarter, More Personalized User Experiences
AI is revolutionizing the way users interact with websites. Chatbots and virtual assistants, powered by natural language processing (NLP), are becoming more sophisticated, offering real-time support and personalized recommendations. Meanwhile, AI-driven analytics tools are helping developers understand user behavior in unprecedented detail, enabling hyper-personalized experiences that adapt to individual preferences.
For example, e-commerce sites are leveraging AI to recommend products, optimize search results, and even predict trends. Streaming platforms use AI to curate content, while news websites tailor articles to readers’ interests. This level of personalization is setting a new standard for user engagement.
The Rise of AI-Generated Content
Content creation is another area where AI is making waves. Tools like OpenAI’s GPT-4 and Jasper AI are capable of generating high-quality text, from blog posts to product descriptions. For web developers, this means faster content updates and the ability to scale dynamic websites with ease. However, it also raises questions about authenticity and the role of human creativity in the digital space.
Challenges and Ethical Considerations
While the potential of AI in web development is immense, it’s not without challenges. Concerns about data privacy, algorithmic bias, and the ethical use of AI-generated content are growing. Developers must navigate these issues carefully, ensuring that AI is used responsibly and transparently.
Moreover, as AI tools become more prevalent, the role of web developers may shift. Rather than focusing solely on coding, developers will need to become adept at integrating AI systems, interpreting data, and designing ethical AI-driven experiences.
Where is Web Development Headed?
The integration of AI into web development is still in its early stages, but the trajectory is clear: the future of the web will be smarter, faster, and more personalized. Developers who embrace AI as a tool—rather than a threat—will be at the forefront of this transformation, shaping the next generation of digital experiences.
As AI continues to evolve, one thing is certain: the web will never be the same. Whether you’re a seasoned developer or just starting out, now is the time to explore how AI can enhance your work and redefine what’s possible on the web.
Day 25: ### My Journey from Overthinking to Confident Coding
Introduction
When I first started coding, I wasn’t just writing logic—I was overanalyzing every decision. Was I choosing the right variable name? Was my approach optimal? Would someone judge my code if they saw it? This cycle of overthinking slowed me down and made me feel like I wasn’t good enough.
But over time, I learned to break free from this pattern and code with confidence. In this post, I’ll share what held me back, how I overcame it, and practical steps you can take if you’re struggling with the same thing.
The Problem: Overthinking Everything
As a fresh graduate, I found myself stuck in these thought loops:
“Is my code clean enough?” Instead of focusing on functionality first, I obsessed over writing “perfect” code.
“What if this isn’t the most efficient solution?” I hesitated to move forward, fearing I wasn’t using the best approach.
“What will others think of my code?” Code reviews made me anxious, as I worried about being judged.
The result? I spent too much time second-guessing myself instead of actually coding and learning.
What Helped Me Gain Confidence
1. Writing First, Optimizing Later
I learned that getting a working solution first is more important than making it perfect from the start. Now, I follow this approach:
Write a basic version of the solution.
Test it and make sure it works.
Refactor and improve the code.
This shift helped me stop getting stuck in my own head and start making progress.
2. Accepting That Code is Iterative
I used to think great developers wrote perfect code on their first attempt. That’s a myth. Even the best engineers write, refactor, and improve over time. Once I embraced this, I stopped stressing over every line.
3. Learning to Take Feedback Positively
At first, I saw code reviews as a judgment of my abilities. But I realized that feedback is normal, even for senior developers. Instead of fearing it, I started seeing it as a way to grow.
4. Setting a Time Limit on Decisions
To stop myself from overanalyzing, I started setting small deadlines. For example:
“I’ll spend 30 minutes researching this approach, then I’ll implement the best option I find.”
This forced me to take action instead of endlessly overthinking.
5. Practicing More, Thinking Less
I found that the more I coded, the less I overthought. The best way to gain confidence was simply to build more projects, make mistakes, and learn from them.
Final Thoughts
Breaking free from overthinking didn’t happen overnight, but by focusing on progress over perfection, I became a more confident developer. If you struggle with the same thing, remember: Write first, optimize later. Code is meant to be improved over time. Feedback is your friend. Set time limits to avoid analysis paralysis. The more you code, the more confident you’ll become.
Have you ever struggled with overthinking in coding? Let’s talk in the comments!
