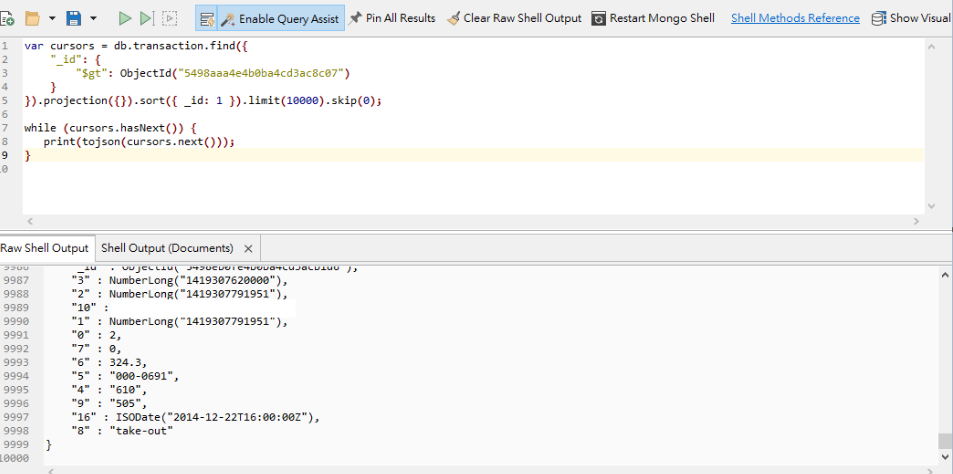
Hi, I have met an issue that querying on a large collection is really slow with java driver (~35seconds), but it can be finished almost instantly on mongo shell (~0.35second). It is really appreciated if anyone can give me some help.
The collection has around 200M rows of documents, and here is the example data
{
“0”: 1,
“1”: “1419291302798”,
“2”: “1419291302798”,
“3”: “1419291240000”,
“4”: “Code”,
“5”: “Invoice Number”,
“6”: 17,
“7”: 0,
“8”: “Transaction Type”,
“9”: “1”,
“10”: “AB123:1”,
“16”: “2014-12-22T16:00:00.000Z”,
“_id”: “5498aaa6e4b0ba4cd3ac8c08”
}
The query on mongo shell is
db.transaction.find({
“_id” : {
“$gt” : ObjectId(“5498aaa4e4b0ba4cd3ac8c07”)
}
}).projection({}).sort({_id:1}).limit(100).skip(0);
and the explain on mongo shell
"queryPlanner":{
"namespace":"db.transaction",
"indexFilterSet":false,
"parsedQuery":{
"_id":{
"$gt":“5498aaa4e4b0ba4cd3ac8c07”
}
},
"queryHash":“CF3048B0”,
"planCacheKey":“C17B2099”,
"maxIndexedOrSolutionsReached":false,
"maxIndexedAndSolutionsReached":false,
"maxScansToExplodeReached":false,
"winningPlan":{
"stage":"LIMIT",
"limitAmount":100,
"inputStage":{
"stage":"FETCH",
"inputStage":{
"stage":"IXSCAN",
"keyPattern":{
"_id":1
},
"indexName":" *id* ",
"isMultiKey":false,
"multiKeyPaths":{
"_id":[
]
},
"isUnique":true,
"isSparse":false,
"isPartial":false,
"indexVersion":2,
"direction":"forward",
"indexBounds":{
"_id":[
“(ObjectId(‘5498aaa4e4b0ba4cd3ac8c07’),
"ObjectId(‘ffffffffffffffffffffffff’)"
]"”"
]
}
}
}
},
"rejectedPlans":[
]
},
"command":{
"find":"transaction",
"filter":{
"_id":{
"$gt":“5498aaa4e4b0ba4cd3ac8c07”
}
},
"limit":100,
"singleBatch":false,
"sort":{
"_id":1
},
"projection":{
},
"$db":"db"
},
"serverInfo":{
"host":"host",
"port":27017,
"version":“5.0.4”,
"gitVersion":“62a84ede3cc9a334e8bc82160714df71e7d3a29e”
},
"serverParameters":{
"internalQueryFacetBufferSizeBytes":104857600,
"internalQueryFacetMaxOutputDocSizeBytes":104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes":104857600,
"internalDocumentSourceGroupMaxMemoryBytes":104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes":104857600,
"internalQueryProhibitBlockingMergeOnMongoS":0,
"internalQueryMaxAddToSetBytes":104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes":104857600
},
"ok":1
}
meanwhile, the java code is as followings
public List getById(String id, Integer size, Integer offset) {
long startTime = System.currentTimeMillis();
BasicDBObject criteria = new BasicDBObject();
if (id != null)
criteria.append(MongoDBUtil.key_id, new BasicDBObject(MongoDBUtil.query_greaterThan, new ObjectId(id)));
Map<String, Integer> sortCriteria = new HashMap<>();
sortCriteria.put(MongoDBUtil.key_id, MongoDBUtil.sortOrder_asc);
List mongoDBObjects = mongoDBUtil.search(MongoKeys.collection_transaction, criteria, null, sortCriteria, size, offset);
long endTime = System.currentTimeMillis();
if (showQueryTime)
log.debug("getByBrandIdNSortById DAO time: " + (endTime - startTime));
List transactions = new ArrayList<>();
if (mongoDBObjects != null && mongoDBObjects.size() > 0)
for (MongoDBObject mongoDBObject : mongoDBObjects)
transactions.add(pass(mongoDBObject));
return transactions;
}
and the search function be called
public List search(String collection, Map<String, Object> criteria, Map<String, Integer> fields, Map<String, Integer> orderBy, Integer size, Integer offset) {
BasicDBObject critObj = null;
if (criteria != null)
critObj = new BasicDBObject(criteria);
DBCursor result = null;
if (fields == null)
result = mongo.getDB(db).getCollection(collection).find(critObj);
else
result = mongo.getDB(db).getCollection(collection).find(critObj, new BasicDBObject(fields));
if (orderBy != null)
result.sort(new BasicDBObject(orderBy));
if (offset != null)
result.skip(offset);
if (size != null)
result.limit(size);
if (result != null && result.count() > 0) {
List resultList = new ArrayList();
for (DBObject obj : result.toArray())
resultList.add(new MongoDBObject((BasicBSONObject) obj));
return resultList;
} else
return null;
}
}
I guess it should be running the same query as on mongo shell?
