There is a yellow warning icon on the left of the primary node of my atlas cluster and I can’t connect to it. But there is not even any alert information about how to solve it.
Hi @Guorui_Wang and welcome in the MongoDB Community  !
!
Is it still happening?
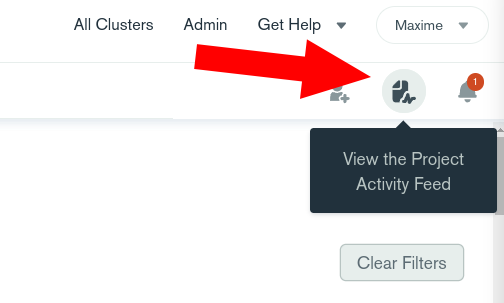
Could you please have a look to the project feed activity (top right corner) and tell me if you see some entries around the time of the incident?
Cheers,
Maxime.
Hi, I have the exact same problem as @Guorui_Wang, and I could not find any more information in the internet.
Thanks a lot!
Cheers,
Cobo
same problem about 30 min ago, now its seem to work fine and no warning icon
Check out the Project Activity Feed in the top right corner. There are many reasons why a node status might change but Atlas is self healing and will get back to a normal state ASAP.
For example here, my nodes had to be restarted for a scheduled maintenance (usually a minor version upgrade).
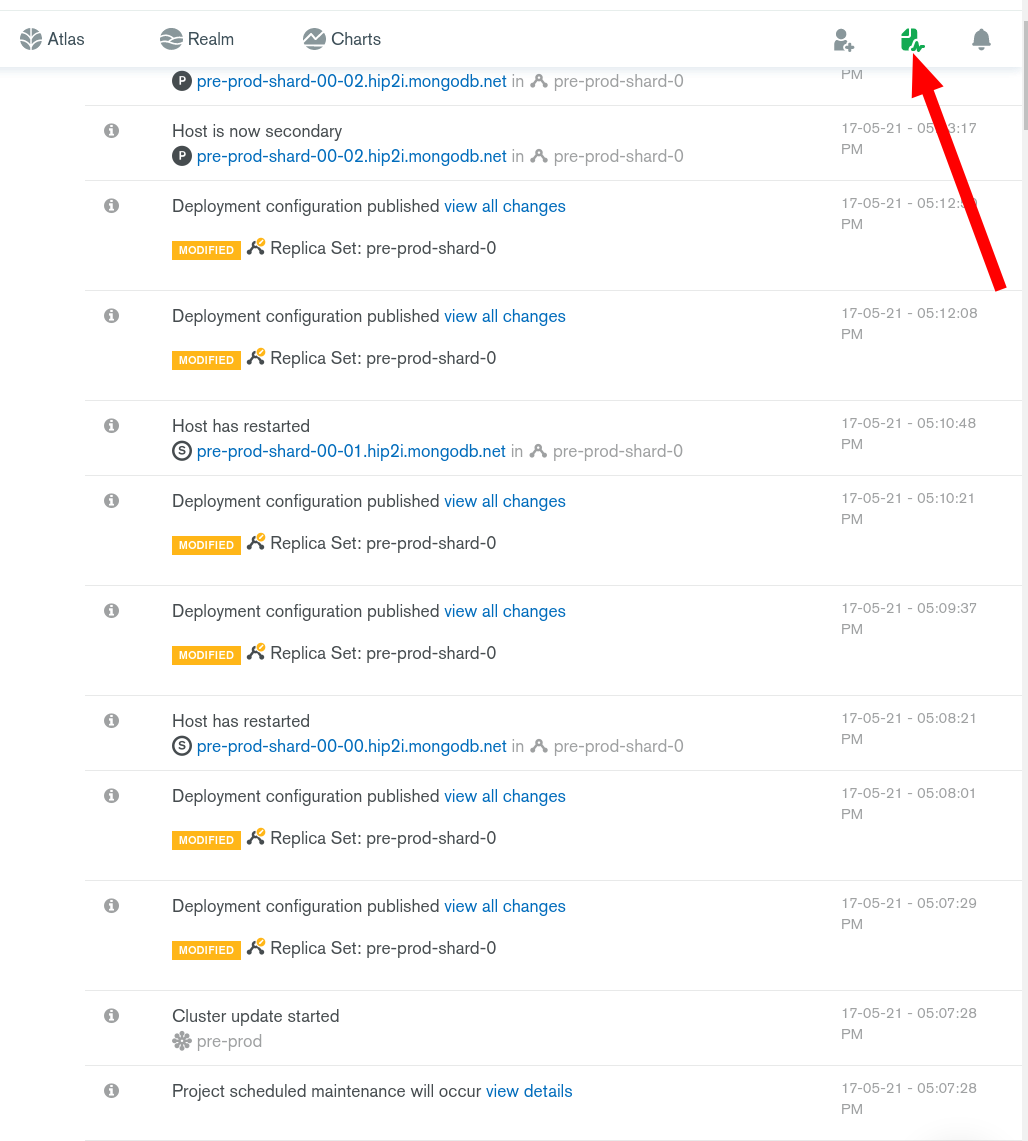
1 Like
For the period of the issue there were no items in my Project Activity Feed, the only items I see are my attempts to cycle the network access to get the cluster back online.
