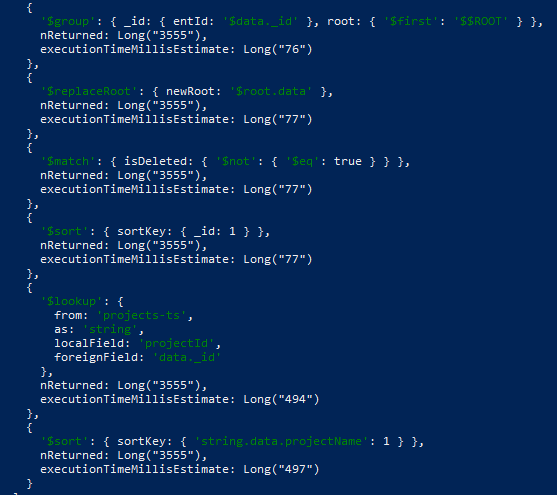
Hello @John_Page, at first, thank you for answer!
I agree, description is a bit overcomplicated. I’ll try to simplify things a bit. I’ll start with views definitions:
VIEW_A:
[{
$sort: {
timestamp: -1
}
}, {
$group: {
_id: {
entId: '$data._id'
},
root: {
$first: '$$ROOT'
}
}
}, {
$replaceRoot: {
newRoot: '$root.data'
}
}, {
$match: {
'isDeleted': {
$ne: true
}
}
}, {
$sort: {
_id: 1
}
}]
VIEW_B:
[{
$sort: {
timestamp: -1
}
}, {
$group: {
_id: {
entId: '$data._id'
},
root: {
$first: '$$ROOT'
}
}
}, {
$replaceRoot: {
newRoot: '$root.data'
}
}, {
$match: {
'isDeleted': {
$ne: true
}
}
}, {
$sort: {
_id: 1
}
}]
As you can see views are the same, regarding $match, I can’t move it before group because then I wouldn’t get newest “snapshot” of data. Example:
Collection holds each document change in the system (each removal, update, etc.), in the view I would like to always get newest snapshot (and filter out deleted ones, becase they’re deleted  )
)
Each ‘entity’ has its own set of raw-collections (which contains all snapshots of data) and view which always displays newest snaphsot (or doesn’t display anything if last snapshot had isDeleted flag set to true.
Example aggregation, which works in acceptable way (~2seconds) but points to raw collection instead of the view, this aggregation basically takes all steps from the view but without sort as a lookup pipeline:
[{
$lookup: {
from: 'projects-ts',
'let': {
projectId: '$projectId'
},
pipeline: [{
$match: {
$expr: {
$eq: [
'$data._id',
'$$projectId'
]
}
}
},
{
$group: {
_id: {
entId: '$data._id'
},
root: {
$first: '$$ROOT'
}
}
},
{
$replaceRoot: {
newRoot: '$root.data'
}
},
{
$match: {
isDeleted: {
$ne: true
}
}
}
],
as: 'project'
}
}, {
$unwind: {
path: '$project',
preserveNullAndEmptyArrays: true
}
}, {
$sort: {
'project.projectName': -1
}
}, {
$facet: {
meta: [{
$count: 'total'
}],
data: [{
$skip: 0
}, {
$limit: 15
}]
}
}, {
$unwind: {
path: '$meta'
}
}]
I hope now it is more clear what I am trying to achieve. Two questions:
- Am I able to execute this aggregation in optimal way but on a view?
- Is it a proper solution at all?