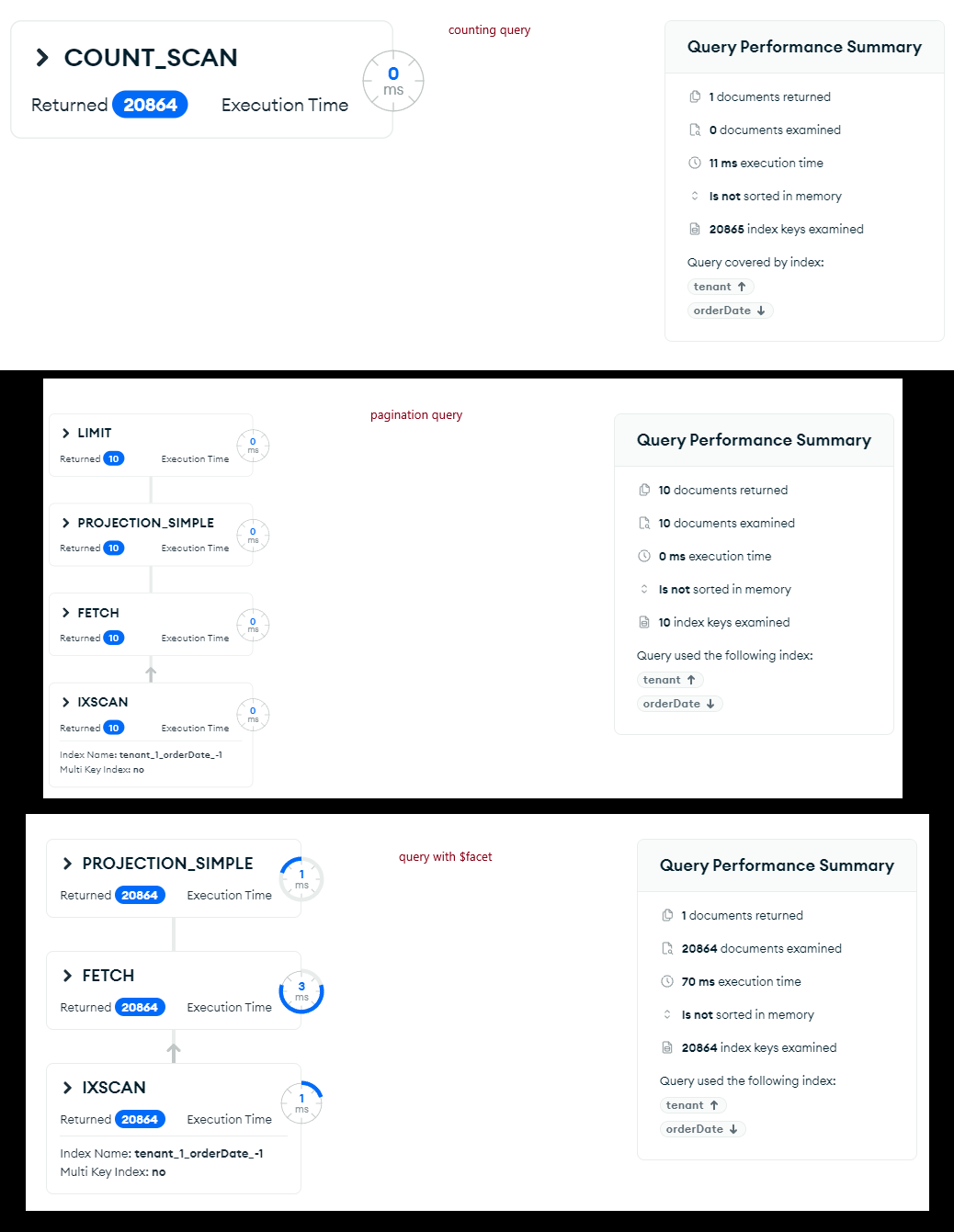
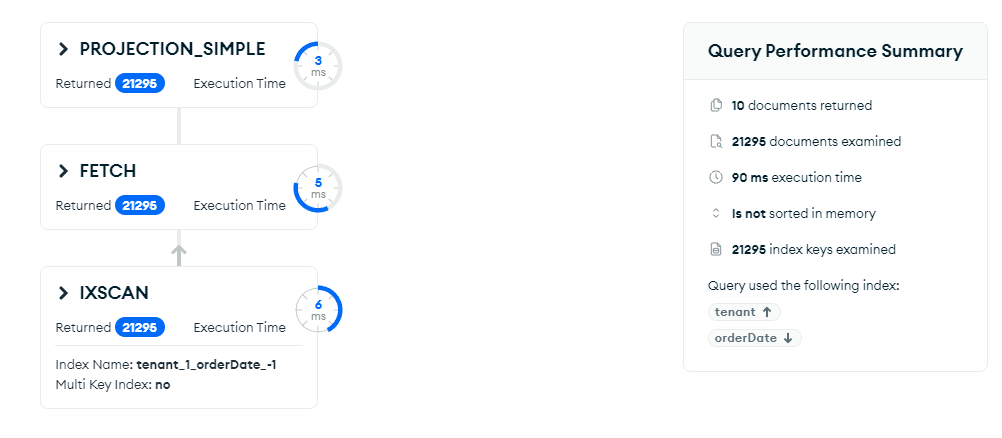
I am implementing a paginated search in my order collection. My goal is to display orders in pages of 10 items, and to ensure that pagination works correctly, I need to know how many records match the applied filters. To optimize the number of database queries, I want to perform a single query that retrieves the 10 items on the current page and, at the same time, provides the total number of orders matching the filter, allowing me to calculate the total number of pages to display.
The initial implementation consists of performing two separate queries: one to get the total number of records and another to fetch the data for the desired page. Below are examples of these two queries:
- Query to get the total number of records:
[
{
$match: {
tenant: "rosaazul",
orderDate: {
$lte: new Date("2024-09-19T23:59:59.999Z"),
$gte: new Date("2024-09-01T00:00:00.000Z")
}
}
},
{
$count: "total"
}
]
- Query to get the data for the page:
[
{
$match: {
tenant: "rosaazul",
orderDate: {
$lte: new Date("2024-09-19T23:59:59.999Z"),
$gte: new Date("2024-09-01T00:00:00.000Z")
}
}
},
{
$sort: {
orderDate: -1
}
},
{
$skip: 0
},
{
$limit: 10
},
{
$project: {
_id: 1,
number: 1,
orderDate: 1,
status: 1,
substatus: 1
}
}
]
Here is an example of an implementation using the $facet stage in a single query to retrieve both the total number of records and the page data:
[
{
$match: {
tenant: "rosaazul",
orderDate: {
$lte: new Date("2024-09-19T23:59:59.999Z"),
$gte: new Date("2024-09-01T00:00:00.000Z")
}
}
},
{
$facet: {
total: [{ $count: "total" }],
pages: [
{
$sort: {
orderDate: -1
}
},
{
$skip: 0
},
{
$limit: 10
},
{
$project: {
_id: 1,
number: 1,
orderDate: 1,
status: 1,
substatus: 1
}
}
]
}
}
]
My question is: Why, when I execute the queries in two steps, do I get the page in 0ms and the count in 47ms, but when I use a single query with $facet, it takes at least 72ms?