Edit: I now see multiple items listed as “Cluster update started” and “Cluster update complete”, is this what could have caused the issue?
Cluster update completed 05/17/21 - 08:01:36 PM
mba-cluster
Cluster update started. 05/17/21 - 08:00:54 PM
mba-cluster
Cluster update completed 05/17/21 - 08:00:54 PM
mba-cluster
Cluster update started 05/17/21 - 07:44:00 PM
mba-clusterYes, it’s expected to see a yellow warning during a cluster update which is performed by restarting the nodes from the replica set in a rolling manner so there is no downtime. Once the update is done for each node, you are back in a normal state.
You can tune the maintenance windows if you have specific constraints:
@MaBeuLux88_xxx thank you for your comment, I also believed that any updates would be performed in a rolling manner to a cluster but in this case that was not what happened.
Thank you for all your assistance and my apologies for the long post that follows:
TLDR:
Need to fully understand impact for upcoming project as we cannot have production cluster unavailable due to circumstances beyond our control.
Detail:
As per the case above I saw my cluster (primary and both secondaries) with the warning icon and the entire cluster was unavailable for approximately 20 minutes - this corresponds to the timings show in the activity feed post incident (but the activity feed did not show this at the time).
In addition other users experienced the same issue as above also recorded in post 107411:
- @Jurn_Ho - same issue with M0 cluster in AWS eu-central-1 but other M0 clusters also in AWS eu-central-1 were not impacted
- @Juan_Diaz_1 - unknown cluster unavailable at same time for ~30 minutes
Given that this does not appear to be a one-off issue impacting just myself can you investigate and advise what the issue with the update / cluster was.
Some questions:
- As per the logs above why did the update take so long? (logs above show 19:44 start and 20:01 complete)
- Why was the cluster unavailable - was the update not applied in a rolling manner?
- Was the update applied to all nodes simultaneously because this is an M0 cluster?
- Was the non-rolling update related to this cluster being a M0 or being in the aws eu-central-1 region?
- Would a paid or dedicated cluster have experienced this downtime - do you have any evidence of this?
I appreciate a lot of these questions are overkill, especially considering this is a M0 cluster however I am in the middle of validating and pricing Mongo Atlas and Mongo Realm for a large project which is looking to deploy multiple large multi-region clusters (M60+) to support our global app and 200k users and need to understand this impact as we cannot have clusters randomly unavailable due to circumstances we cannot control in a production system and maintain our SLA with our end users.
Thanks for the extra context @mba_cat, it’s really helpful.
I don’t know what happened to your M0 cluster (and I can’t investigate myself - I don’t have any access) - but someone from the support team would be able to help. I will also ping the Atlas team in our internal Slack to see if someone wants to share more details.
You can reach the support directly by using the bottom right button in Atlas:

And then start a conversation.