Day 28: Unlocking the Digital World: A Closer Look at APIs
In today’s interconnected digital landscape, applications rarely operate in isolation. They communicate, exchange data, and enable seamless interactions—often without users even realizing it. At the heart of this connectivity lies a powerful yet often overlooked component: the API (Application Programming Interface).
APIs serve as digital bridges, allowing different software systems to interact. Whether it’s a mobile app fetching weather updates, an online store processing payments, or a social media platform sharing content, APIs make it all possible. These interfaces define the rules and protocols for communication, ensuring that systems can request and exchange data efficiently and reliably.
There are different types of APIs, each serving specific purposes. RESTful APIs, which rely on HTTP requests, are widely used for web applications, providing lightweight and scalable solutions. SOAP (Simple Object Access Protocol) APIs offer a more rigid, XML-based framework, often employed in enterprise environments requiring strict security. GraphQL, a relatively newer approach, enables clients to request only the data they need, optimizing performance and reducing unnecessary data transfer.
Beyond just connecting systems, APIs are catalysts for innovation. Businesses leverage APIs to integrate third-party services, enhance functionality, and create new digital experiences. Open APIs allow developers worldwide to build on existing platforms, fostering collaboration and technological growth. Companies like Google, Amazon, and Stripe have built entire ecosystems around APIs, empowering developers to create cutting-edge applications without reinventing the wheel.
However, API security remains a critical challenge. As these interfaces handle sensitive data, improper implementation can expose vulnerabilities. Encryption, authentication mechanisms, and rate limiting are essential safeguards against cyber threats. The rise of API security tools and best practices is helping organizations mitigate risks and ensure safe data exchanges.
From cloud computing to IoT devices and artificial intelligence integrations, APIs underpin modern technology. As businesses and developers continue to harness their potential, APIs will remain fundamental in shaping the digital future. As we move toward an increasingly interconnected world, APIs will be at the forefront, enabling smarter, faster, and more efficient digital interactions.
When I first learned React, props confused me. Everyone kept saying, “Props let you pass data from one component to another,” but that explanation felt too abstract. I needed something more visual—something that clicked.
Then, someone compared it to a manager delivering task notes.
Imagine you’re working in business. You have a manager who hands out notes to different employees, telling them what to do. These employees don’t decide their own tasks—they simply follow the instructions they receive.
In React, props work the same way:
The parent component (the manager) passes information (props) to the child component (the employee).
The child component can only read the props—it can’t change them.
This keeps everything organized and predictable, just like in a well-run business.
Once I saw props this way, everything made sense. Let me show you how this works with a simple To-Do List example.
Day 31: Mastering React: Understanding the useState Hook
If you’re starting with React or looking to strengthen your frontend development skills, understanding the useState hook is essential. It’s one of the most commonly used hooks that empowers developers to add state to functional components, making React applications more interactive and dynamic.
What is useState?
In React, state is used to manage data that can change over time. The useState hook allows you to add state to functional components, enabling them to “remember” values between renders. Whether you’re building a counter, form inputs, or toggles, useState is the go-to hook for managing component-level state.
How Does It Work?
When you call useState, it returns an array containing:
The current state value – This is the data you want to track.
A function to update the state – This function lets you modify the state value and triggers a re-render of the component.
The basic syntax looks like this:
js
CopyEdit
const [state, setState] = useState(initialValue);
state: Holds the current value.
setState: Function to update the state.
initialValue: The initial state value, which can be any data type (string, number, array, object, etc.).
Example: Building a Simple Counter
Let’s see how useState works with a basic example of a counter component:
The useEffect hook in React is a fundamental feature that allows you to perform side effects in function components. Side effects include operations like data fetching, subscriptions, or manually changing the DOM. Prior to hooks, such operations were handled in class component lifecycle methods such as componentDidMount, componentDidUpdate, and componentWillUnmount. The useEffect hook consolidates these functionalities into a single API, simplifying component logic.
Basic Usage:
javascript
CopyEdit
import { useEffect } from 'react';
function MyComponent() {
useEffect(() => {
// Code to run on component mount
return () => {
// Cleanup code to run on component unmount
};
}, [dependencies]);
}
The first argument is a function containing the side effect code.
The optional second argument is an array of dependencies.
If provided, the effect runs after the initial render and whenever any dependency changes.
If omitted, the effect runs after every render.
If an empty array is provided, the effect runs only once after the initial render.
