Purpose.
Select c1 collection documents, each of which overlaps with at least one c2 document and at least one c3 document by chrom field and by start-end intervals.
Collections.
c1:
| chrom | start | end |
|---|---|---|
| chr1 | 1 | 10 |
| chr1 | 10 | 20 |
| chr1 | 20 | 30 |
| chr1 | 30 | 40 |
| chr1 | 40 | 50 |
| (and then a lot of similar documents) |
c2:
| chrom | start | end |
|---|---|---|
| chr1 | 5 | 8 |
| chr1 | 5 | 16 |
| chr1 | 25 | 32 |
| chr1 | 50 | 64 |
| chr1 | 100 | 128 |
| (and then a lot of similar documents) |
c3:
| chrom | start | end |
|---|---|---|
| chr1 | 7 | 14 |
| chr1 | 28 | 49 |
| chr2 | 1 | 7 |
| chr2 | 14 | 21 |
| chr2 | 70 | 77 |
| (and then a lot of similar documents) |
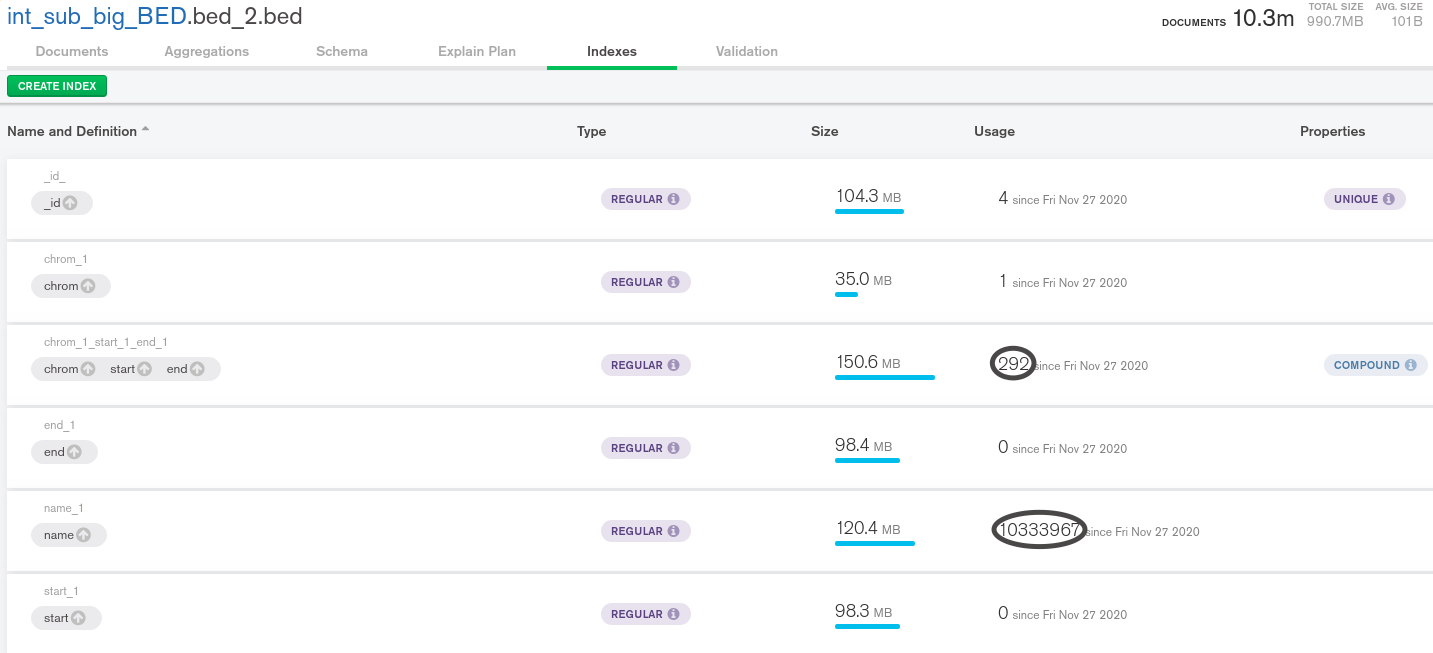
Indexes.
chrom_1_start_1_end_1
chrom_1
start_1
end_1
Aggregation pipeline.
