I am using the latest version of MongoDB.
The problem is observed when working with a fairly large collection.

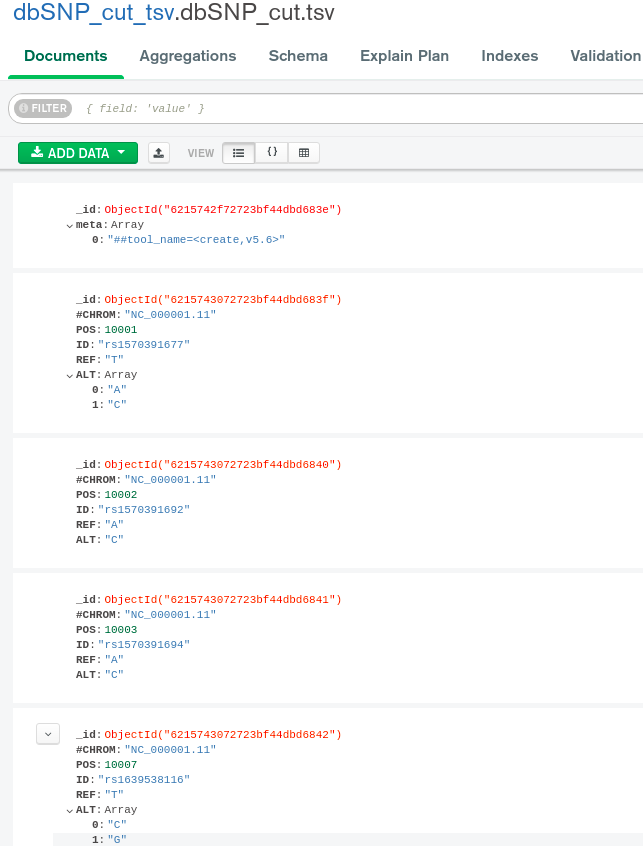
There is a field meta, corresponding to only one document, and which is supposed to be excluded at any query.
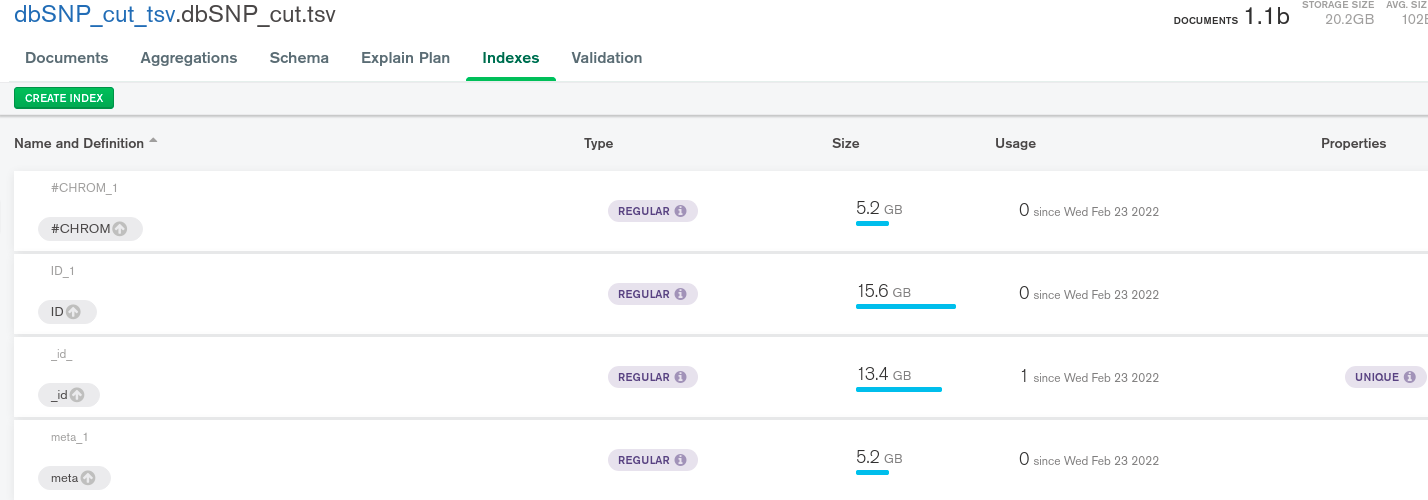
To make meta exclusion work momentarily, this field is indexed. The strangeness begins with the fact that the size of meta_1 index is inadequately huge.
But the main problem is the inability to execute a query that excludes meta.
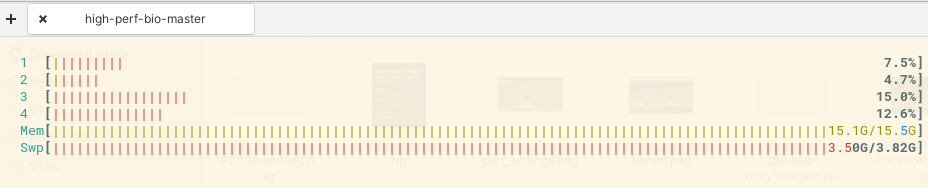
The query takes a very long time and fills all the RAM, and as a result the connection to the MongoDB server breaks.
