I am trying to read data from 3 node MongoDB cluster(replica set) using PySpark and native python in AWS EMR. I am facing issues while executing the codes with in AWS EMR cluster as explained below but the same codes are working fine in my local windows machine.
- spark version - 2.4.8
- Scala version - 2.11.12
- MongoDB version - 4.4.8
- mongo-spark-connector version - mongo-spark-connector_2.11:2.4.4
- python version - 3.7.10
Through Pyspark - (issue - pyspark is giving empty dataframe)
Below are the commands while running pyspark job in local and cluster mode.
-
local mode : spark-submit --master local[*] --packages org.mongodb.spark:mongo-spark-connector_2.11:2.4.4 test.py
-
cluster mode :
spark-submit --master yarn --deploy-mode cluster --packages org.mongodb.spark:mongo-spark-connector_2.11:2.4.4 test.py
with both the modes I am not able to read data from mongoDB(empty dataframe) even though telnet is working across all nodes from spark cluster(from all nodes) . From the logs, I can confirm that spark is able to communicate with mongoDB and my pyspark job is giving empty dataframe. Please find below screenshots for same!
22/10/28 08:42:13 INFO connection: Opened connection [connectionId{localValue:1, serverValue:67507}] to 10.00.000.000:19902
22/10/28 08:42:13 INFO connection: Opened connection [connectionId{localValue:2, serverValue:1484}] to 10.00.000.000:20902
22/10/28 08:42:13 INFO cluster: Monitor thread successfully connected to server with description ServerDescription{address=10.00.000.000:19902, type=REPLICA_SET_SECONDARY, state=CONNECTED, ok=true, version=ServerVersion{versionList=[4, 4, 8]}, minWireVersion=0, maxWireVersion=9, maxDocumentSize=16777216, logicalSessionTimeoutMinutes=30, roundTripTimeNanos=63396153, setName='ABCD', canonicalAddress=10.00.000.000:19902, hosts=[10.00.000.000:18902, 10.00.000.000:19902], passives=[], arbiters=[10.00.000.000:20902], primary='10.00.000.000:18902', tagSet=TagSet{[]}, electionId=null, setVersion=10, lastWriteDate=Fri Oct 28 08:42:12 UTC 2022, lastUpdateTimeNanos=9353874207439702}
22/10/28 08:42:15 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
22/10/28 08:42:15 INFO DAGScheduler: ResultStage 1 (showString at NativeMethodAccessorImpl.java:0) finished in 0.032 s
22/10/28 08:42:15 INFO DAGScheduler: Job 1 finished: showString at NativeMethodAccessorImpl.java:0, took 0.038818 s
++
||
++
++
22/10/28 08:42:15 INFO SparkContext: Invoking stop() from shutdown hook
22/10/28 08:42:15 INFO MongoClientCache: Closing MongoClient: [10.00.000.000:19902,10.00.000.000:20902,10.00.000.000:18902]
Below is the code snippet for same:
from pyspark import SparkConf, SparkContext
import sys
import json
sc = SparkContext()
spark = SparkSession(sc).builder.appName("MongoDbToS3").config("spark.mongodb.input.uri", "mongodb://username:password@host1,host2,host3/db.table/?replicaSet=ABCD&authSource=admin").getOrCreate()
data = spark.read.format("com.mongodb.spark.sql.DefaultSource").load()
data.show()
please let me know anything I am doing wrong or missing in pyspark code?