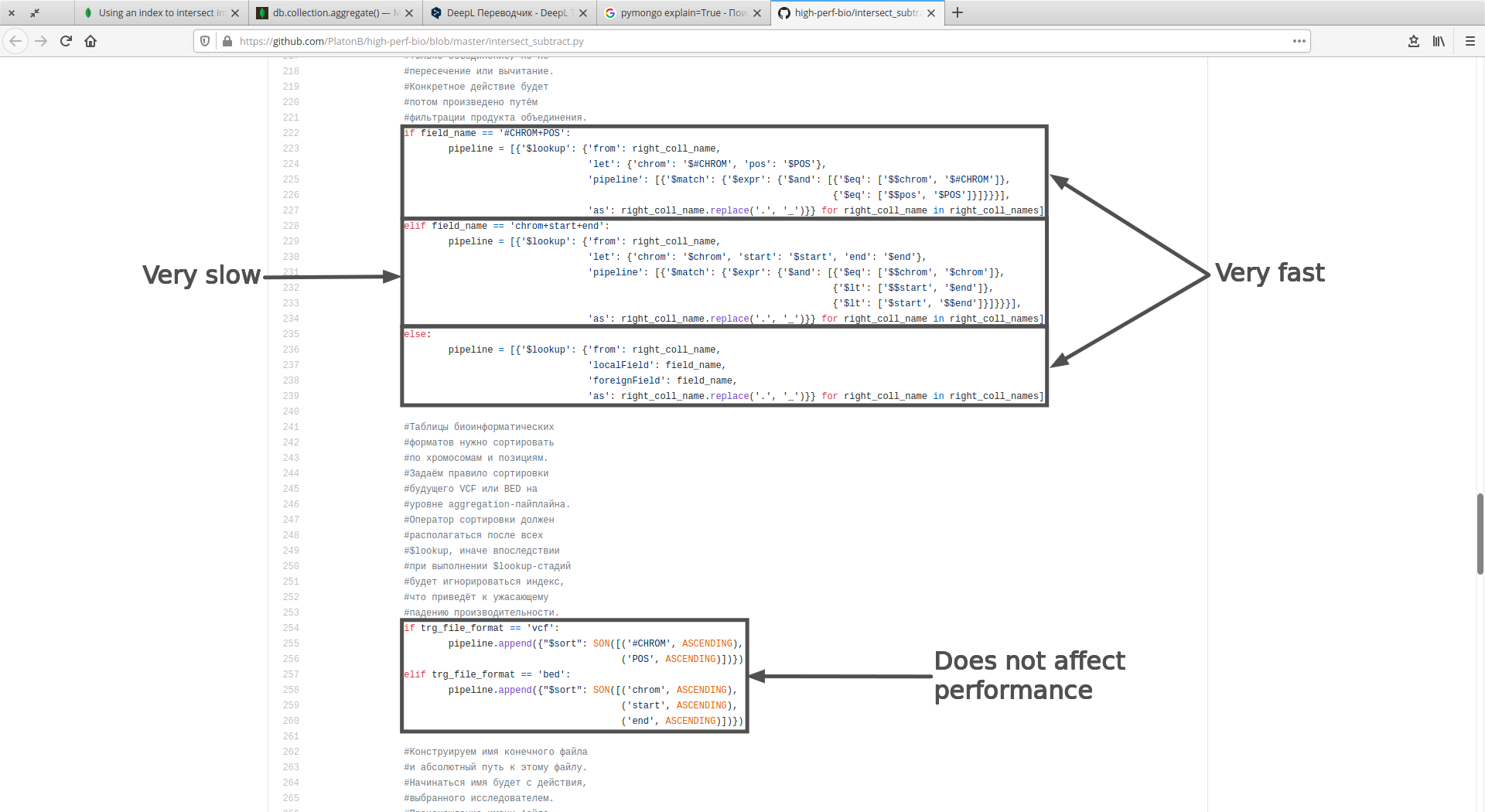
pipeline = [{'$lookup': {'from': right_coll_name,
'let': {'chrom': '$chrom', 'start': '$start', 'end': '$end'},
'pipeline': [{'$match': {'$expr': {'$and': [{'$eq': ['$$chrom', '$chrom']},
{'$lt': [{'$max': ['$$start', '$start']},
{'$min': ['$$end', '$end']}]}]}}}],
'as': right_coll_name}} for right_coll_name in right_coll_names])
Technically, this code is fully functional.
Joint documents filtration.
Further I successfully filter the merged documents by doc[right_coll_alias] != []. Full Python code is here.
Problem.
Based on the terrible speed, left_coll_obj.aggregate(pipeline) doesn’t use indexes.
Question.
How do I rework a pipeline to use compound or single indexes?