BUT, with that being said, M0 cluster are NOT production ready and they don’t come with any SLA guarantee, so I wouldn’t spend too much time tracking this issue. M0 are deployed on shared environment using shared RAM, etc. They can be impacted by many outside reasons and aren’t reliable by design. It’s just the free tier…
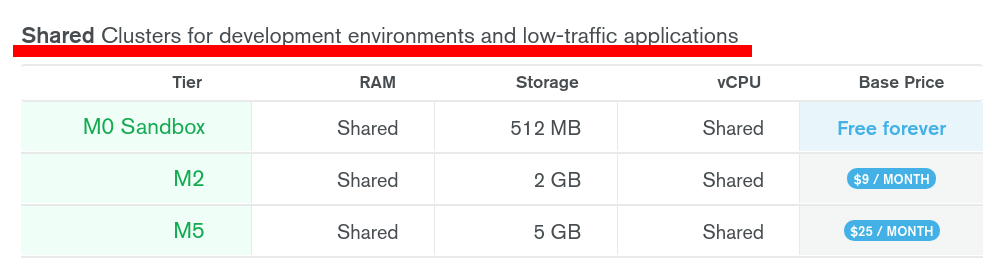
Shared environment cannot guarantee the same availability level than dedicated clusters which DO have a 99.995% uptime SLA for M30 and above:

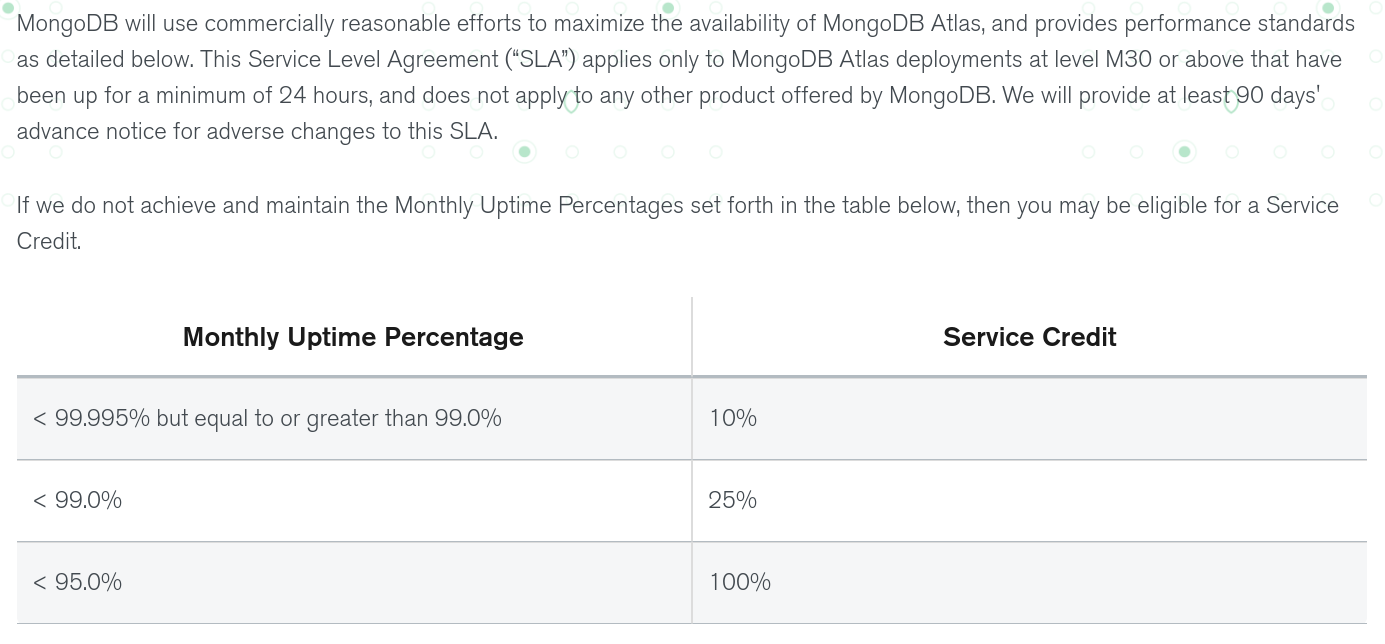
Source: MongoDB Atlas Service Level Agreement | MongoDB
So please, don’t judge the service based on an M0 cluster ![]() . Your M60 will be a lot safer as it’s using dedicated servers and if you want extra++ availability guarantees, there are a few “tricks” that you can explore:
. Your M60 will be a lot safer as it’s using dedicated servers and if you want extra++ availability guarantees, there are a few “tricks” that you can explore:
First: 99.995 SLA applies on a 3 nodes replica set. But if you add more nodes in your replica set (5 or 7 total), you have already a lot less chances to be impacted by a server issue.
Second: But maybe you can’t trust a single cloud region. If the entire data center where you are hosting your 7 nodes goes dark… So does your entier cluster. So instead, you could deploy your nodes in 3 different DC (AWS Paris, Dublin and Frankfurt for example).
