Hello MongoDB Community,
I am trying to read from a MongoDB database collection and write back to another MongoDB collection in another database using pyspark and structured streaming (v10.0.5).
This is the code I am following (without any processing added for now, I just want to test read & write stream)
spark = SparkSession. \
builder. \
appName ("streamingExampleRead"). \
config ("spark.jars.packages", "org.mongodb.spark:mongo-spark-connector:10.0.5"). \
getOrCreate ()
query = (spark.readStream.format ("mongodb")
.option ("spark.mongodb.connection.uri", "mongodb://mongo:27017/")
.option ("spark.mongodb.database","database_1")
.option ("spark.mongodb.collection", "read_collection")
.option ("spark.mongodb.change.stream.publish.full.document.only", "true")
.option ("forceDeleteTempCheckpointLocation", "true")
.load ())
query2 = (query.writeStream
.format ("mongodb")
.option ("forceDeleteTempCheckpointLocation", "true")
.option ("spark.mongodb.connection.uri", "mongodb://mongo:27017/")
.option ("spark.mongodb.database", "database_2")
.option ("spark.mongodb.collection", "write_collection")
.option ("spark.mongodb.change.stream.publish.full.document.only", "true")
.option ("forceDeleteTempCheckpointLocation", "true")
.outputMode ("append")
.trigger(continuous="1 second")
.start().awaitTermination())
I keep getting the error Lost task 0.0 in stage 0.0 (TID 0) (172.18.0.4 executor 1): org.apache.spark.SparkException: Data read failed
(Using Spark 3.3.0 & Mongo 6)
Could anyone tell me if there is something wrong with the syntax or logic of this code in reading & writing data ?
Thank you
try
query2 = (query.writeStream
.format ("mongodb")
.option ("spark.mongodb.connection.uri", "<<connection string here>>")
.option ("spark.mongodb.database", "database2")
.option ("spark.mongodb.collection", "write_collection")
.option ("spark.mongodb.change.stream.publish.full.document.only", "true")
.option ("forceDeleteTempCheckpointLocation", "true")
.option("checkpointLocation", "/tmp/mycheckpoint")
.outputMode ("append")
.trigger(continuous="1 second").start().awaitTermination())
Thank you for your reply, I’ve applied the changed to query2 but I am still getting the errors:
org.apache.spark.SparkException: Data read failed
Caused by: com.mongodb.spark.sql.connector.exceptions.MongoSparkException: Could not create the change stream cursor.
Caused by: com.mongodb.MongoCommandException: Command failed with error 40573 (Location40573): ‘The $changeStream stage is only supported on replica sets’ on server mongo:27017. The full response is {“ok”: 0.0, “errmsg”: “The $changeStream stage is only supported on replica sets”, “code”: 40573, “codeName”: “Location40573”}
Any possible solutions to these ?
– Update,
From what I understood is that since I am using readStream & writeStream, I will be utilizing the change stream which requires a replicateSet set up with at least 3 mongo nodes (I just had a single standalone mongo node in my docker-compose file).
After setting up a proper mongo cluster (3 nodes now) and placing it in the same network as my spark application, the stream seems to be running with no crashes or error.