Example: Fetching Data
javascript
CopyEdit
import { useState, useEffect } from 'react';
function DataFetcher() {
const [data, setData] = useState(null);
useEffect(() => {
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => setData(data))
.catch(error => console.error('Error fetching data:', error));
}, []); // Empty array means this effect runs once after the initial render
if (!data) {
return <div>Loading...</div>;
}
return <div>Data: {JSON.stringify(data)}</div>;
}
In this example, useEffect fetches data from an API when the component mounts and updates the state with the fetched data.
Cleanup Function:
The function returned from the effect callback serves as a cleanup function, which React calls when the component unmounts or before the effect runs again. This is useful for tasks like unsubscribing from services or clearing timers.
javascript
CopyEdit
useEffect(() => {
const timer = setInterval(() => {
console.log('Timer running');
}, 1000);
return () => {
clearInterval(timer);
console.log('Timer cleaned up');
};
}, []); // Empty array means this effect runs once after the initial render
In this example, a timer is set up when the component mounts, and the cleanup function clears the timer when the component unmounts.
For a more in-depth explanation and additional examples, you can refer to the official React documentation on the useEffect hook.
Day 33: The Importance of Efficient API Calls: Returning Only the Necessary Data
In modern web development, APIs are the backbone of communication between the frontend and backend. As applications grow and become more complex, optimizing API calls becomes increasingly important to ensure performance, security, and scalability. One common mistake that developers make is allowing the frontend to cherry-pick the data it needs from the API response. While this approach may seem flexible and easy to implement, it often leads to unnecessary overhead, poor performance, and increased complexity.
Why Returning Only Needed Data Matters
When building an API, one of the key principles to keep in mind is data minimization—return only the data that is required for the specific use case. Let’s dive into the reasons why this approach is crucial for a successful application:
Improved Performance
Imagine your API returns a large dataset with lots of extra fields that the frontend doesn’t actually need. The browser will have to download, parse, and process all that extra data. This leads to slower load times, more data transferred over the network, and a less responsive application.
By returning only the data that the frontend needs, you reduce the payload size, leading to faster API responses and quicker rendering of your application. The smaller the data, the faster the user experience, especially on mobile networks or slower devices.
Reduced Server Load and Cost
Every API request consumes server resources—whether it’s CPU, memory, or bandwidth. If you allow the frontend to cherry-pick data, it might request more information than necessary, causing your server to do more work than required. This extra load translates to increased server costs, especially when dealing with large-scale applications that handle thousands or millions of requests.
By streamlining your API to deliver only what’s needed, you help reduce unnecessary server load, which in turn can lower operating costs, improve scalability, and ensure your system runs smoothly.
Better Security
Allowing the frontend to cherry-pick data can inadvertently expose sensitive information. For example, if your API returns all user details, but only the username and email are needed, the frontend might unintentionally access and display private fields like passwords or security questions.
By carefully structuring your API to return only the relevant data, you ensure that sensitive or unnecessary information never reaches the client side, reducing the risk of data breaches or unintended leaks.
Simplified Maintenance
APIs that return unnecessary data are harder to maintain over time. As your backend and frontend evolve, keeping track of which fields are used in the frontend and which are not can become a complex task. Over time, unused data fields can accumulate, making the API more difficult to manage.
By returning only the data that’s needed, you make it easier to update, test, and maintain your API. A simpler, leaner API is always easier to manage than one that includes irrelevant fields and overcomplicated logic.
Avoiding Client-Side Complexity
If your frontend has to cherry-pick what it needs from a large dataset, you introduce unnecessary complexity in your client-side code. This can lead to extra logic for filtering, transforming, or processing data before it’s displayed to the user. This not only bloats the frontend code but also introduces more room for bugs or inconsistencies.
By having the backend return only the necessary data, you offload this responsibility to the server, keeping the frontend code clean, simple, and focused on presentation and user interaction.
Best Practices for Optimizing API Calls
So how can we implement the practice of returning only the necessary data in our API? Here are some best practices to keep in mind:
Use Query Parameters for Filtering: If a resource can be filtered or customized, allow clients to specify exactly what data they need using query parameters. For example:
GET /users?fields=username,email
This allows the frontend to specify the exact fields it wants, without burdening the server with returning unnecessary data.
