Hey there,
I’m using mongodb atlas in my web application. Recently I’ve added new batch operation that is executed weekly, but pretty soon noticed some unexpected problem with it. The idea is the following: I need to halve one field in every document in collection, so I perform the following operation (using the latest mongoose):
the collection contains >3mln documents and I’m totally fine if it takes time, as I said it’s a background job that runs weekly.
However, during this operation the database server becomes extremely slow, almost unresponsive + I see some crazy spikes in out (and a bit of in) network traffic which I can not understand (the update operation itself just returns update statistic).
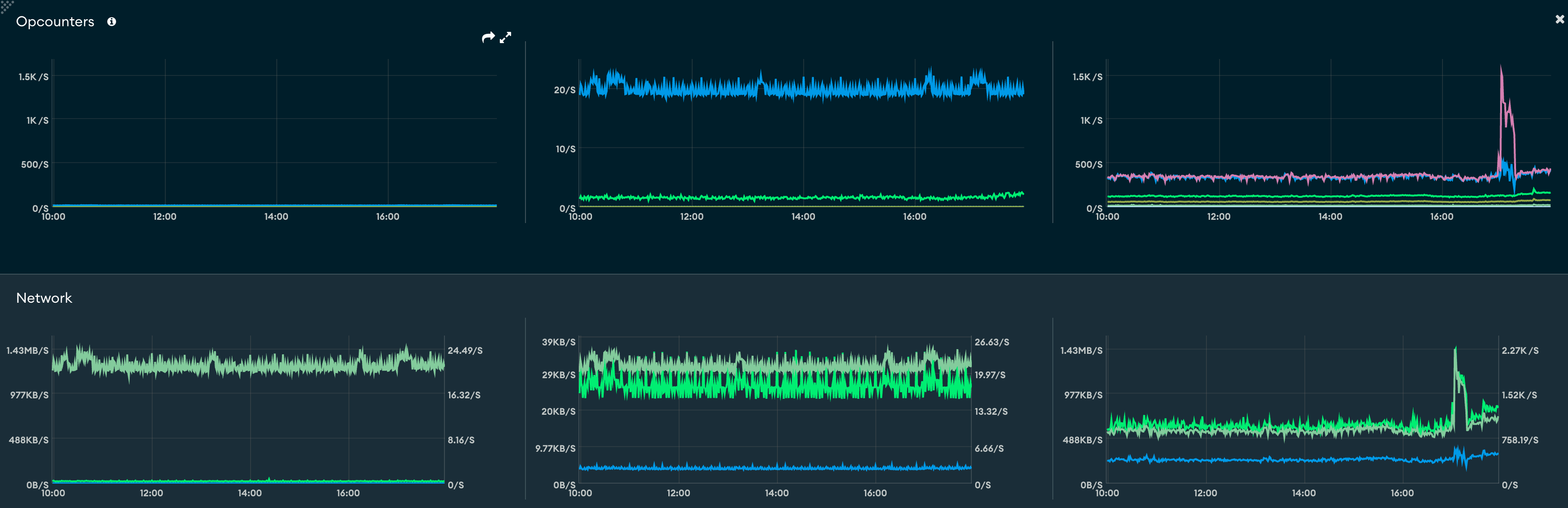
I can provide any information that might help to solve this problem, my setup is pretty standard - just a regular atlas cluster on M20 (General), MongoDB version 5.0.21. You can see the spike in the chart bellow
The spike in traffic out of the replica set primary in this case isn’t really surprising. Since this is a replica set, the changes to the documents the updateMany operation is performing are also being written to the replica set oplog, which is being tailed by the secondary members (over the network) to ensure data changes can be applied to the other members.
If a number of documents are modified on the primary in a short period of time, those changes will be replicated to all secondary members over the network.
The cluster becoming unresponsive during these times is more likely due to storage layer resource exhaustion. If you need to write a lot of data on an M20, the available disks typically don’t offer much in terms of IOPS (see Fix IOPS Issues), so if you don’t want to scale up to an M30 (where greater IOPS are availble) you can try the following:
Ensure you have an index to satisfy the filter criteria of your update
Since you’re filtering on score, having the following index would ensure you’re efficiently identifying the documents you want to update:
The above is created as a partial index providing sparse index functionality to more efficiently identify only documents where the field exists.
Logically batch the work and add artificial delays
Since the updateMany is potentially targeting all documents in the collection, if you’re ok with the process taking a little longer you could batch the job so that it only updates a limited number of documents at once, dwells, then repeats.
For example you could iteratively update 20000 documents at a time using the bulk write API (pseudocode):
batchStart = new Date();
// only project the _id field as that's all we'll need for the batch operations
filter = db.products.find({ score: { $exists: true }, last_updated: { $lte: batchStart } }, { _id: 1 });
count = filter.countDocuments();
while (count > 0) {
operations = [];
filter.limit(20000).forEach(function(d) {
// setup an updateOne operation that filters on _id
// add operation to "operations" array
});
db.products.bulkWrite(operations);
count = filter.countDocuments();
console.log(count + " documents remaining");
sleep(500);
}
For this to work the update operations would also need to set the update documents last_updated field to a current timestamp. You’d also want to ensure the index recommended above was modified to be:
thank you so much @alexbevi for the detailed answer, and especially - for getting into the problem and offering valuable solutions.
everything is super clear to me, I think we won’t migrate at the moment (this task alone is not that important), so I would rather modify the snippet to batch updating as you suggested.