Through native python code - (issue - code is getting stuck if batch_size >1 and if batch_size =1 it will print first 24 mongo documents and then cursor hangs)
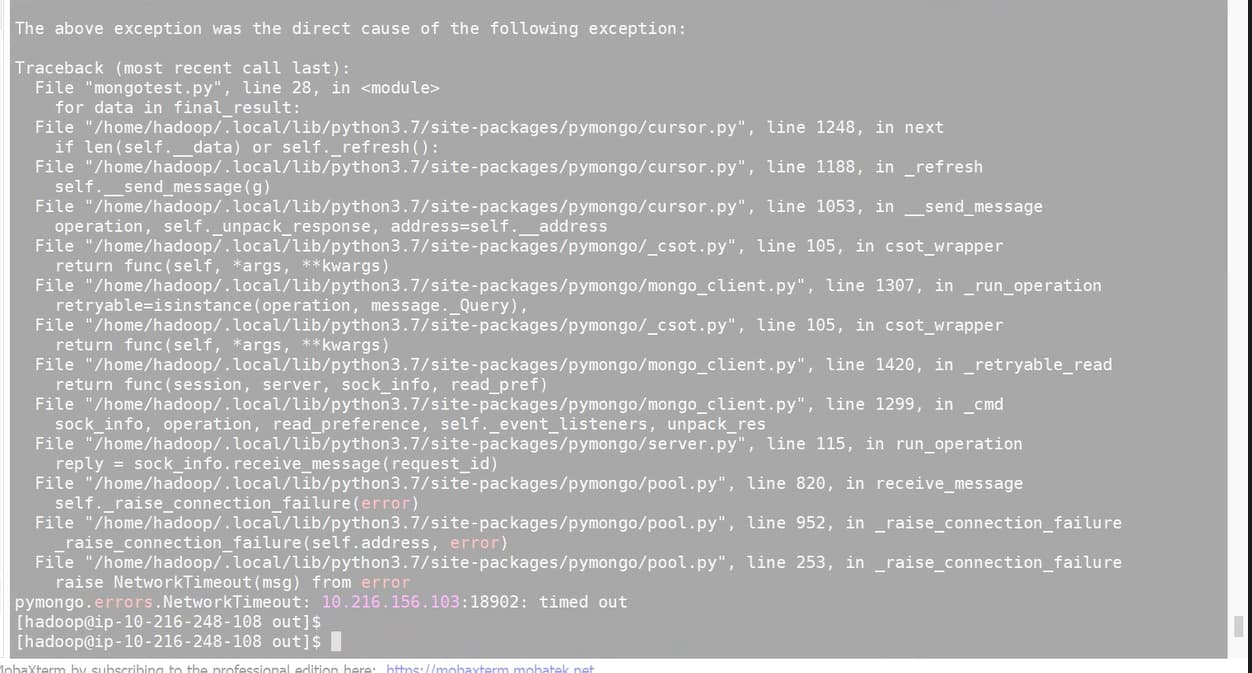
I am using pymongo driver to connect to mongoDB through native python code. The issue is when I try to fetch/print mongoDB documents with batch_size of 1000 the code hangs forever and then it gives network time out error. But if I make batch_size =1 then cursor is able to fetch first 24 documents after that again cursor hangs. we observed that 25th document is very big(around 4kb) compared to first 24 documents and then we tried skipping 25th document, then cursor started fetching next documents but again it was getting stuck at some other position, so we observed whenever the document size is large the cursor is getting stuck.
can you guys please help me in understanding the issue?
is there anything blocking from networking side or mongoDB side?
below is code snippet :
from datetime import datetime
import json
#import boto3
from bson import json_util
import pymongo
client = pymongo.MongoClient("mongodb://username@host:port/?authSource=admin&socketTimeoutMS=3600000&maxIdleTimeMS=3600000")
# Database Name
db = client["database_name"]
# Collection Name
quoteinfo__collection= db["collection_name"]
results = quoteinfo__collection.find({}).batch_size(1000)
doc_count = quoteinfo__collection.count_documents({})
print("documents count from collection: ",doc_count)
print(results)
record_increment_no = 1
for record in results:
print(record)
print(record_increment_no)
record_increment_no = record_increment_no + 1
results.close()
below is output screenshot for same
for batch_size = 1000 (code hangs and gives network timeout error)
documents count from collection: 32493
<pymongo.cursor.Cursor object at 0x7fe75e9a6650>
batch_size = 1 (prints documents only till 24th and then cursor hangs)
python3 mongofiltercount.py
documents count from collection: 32492
<pymongo.cursor.Cursor object at 0x7f2595328690>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24