Leverage API Endpoints for Specific Needs: Instead of building a generic, one-size-fits-all API endpoint, create separate endpoints for different use cases. For example:
/users for general user data
/users/profile for a user’s profile info
/users/summary for a quick overview of user details This way, each endpoint only returns the relevant data for the specific request.
Use GraphQL for Fine-Grained Control: If you need flexibility, consider using GraphQL, which allows clients to request exactly the fields they need. This can help prevent over-fetching and under-fetching data, giving your frontend complete control over the response structure.
Document Your API Efficiently: Ensure that your API documentation clearly defines what data is available and how to request it. If your API supports filtering or selecting specific fields, make sure to document it so that frontend developers know exactly what to expect.
Implement Data Caching: If your data doesn’t change frequently, consider implementing caching mechanisms (like HTTP caching or server-side caching) to reduce the load on your API and improve performance further.
Day 34: Know What to Cache: A Key to Optimized Web Performance
Caching is one of the best ways to speed up your website, but the trick lies in knowing what to cache. When used wisely, caching can save you from unnecessary database hits and repeated computations, improving overall performance. Here’s how to decide what to cache for optimal results.
Static Assets (CSS, JS, Images)
These files don’t change often, so caching them can provide a significant performance boost. By storing these assets locally or using a CDN (Content Delivery Network), your website can load faster and reduce the load on your server.
Images, stylesheets, and scripts are prime candidates for caching since they’re requested frequently but rarely updated.
2. Frequently Accessed Data
Think about data that your users often request, like:
Product listings on eCommerce sites.
Search results or user profiles in social media applications.
API responses that don’t change often, such as weather data or popular blog posts.
By caching this information, you can quickly serve users without having to repeatedly fetch it from a database or an external service.
HTML Pages (For Static Content)
If your website has content that doesn’t change often, like blog posts or news articles, caching full HTML pages can dramatically reduce page load times. For example, caching the home page or a category page where product listings are static for a few hours can save both database queries and time.
Avoid Caching Dynamic or Sensitive Data
While caching can be a powerful tool, there are things you should not cache:
User-specific data: This includes login credentials, shopping cart contents, or personal messages.
Real-time data: Live events like stock prices or social media feeds need to be refreshed regularly, so they shouldn’t be cached for long.
Caching sensitive information could expose private data to other users, and caching highly dynamic content could result in users seeing outdated or incorrect information.
How to Choose What to Cache?
Frequency of Access: If data is accessed regularly but doesn’t change often, it’s a good candidate for caching.
Size: Avoid caching large datasets that may take up unnecessary storage space.
Change Frequency: If the data changes frequently or depends on the user’s session, consider not caching it or setting a very short cache expiry time.
By understanding what to cache, you can dramatically improve your website’s speed and scalability. Caching doesn’t just save time — it also reduces strain on your servers, allowing for more efficient use of resources.
Stay tuned for the next blog where we’ll dive into setting proper expiry times to make sure your cached data remains relevant!
Day 36: A Comprehensive Guide to Indexing in MongoDB
MongoDB is one of the most popular NoSQL databases, known for its flexibility, scalability, and ease of use. However, as your application grows, so does the volume of data, which can lead to slower query performance. This is where indexing comes into play.
Indexes in MongoDB are special data structures that store a small portion of the data set in an easy-to-traverse form. They significantly enhance query performance by reducing the amount of data MongoDB needs to scan. In this blog, we’ll explore the different types of indexes, how to create and manage them, and best practices to keep your MongoDB queries blazing fast.
Why Indexing Matters
Imagine searching for a word in a book without an index. You’d have to go through every page until you find the word. Similarly, without indexes, MongoDB must scan every document in a collection to fulfill a query, leading to slower performance. Indexes help MongoDB quickly locate documents, minimizing the number of scanned documents.
Types of Indexes in MongoDB
MongoDB offers a variety of indexes to accommodate different use cases:
1. Single Field Index
This is the most basic type of index, created on a single field. It speeds up queries that filter or sort by that specific field.
db.collection.createIndex({ fieldName: 1 })
The 1 denotes ascending order, while -1 denotes descending order.
2. Compound Index
Compound indexes are created on multiple fields, which is beneficial for queries that filter using more than one field.
In a groundbreaking announcement, Microsoft has unveiled the Majorana 1 chip, a quantum processing unit (QPU) that leverages a newly discovered state of matter known as topological superconductivity. This advancement marks a significant milestone in the quest for practical and scalable quantum computing.
