Selling 30 million tickets a year and with 16 million fans in its customer base, Ticketek is a prime example of a company creating colossal amounts of data every day. They knew with their 40 years experience in the business that they wanted to capture that data and derive meaningful insights from it and the tools they chose to drive that come from the MongoDB ecosystem. How did they do it?
We sat down with Tane Oakes, Enterprise Architect at Ticketek to find out how they got real-time data to work for them, their decision making process, and learn about their expansion into new markets and capabilities.
Can you describe your ticketing platform's use of MongoDB?
Ticketek is a business that sees massive peaks in activity. We partner with some of the world’s largest and most iconic venues like The Melbourne Cricket Ground, as well as leading event promoters within Australia and New Zealand and that means big events and huge ticket sales over short periods of time.
To give you an idea of that scale, when we were first exploring MongoDB, we needed a technology stack that could support selling 300k tickets in 30 minutes. We selected MongoDB as the transactional database in that stack for two primary reasons: speed and transacting.
The speed to write to and read from the MongoDB database and utilising JSON as the data format, not only across our RESTful API microservices but also in our transactional database, provided technology familiarity within our development team. We also worked closely with the MongoDB team in Sydney to develop our application with MongoDB strengths in mind.
What were you using before MongoDB? Did you consider other alternatives?
We were using a combination of relational databases and the bespoke Ticketek database engine. We considered all the relational database market leaders and other NoSQL databases when building POCs to determine how they delivered on Ticketek’s requirements -- to support hundreds of thousands of ticket sales in minutes.
Our own transition to the cloud started six years ago. We initially introduced MongoDB for our transactional database to support the ecommerce platform and managed the database ourselves. When MongoDB Atlas was made available, we moved to the cloud as part of our broader transition towards a serverless strategy.
In 2018, we worked with Google to build out our secondary ticketing platform called Ticketek Marketplace. Marketplace is a secure platform where fans can safely buy tickets and customers who have previously purchased from Ticketek can easily list their tickets for sale. It was intuitive for us to use Atlas for our Marketplace because we felt comfortable that it could handle the load we would put it under.
Can you please take a moment to describe your MongoDB deployment?
Ticketek today has multiple MongoDB clusters in MongoDB Atlas, in various regions across the AWS and GCP public clouds, powering the full Ticketek platform. For Ticketek Marketplace, the dedicated MongoDB cluster in MongoDB Atlas is deployed in the GCP Sydney region following MongoDB’s high availability best practice utilising MongoDB Stitch Functions to provide Query Anywhere access to the databases and collections. Query Anywhere allows us to easily request information that’s stored in Atlas directly from our front-end application code. Our developers are able to access all the features and scalability of the MongoDB database while securely coordinating between services, the data, and clients.
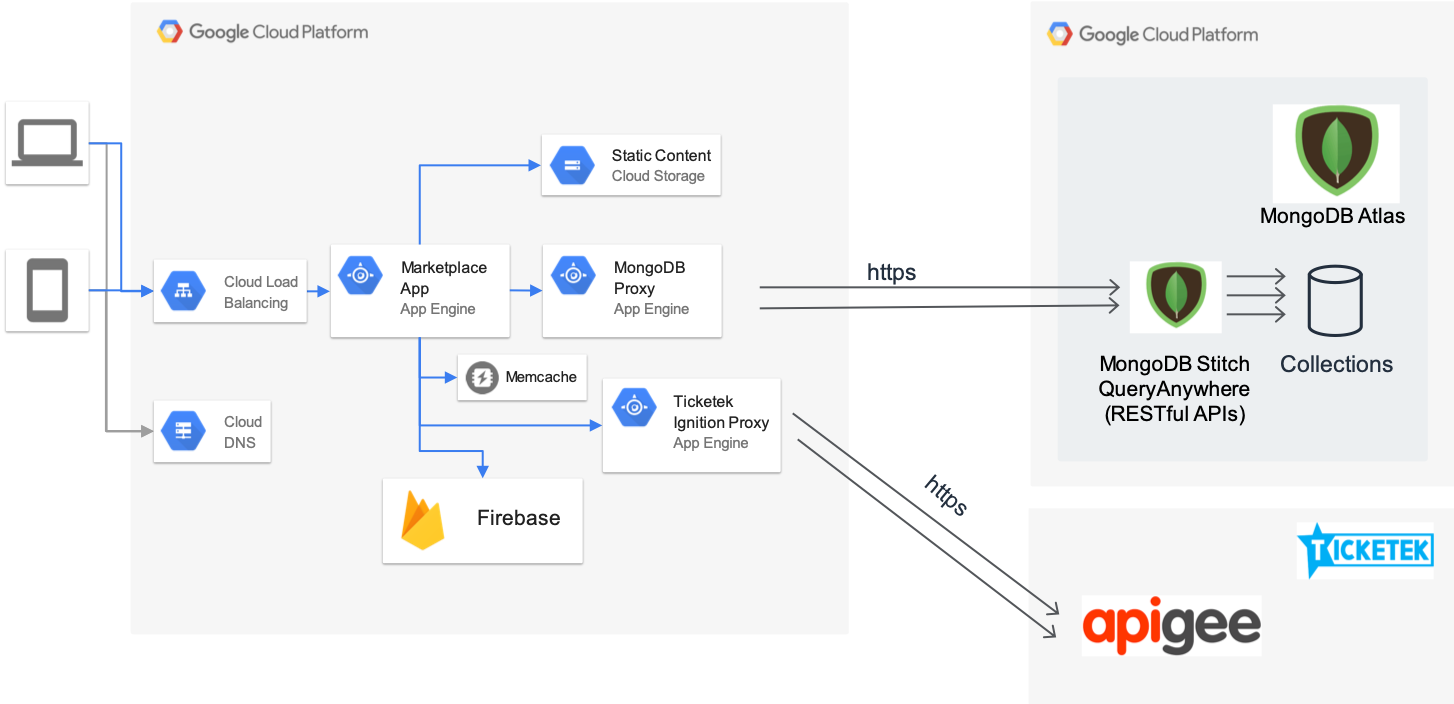
Why did you choose to build Ticketek Marketplace on Google Cloud?
One of the key drivers for leveraging GCP for the Marketplace was the appeal of the Google App Engine service which allows us to scale to zero, meaning we don’t have to worry about over or under provisioning. This is compelling from a cost perspective as it allows us to easily scale up when required for major events.