Hi @Platon_workaccount,
If you create a normal index on the field meta that only exists in one document in a collection that contains 1.1B docs, you will have 1.1B entries in your index because indexes in MongoDB create one entry for each document. So one entry contains the value for that ONE meta field and everything else contains “NULL”.
That’s why we have sparse indexes and partial indexes.
Add the sparse option on your index and you won’t index all the documents that do NOT contain that field. You will notice that your index size will be a LOT smaller. You will only be able to use this index if you filter using this field (see doc). It won’t work if you try to get the docs that DON’T have this field, as they are not even in the index by definition.
Regarding the RAM issue, I see that you have really large indexes. Indexes need to be entirely in RAM to be efficient. As a reminder, MongoDB needs RAM for:
- the OS
- indexes
- working set
- queries (including aggregation, sort in memory, etc).
As a rule of thumbs total DB sizes * 15 to 20 % = RAM
So for example. For a 200 GB database, 30 to 40GB of RAM is about right. You can take exemple on the Cluster Tiers available in Atlas to get an idea of the ideal sizes.
Your indexes look very large compared to your data size for this collection. Which version of MongoDB are you using?
Cheers,
Maxime.
1 Like
But I need to get all docs except the one containing meta.
MongoDB 5.0.6
Well then that’s ALL the documents (20GB) minus 1 doc. You don’t need an index for that. It’s a collection scan of the entire collection. An index won’t help. It also means that the entire collection will be in the cache so you need a large LARGE one… Are you sure that you need 20GB of data in your client?
If 99.9% of your docs don’t have this field, then it’s not worth it. Just create an index for whatever other query you want to support and just add the {meta: {$exists: false}} in your queries. They will use the indexes that actually speed up the research, fetch the docs and then check if one doc eventually has meta in it and can be eliminated. It’s not worth adding the meta at the end of every index because it’s going to store a lot of null values (and take a lot of space) for almost zero extra speed.
Also, why is that weird document in that collection? Can’t you remove it from here and put it in another collection with other similar documents?
From what I see, your cluster is starving for RAM. A database (any on the market) should never swap.
CF the production notes about swap: https://docs.mongodb.com/manual/administration/production-notes/#swap
Cheers,
Maxime.
1 Like
In practice, I use throwing out meta in combination with other queries and/or aggregation stages. I did not initially write about this so as not to distract from the main issue.
Let’s say we have such query:
{'meta': {'$exists': false}, 'POS': {'$nin': [10438, 10440, 10441]}}
…and there is a POS only index. Spoiler: “Explain plan” really shows that IXSCAN is involved. But I don’t understand how it works. Without an index of meta, how does the DBMS know that the corresponding document is the only one and is located only at the beginning of collection? Only the creator of the database knows that meta appears once and is always in the first position. In theory, without an index, the engine should walk through absolutely all documents to make sure there is no meta field in unexpected places in the collection.
A bioinformatic table/collection can have a rich history, and a good practice in this science is to store the info about the origin of table in meta-strings.
Let’s focus on this query {'meta': {'$exists': false}, 'POS': {'$nin': [10438, 10440, 10441]}}.
Let’s imagine that you have 1 billion (1B) documents in your collection. 1 of them has a meta field (only one).
80% of the docs have a POS in [10438, 10440, 10441].
Given the distribution of the data, having an index on meta is either the most useful or the most useless index on the planet - depending on the query. If you are running for meta exists => Super efficient. If you are looking for not exists => Useless as you basically take ALL the entries but one from the index => not having an index would probably save time at this point.
Now with an index on POS. You want the values NOT in 10438, 10440, 10441. You can use the index on POS and discord 80% of the database. At this point, mongod fetches the docs on disk and brings them in the cache (RAM) and now have access to all the fields in the docs. It resolves the end of the query: “is there a meta field? => if yes remove from the list”. At this point you return 20% * 1B docs = 200M docs +/- 1 document (the meta one).
Using a compound index {POS:1, meta:1} would avoid potentially fetching that one document and then removing it from the list of docs to return. But this would double the size of the index, so it’s clearly not worth it. If 50% of the docs add a meta field, this would be another story. But given the uneven distribution that we have here (1 in 1B), it’s not worth it.
So the correct and optimised index for this query is {POS: 1}, given that distribution and this query.
Note that in this example, we are still returning about 20% of 1B docs which is about 20GB so that’s 4GB of docs uploaded from the DB => client and all those docs are moved from disk => RAM in that process (working set).
Cheers,
Maxime.
1 Like
{kind=link}