Understanding Topological Superconductivity
Traditional quantum computing relies on qubits—quantum bits that can exist in multiple states simultaneously. However, qubits are highly susceptible to errors due to their sensitivity to environmental disturbances. Topological superconductivity offers a promising solution by creating qubits that are inherently more stable and resistant to such errors. This stability arises from the unique properties of topological materials, which are less affected by local disturbances.
The Majorana 1 Chip: A Leap Forward
Microsoft’s Majorana 1 chip is the first QPU to utilize a topological core architecture. By incorporating topoconductors—a class of materials that enable topological superconductivity—the chip aims to achieve higher qubit stability and scalability. This innovation could potentially allow for the integration of up to a million qubits on a single chip, a feat that would significantly enhance computational power and efficiency.
The development of the Majorana 1 chip could accelerate the timeline for achieving commercially viable quantum computers. Microsoft envisions that this breakthrough will enable the creation of practical quantum computers within years, not decades. Such advancements have the potential to revolutionize various fields, including drug discovery, materials science, and complex system simulations.
While the Majorana 1 chip represents a significant step forward, experts advise cautious optimism. The scalability and practical implementation of topological qubits remain subjects of ongoing research. Further experiments and validations are necessary to confirm the chip’s capabilities and to address the challenges associated with scaling up quantum systems.
In conclusion, Microsoft’s unveiling of the Majorana 1 chip signifies a pivotal moment in quantum computing. By harnessing the unique properties of topological superconductivity, this innovation brings us closer to realizing the full potential of quantum technologies.
Day 37: How Quantum Algorithms Could Disrupt Cryptography
Quantum computers have the potential to upend modern cryptography, thanks to their ability to process information in fundamentally different ways. At the heart of this disruption is Shor’s algorithm, which can efficiently factor large numbers—a task that classical computers struggle with. Since most encryption systems, including RSA, Diffie-Hellman, and ECC (Elliptic Curve Cryptography), rely on the difficulty of factoring or discrete logarithms, a sufficiently powerful quantum computer could render them obsolete.
If Shor’s algorithm were to crack encryption, secure communications across the internet—including banking transactions, government secrets, and private messages—could be exposed. Passwords protected by encrypted hashes could also be reversed, leaving vast amounts of personal and corporate data vulnerable to attacks.
To counter this, researchers are racing to develop post-quantum cryptography—new encryption methods that remain secure even against quantum attacks. Some promising approaches include lattice-based cryptography, which relies on mathematical problems that remain hard for quantum computers, and hash-based signatures, which do not depend on factorization or discrete logarithms.
While large-scale quantum computers capable of running Shor’s algorithm effectively are not yet a reality, the cryptographic community is already preparing for a post-quantum world, ensuring that security measures evolve before quantum threats become practical.
Day 38: Why Every Aspiring Developer Should Build an eCommerce Platform
In the world of software development, not all projects are created equal. Some teach syntax, some focus on algorithms, but few provide the full-stack experience that an eCommerce platform does. Whether you’re a beginner looking to level up or an aspiring entrepreneur, building an eCommerce platform is a powerful way to strengthen your technical skills and problem-solving mindset.
1. Full-Stack Development in Action
An eCommerce platform isn’t just a frontend project or a backend API—it’s both. You’ll work with: Frontend (React, Next.js, or Vue) for the UI Backend (Node.js, Django, or .NET) for handling business logic Database (MongoDB, PostgreSQL) for product and user management Authentication & Security (OAuth, JWT) for user sign-ins Payments & Transactions (Stripe, PayPal) to process orders
This project forces you to think beyond code—you’re designing an entire system that interacts with real users.
2. Real-World Problem Solving
An eCommerce platform isn’t just a website; it’s a digital storefront that deals with inventory management, checkout flows, order processing, and customer authentication. Handling these complexities teaches you to:
Optimize database queries for fast product retrieval
Implement secure payment handling
Design intuitive user experiences
3. Understanding Business & Scalability
Developers often focus solely on code, but an eCommerce project introduces business logic. You’ll think about:
How to optimize conversions through UI/UX
Handling high traffic loads and performance tuning
Managing inventory efficiently with dynamic filtering and metadata
4. Portfolio-Worthy & Monetizable
If you’re job hunting, an eCommerce project is an eye-catching portfolio piece. It demonstrates skills in API development, security best practices, and working with third-party services. Plus, who says you can’t monetize it? Build a niche store and launch it!