How is MongoDB performing for you as you scale up?
Our ticketing platform is constantly scaling to meet the ticketing demands of live entertainment. The reason we decided to use MongoDB for our Marketplace is its ability to successfully handle loads requiring 300,000 ticket sales in under 30 minutes; sometimes as little as 15 minutes. Our ticketing platform is at the heart of our business and we need a powerful database engine with high availability and fast reads and writes. We’ve been running MongoDB as our transactional database across our ecommerce platforms for six years and it’s exactly what we need.

Are you visualizing your data within MongoDB Atlas?
Yes, we are using MongoDB Charts for key reporting as it relates to tracking secondary sales through the Marketplace platform. We are also using it for the general operational side of things such as visualizing the length of time a ticket is up on the site and whether there is any activity. We’ve been assessing MongoDB Charts for reporting on the transactional side as well. We’d like to potentially move it across into our full reporting suite.
Do you integrate MongoDB with any analytics processing technology?
Today, we are using BigQuery to drive analytics across our platforms. Data from Atlas gets put into BigQuery through change streams and applications that are polling the oplog, then it gets pushed into Google Cloud Pub/Sub. The information gathered from that data is combined with our sales reporting to drive analytics.
The reason behind this strategy is that the ticketing business relies heavily on real-time data. There are scenarios where we may look at older data to identify trends but for the most part we are focused on getting at live data. Having access to data in real time helps us make critical business decisions like whether to open up more sections of a venue or put on more shows. I can’t stress enough how important it is for us to have access to reliable, point-in-time data. Integrating MongoDB with Google services also provides us with the analytics necessary to personalize communication and deliver a better digital-first customer experience.
Have you tried using Atlas Data Federation for large volumes of data?
Ticketek is part of a wider business called TEG which has a number of other companies across the live entertainment space, from content and promotions to venues. This results in customer data and transactional data in a number of different forms. We are currently assessing Atlas Data Federation because it would help us consolidate that data and query it using the MongoDB query language.
When dealing with data in different forms it makes sense for us to consider Data Federation. It’s part of a technology base we trust and are comfortable with, meaning we don’t have to venture into the unknown.
How do you see MongoDB fitting into your analytics roadmap?
At the heart of our analytics vision is personalization through targeted marketing. We’d like to be able to focus more on personalization to bring customers to our sites and drive ticket sales. Our goal is to reach customers in a smarter way by putting out more relevant content and offering the most suitably priced offers when they browse our site. A big step towards achieving this is successfully consolidating our data so that we can extract better insights. We’re currently focused on consolidating our data in a strategic way so that we avoid backing ourselves into a corner that we can’t get out of.
What advice would you give someone who is considering using MongoDB for their next project?
We really like MongoDB because it makes it easy to query and use our data while maintaining consistency. To utilise the power of MongoDB, consider how your systems will best leverage the database and design or refactor these systems to be built with a document database in mind.
Tane, thanks again for sharing your story with the MongoDB community.