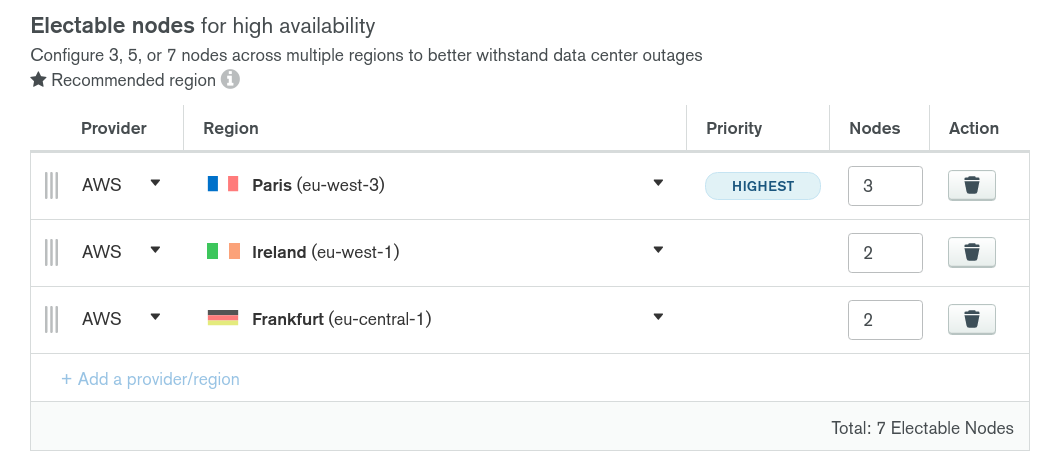
Here, even if AWS Paris goes dark, one election later (a few seconds), and your cluster is still available and processes write operations. Read operations would be potentially unaffected, depending on which readPreference option you are using.
Third: If you can’t trust AWS (or another Cloud Provider) entirely because you suspect that they can have global outages (yes, they definitely can), then maybe you want to leverage the multi-cloud option and deploy your nodes in multiple cloud providers to lower even more the chances of being impacted by a global outage.
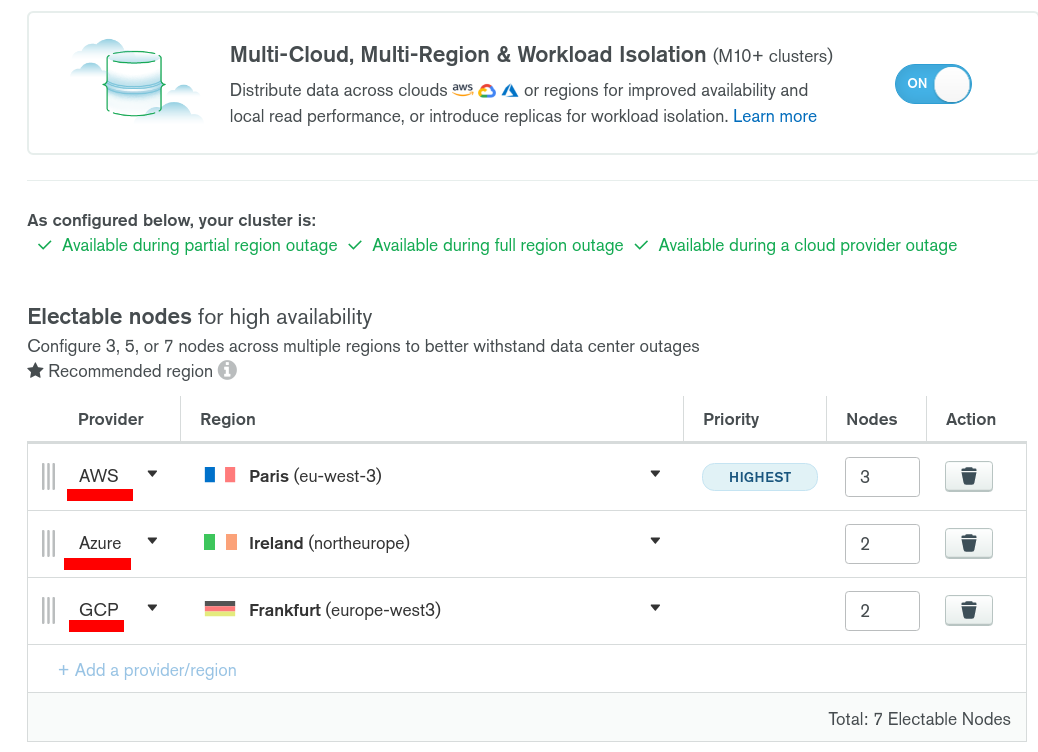
At this point… you would need a global outage in 2 different regions in 2 different cloud providers to go down… So if this ever happens, there are solid chances that most of the Internet is already down already at this point, so probably everybody is down along with your cluster… Which would still be able to process read operations if one of the secondary node is still available ![]() in the third region and cloud provider and if you are not using the readPreference “primary” but “primaryPreferred” for example.
in the third region and cloud provider and if you are not using the readPreference “primary” but “primaryPreferred” for example.