Final Thoughts
Building an eCommerce platform is more than just another coding exercise—it’s a complete software development journey. Whether you plan to work at a tech startup, freelance, or build your own business, this project will give you hands-on experience with real-world challenges.
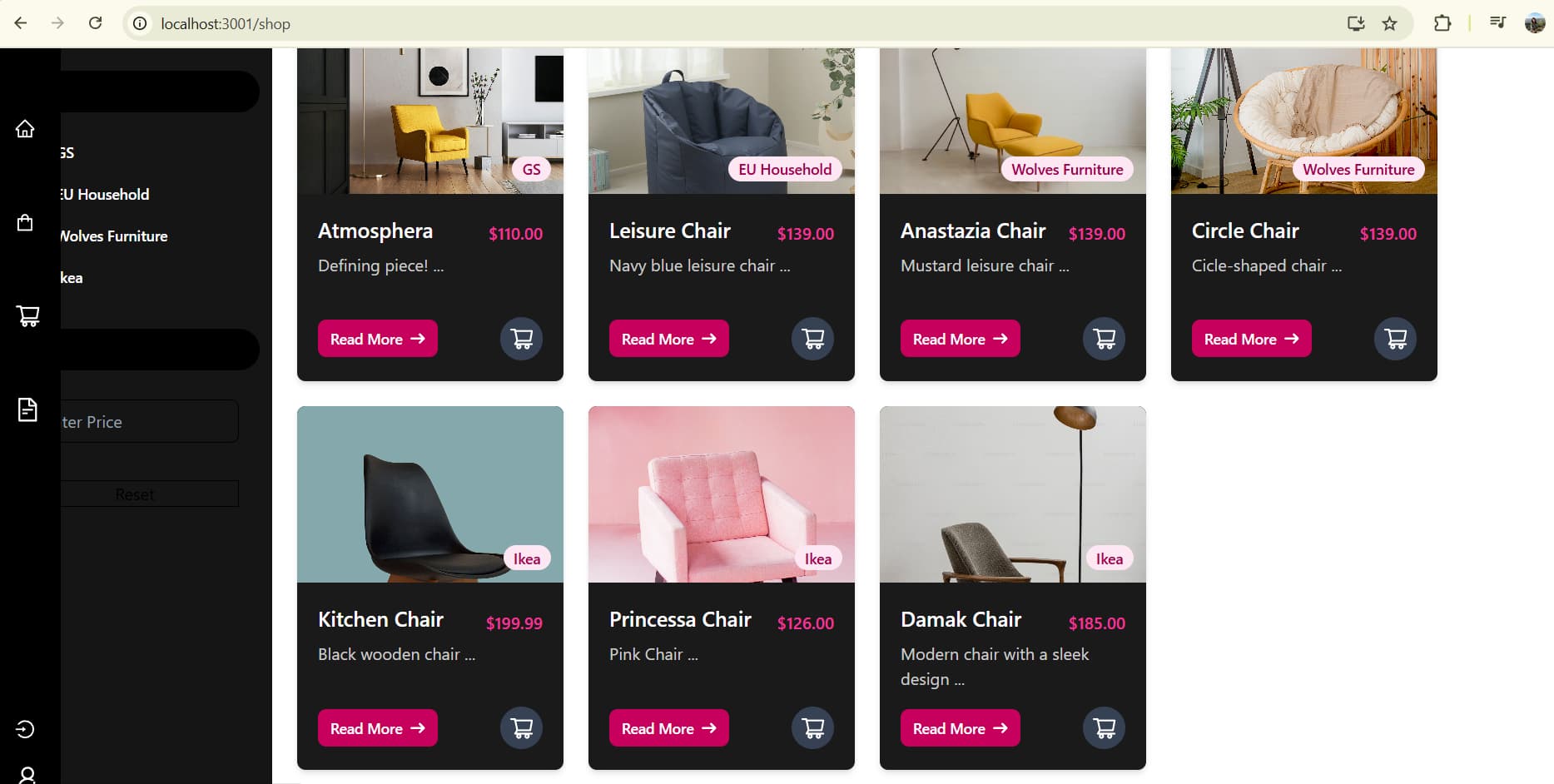
Day 39: The Hidden Pitfalls of Cart Testing in E-commerce
When building an eCommerce platform, it’s easy to assume that if a simple cart action works, the entire cart system is bug-free. I learned the hard way while working on my latest project, Sheldon’s Spot, a furniture store, that cart testing requires thinking beyond the obvious.