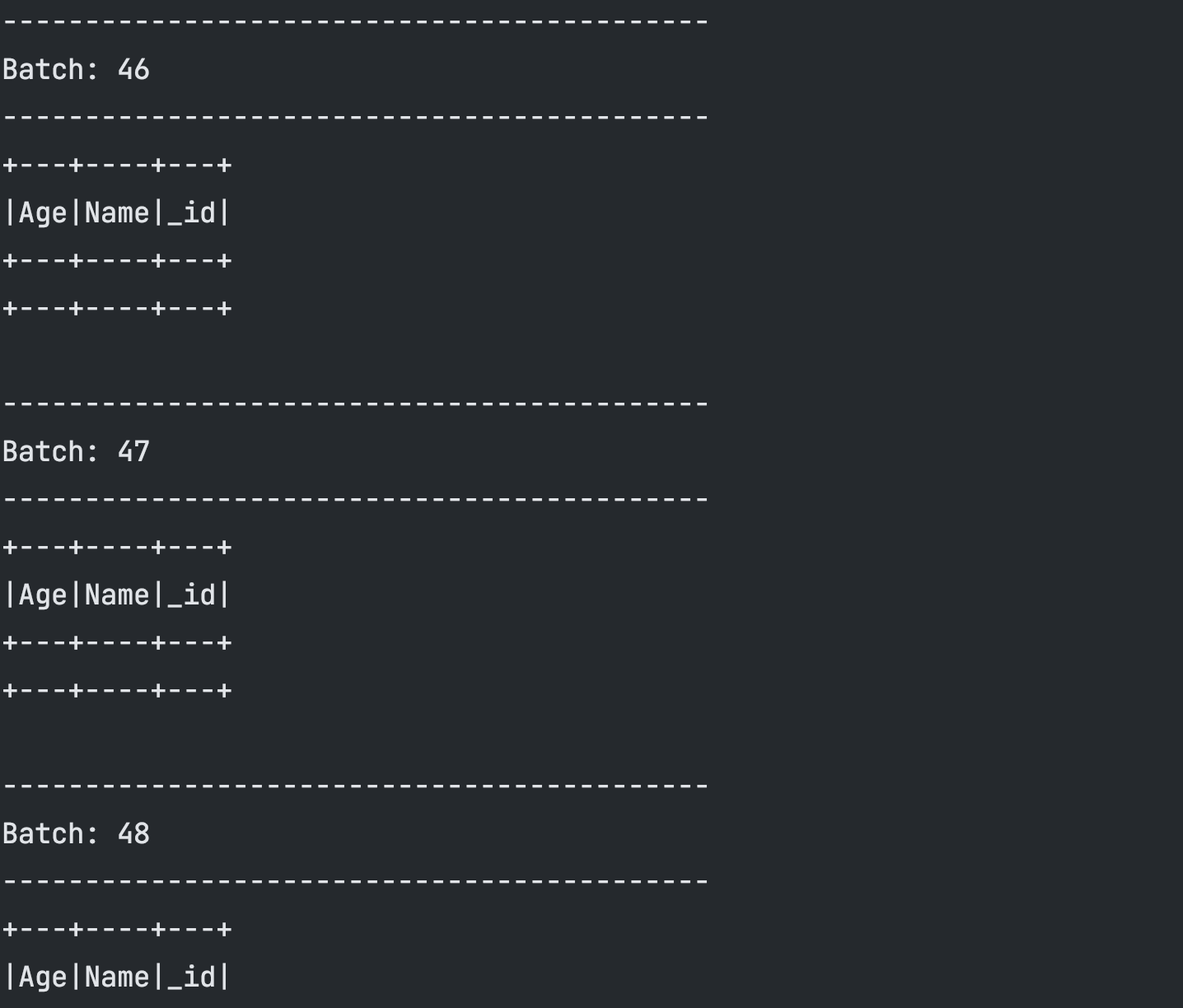
However, I now keep getting empty data in return (check image below) - I decided to output to console just to view some results before outputting to mongo like the original plan.
What could be the issue in this scenario ?
I am passing this uri for my readStream: ‘mongodb://mongo1:27017,mongo2:27018,mongo3:27019/test_data.readCol?replicaSet=dbrs’
My database is: test_data
My collection is: readCol
Thank you in advance for the help
–Update part 2
So from what it seems, it won’t pick up data already in the database, but only any new data that gets added after the stream is launched will be detected by the stream and written into the sink. This, of course, is because we are in append mode.
I guess to get everything you would have to use the Complete mode (which is not supported with readStream or writeStream from what I’ve seen – Check documentation, don’t take my literal word for it.)
Can you try adding a schema to the readstream ?
something like
priceSchema = ( StructType()
.add('Date', TimestampType())
.add('Price', DoubleType())
)
then add it to the readstream
...
.option ("spark.mongodb.change.stream.publish.full.document.only", "false")
.option ("forceDeleteTempCheckpointLocation", "false")
**.schema(priceSchema)**
.load ())
Hi Rober, thanks again for the reply.
I’ve added the schema, however setting the spark.mongodb.change.stream.publish.full.document.only to false only returns the metadata without the rest, so I’ve kept it as True.
I can now see any new incoming data in my database1 collection appear in my database2 collection. The real problem in my setup was that I didn’t have a replicaSet cluster configuration for my mongo cluster.
Since readStream & writeStream require a change stream, element to follow the databases changes, which itself needs a replicaSet configuration to properly function.
Small note: data already present in the database before the stream is launched will not be picked up. My guess is that it’s because I’m using outputMode append in my writeStream.
Thanks again Robert !