Note that the cluster still needs to be able to reach the majority of the voting members in the replica set to be able to trigger an election and elect a primary. If 2 DC are completely gone (3+2 or 2+2) as I have 7 nodes in this example my majority = 4 so I wouldn’t have enough nodes online to elect a primary.
Finally, you can subscribe to https://status.cloud.mongodb.com/ to get notified when a global incident is reported on Atlas or Realm.
I’ve been using Atlas & Realm for a while now, and I also experienced issues with M0 a few times, but never with an M10 or above.
I hope this helps ![]() !
!
Cheers,
Maxime.
1 Like
Hi @MaBeuLux88_xxx absolutely perfect and exactly mirrors what I expected with the higher tiers from working through mongo uni and the docs, especially regarding the slas / additional nodes / redundancies in different regions and cloud providers - thank you for your detailed answer it really helps me and I hope it also helps others.
I am using this M0 cluster as a throwaway to run through some tests regarding CI/CD and the use of Realm and was worried I had missed something when the whole cluster became unresponsive and I couldn’t see a way to recover good to know it’s the M0 and I can factor in M10+ for the development boxes.
2 Likes
Happy I was helpful ![]() !
!
Don’t forget to pause your pre-prod / qualif / dev clusters at night & during the weekends to save some fresh $$$ ![]() . It’s easy to automate this with a cron & the Atlas API or CLI. More $$$ for a beefy highly available prod cluster
. It’s easy to automate this with a cron & the Atlas API or CLI. More $$$ for a beefy highly available prod cluster ![]() !
!
https://www.mongodb.com/how-to/pause-resume-atlas-clusters/#single-project-api-key
2 Likes
I just received more intel on the issue you saw on the M0.
The Atlas team ran into some issues with proxies (used in shared tiers…) which affected 8 M0 clusters across US east 1 and EU central 1.
This issues didn’t affect all the proxies so only a few M0 clusters were impacted.
Again, that problem doesn’t exist on dedicated tiers as there is no need for this extra layer of complexity.
2 Likes
I have the same problem for several hours. orange triangle and impossibility to connect to an Atlas! :-/
How long does self-repair usually take please?
- nothing in the log
You can track MongoDB Cloud operational issues here: https://status.cloud.mongodb.com/. But I don’t see any incident at the moment.
I would reach out directly to the support using the button in the bottom right corner of MongoDB Atlas.
Note that an orange flag doesn’t mean that the cluster is down. Maybe it’s just missing a node because it’s doing a rolling update or upgrade and this state shouldn’t last for more than a few minutes.
Check out the Project Activity Feed to see what is happening:
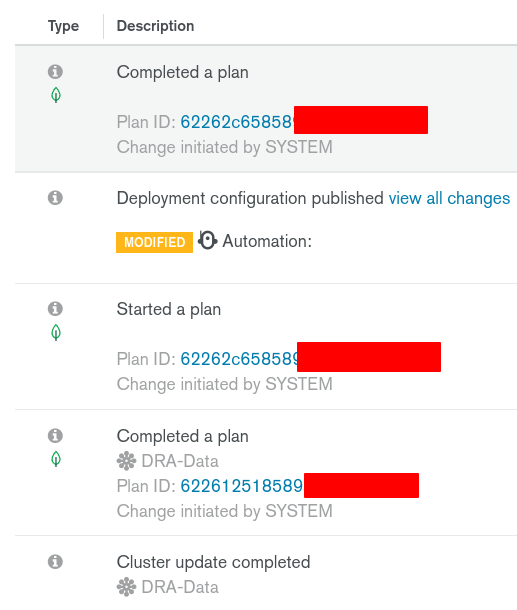
It’s often just the automation doing its job to keep everything up-to-date.
Cheers,
Maxime.
1 Like