The Bug That Went Unnoticed
Initially, adding a single product to the cart worked perfectly—no issues. But when I tested a more complex scenario, I uncovered a serious bug:
Adding a single product worked fine.
Adding the maximum inventory of a product with a bundle that included the same product caused a negative inventory issue.
Re-ordering a previous order resulted in the same bug.
At first, it seemed like an isolated case, but in reality, it pointed to a fundamental flaw in how inventory was being deducted.
Why This Happened
Inventory Deduction Logic Was Too Linear
The system correctly deducted stock when an item was added individually.
However, it didn’t account for bundles that included the same product, leading to an excess deduction.
Re-ordering Didn’t Account for Inventory Checks
When a customer reordered a past purchase, the system didn’t validate stock levels, assuming that the previous order’s data was still valid.
Edge Cases Were Overlooked
Standard cart flows were tested, but combinations of actions (bundles, max stock, and reorders) weren’t rigorously checked.
Concurrency Issues Were Ignored
When multiple users attempted to add the same product simultaneously, the system failed to properly synchronize inventory updates, causing discrepancies.
The Key Lesson: Think in Scenarios, Not Steps
One of the biggest takeaways from this experience is that just because a simple action works doesn’t mean the system is reliable. Testing should not be limited to basic workflows but should cover edge cases, dependencies, and real-world usage patterns.
How to Approach Cart Testing More Effectively
Map Out All Possible User Actions
Add single items
Add max inventory
Combine products with bundles
Reorder past purchases
Apply discounts or promotions
Modify cart contents mid-checkout
Simulate High-Load Scenarios
What happens if multiple users order at the same time?
Does the system handle concurrent stock updates correctly?
Are API rate limits or performance bottlenecks being hit?
Test Inventory Deduction in Multiple Contexts
Ensure that individual and bundled purchases deduct stock correctly.
Reordering should trigger a fresh stock validation.
Test edge cases where stock levels fluctuate dynamically.
Check for Negative Stock Values
Any scenario that results in negative inventory is a red flag that needs immediate fixing.
Automate Testing for Edge Cases
Implement automated tests for scenarios like maximum cart capacity, bundle purchases, and past order reordering.
Introduce stress tests to see how the system behaves under a heavy load.
Review Data Consistency Across Systems
Ensure that stock updates are reflected accurately across databases, caching layers, and external warehouse management systems.
Conclusion
What seemed like a minor issue—negative inventory—revealed a major flaw in the logic behind inventory handling. The biggest mistake in cart testing is assuming it works just because a simple test passed. Instead, think holistically about how users interact with the cart and anticipate every possible scenario.
E-commerce testing isn’t just about functionality—it’s about preventing real-world failures before customers experience them. By expanding test cases and covering complex interactions, we can ensure a seamless shopping experience and avoid costly inventory mishaps.
The next time you test an eCommerce cart, remember: a working cart is not necessarily a reliable cart. Take the time to break it in creative ways before your customers do.
Day 40: Automating Invoice Generation from WhatsApp Orders: A Technical Deep Dive
For businesses using WhatsApp as a primary channel for customer orders, manually processing these orders into invoices can be time-consuming and error-prone. However, with advancements in automation tools, it’s now possible to transform text-based orders on WhatsApp into detailed invoices without requiring customer support intervention. In this article, we’ll take a deep dive into the technical workings of these automation apps, using WaBill as an example, to understand how they seamlessly convert WhatsApp orders into invoices.
1. WhatsApp Business API Integration
The core functionality of any app that automates WhatsApp orders into invoices begins with integrating with the WhatsApp Business API. The WhatsApp Business API allows businesses to connect to WhatsApp programmatically, enabling them to send and receive messages at scale. This is particularly useful for businesses with high volumes of orders.
In the case of WaBill, the app uses this API to listen for incoming orders sent via WhatsApp. When a customer sends a message, the API captures that message and feeds it into the app’s backend for further processing.
How it works:
Message Parsing: WaBill connects to the WhatsApp Business API, receiving all incoming order data as text. Using a combination of natural language processing (NLP) and regex (regular expressions), the app parses the message to extract key pieces of information: product names, quantities, prices, and customer details.
Webhook Handling: When an order message is received, a webhook triggers the app’s internal systems to process the order. Webhooks are real-time HTTP callbacks that let the app instantly react to new data or changes—like a new order arriving.
2. Text Parsing and Order Extraction
Once the order data is captured from WhatsApp, the next step is parsing the message to identify and extract relevant details. Since WhatsApp orders are typically sent as text, the app needs to identify structured data within unstructured messages.
This is where the combination of NLP and regex becomes crucial. For instance, a typical order message might look like:
bash
CopyEdit
"Hi, I want to order 2 T-shirts (Red) and 1 Cap (Black). Total cost: $30."
The app needs to extract:
Product Names: “T-shirt”, “Cap”
Quantities: 2, 1
Colors: Red, Black
Total Price: $30
NLP in Action:
Natural Language Processing (NLP) allows the app to understand and extract data from free-form text. For example:
Entity Recognition: The system can identify “T-shirt” and “Cap” as product names, while “Red” and “Black” are tagged as product attributes (color).
Pattern Matching with Regex: Regular expressions help identify numeric data like quantities (2, 1) and prices ($30), as these elements usually follow a predictable structure within the text.
WaBill uses NLP libraries (such as spaCy or TensorFlow for machine learning) and regex to process incoming text orders in real-time, even when the order messages are not strictly formatted.
3. Invoice Template Generation
After extracting the necessary order information, the next step is generating an invoice. WaBill offers the capability to create customizable invoice templates, which are filled dynamically with the order data.
The invoice generation process involves:
Template Population: Using the extracted data (product names, quantities, prices), WaBill populates a predefined invoice template, which can be customized by businesses with their logo, terms, and conditions.
PDF Creation: After filling the template with order information, the app uses libraries such as PDFKit or jsPDF to generate a PDF invoice. These libraries provide an easy way to convert HTML data into a structured PDF document, ensuring the invoice looks professional.
Template Structure:
The invoice template might include the following fields:
Customer Details: Name, address, and contact information.
Order Details: List of products, their quantities, individual prices, and the total price.
Business Information: Company name, logo, tax identification number, and payment instructions.
By leveraging HTML-to-PDF conversion, businesses can create rich, well-designed invoices, reducing manual effort and ensuring consistency in the invoicing process.
4. Automated Invoice Delivery
Once the invoice is generated, the app needs to send it back to the customer without human intervention. WaBill automates this by using the WhatsApp Business API once again to send the invoice PDF back to the customer.
Delivery Process:
Message Formatting: The app formats a message like, “Thank you for your order! Your invoice is attached.”
Sending the Invoice: The app uses WhatsApp API’s media endpoint to send the generated PDF invoice as an attachment to the customer’s WhatsApp number.
With the integration of Twilio or MessageBird (common services for WhatsApp API communication), the app can reliably send invoices instantly, allowing for a seamless customer experience.
5. Real-Time Notifications and Updates
In addition to sending the invoice, the app can also notify customers about the status of their order. For example, WaBill can send a message when the order is processed, shipped, or ready for pickup.
These notifications are triggered by the app’s internal logic, which can integrate with backend systems like order management platforms, inventory tools, or CRM software. With real-time messaging, customers are kept informed throughout the order lifecycle without the need for customer support intervention.
6. Security and Compliance
For businesses dealing with sensitive customer data, security and compliance are paramount. WaBill ensures that:
Data Encryption: All customer data, including personal information and payment details, is encrypted using protocols like SSL/TLS to secure it during transmission.
GDPR Compliance: The app provides features to ensure that customer data is handled in compliance with regulations like GDPR (General Data Protection Regulation) in the EU.
By following industry standards, these automation tools help businesses meet their legal obligations and protect customer privacy.
Conclusion
By leveraging APIs, NLP, template engines, and PDF generation libraries, apps like WaBill transform WhatsApp orders into invoices with minimal manual effort. This automation drastically reduces the workload on customer support teams and allows businesses to focus on growth and customer satisfaction. The seamless integration with WhatsApp ensures a smooth user experience, while the ability to handle real-time data enables businesses to generate invoices and send them instantly, providing a frictionless process for both customers and the company.
In 2025, as more businesses move toward automation, such solutions will become essential for staying competitive and scaling efficiently.