explain from the java driver
{
"explainVersion":“1”,
"queryPlanner":{
"namespace":"db.transaction",
"indexFilterSet":false,
"parsedQuery":{
"_id":{
"$gt":{
"$oid":“54ab2697e4b0210a3c109f08”
}
}
},
"maxIndexedOrSolutionsReached":false,
"maxIndexedAndSolutionsReached":false,
"maxScansToExplodeReached":false,
"winningPlan":{
"stage":"LIMIT",
"limitAmount":10000,
"inputStage":{
"stage":"FETCH",
"inputStage":{
"stage":"IXSCAN",
"keyPattern":{
"_id":1
},
"indexName":" *id* ",
"isMultiKey":false
},
"isUnique":true,
"isSparse":false,
"isPartial":false,
"indexVersion":2,
"direction":"forward",
"indexBounds":{
"_id":[
"(ObjectId("54ab2697e4b0210a3c109f08")",
"ObjectId(""ffffffffffffffffffffffff"")"
]"
]
}
}
}
},
""rejectedPlans"":[
]
},
“executionStats”:{
“executionSuccess”:true,
“nReturned”:10000,
“executionTimeMillis”:602,
“totalKeysExamined”:10000,
“totalDocsExamined”:10000,
“executionStages”:{
“stage”:“LIMIT”,
“nReturned”:10000,
“executionTimeMillisEstimate”:575,
“works”:10001,
“advanced”:10000,
“needTime”:0,
“needYield”:0,
“saveState”:25,
“restoreState”:25,
“isEOF”:1,
“limitAmount”:10000,
“inputStage”:{
“stage”:“FETCH”,
“nReturned”:10000,
“executionTimeMillisEstimate”:575,
“works”:10000,
“advanced”:10000,
“needTime”:0,
“needYield”:0,
“saveState”:25,
“restoreState”:25,
“isEOF”:0,
“docsExamined”:10000,
“alreadyHasObj”:0,
“inputStage”:{
“stage”:“IXSCAN”,
“nReturned”:10000,
“executionTimeMillisEstimate”:6,
“works”:10000,
“advanced”:10000,
“needTime”:0,
“needYield”:0,
“saveState”:25,
“restoreState”:25,
“isEOF”:0,
“keyPattern”:{
“_id”:1
},
“indexName”:“ *id* ”,
“isMultiKey”:false,
""isUnique"":true,
""isSparse"":false,
""isPartial"":false,
""indexVersion"":2,
""direction"":""forward"",
""indexBounds"":{
""_id"":[
""(ObjectId(""54ab2697e4b0210a3c109f08"")",
"ObjectId(""ffffffffffffffffffffffff"")"
]"
]
},
""keysExamined"":10000,
""seeks"":1,
""dupsTested"":0,
""dupsDropped"":0
}
}
},
""allPlansExecution""\":[
]
},
“command”:{
“find”:“transaction”,
“filter”:{
“_id”:{
“$gt”:{
“$oid”:“54ab2697e4b0210a3c109f08”
}
}
},
“ntoreturn”:-10000,
“sort”:{
“_id”:1
}
},
“serverInfo”:{
“host”:“host”,
“port”:27017,
“version”:“5.0.4”,
“gitVersion”:“62a84ede3cc9a334e8bc82160714df71e7d3a29e”
},
“serverParameters”:{
“internalQueryFacetBufferSizeBytes”:104857600,
“internalQueryFacetMaxOutputDocSizeBytes”:104857600,
“internalLookupStageIntermediateDocumentMaxSizeBytes”:104857600,
“internalDocumentSourceGroupMaxMemoryBytes”:104857600,
“internalQueryMaxBlockingSortMemoryUsageBytes”:104857600,
“internalQueryProhibitBlockingMergeOnMongoS”:0,
“internalQueryMaxAddToSetBytes”:104857600,
“internalDocumentSourceSetWindowFieldsMaxMemoryBytes”:104857600
}
}
My spring version is 4.0.9 and mongo-java-driver 2.14.3
have tried upgrading to the latest version but had no luck to solve this problem.
I assume _id should be indexed and there is no indexing problem.
profiling log as follows
{
"op":"command",
"ns":"db.transaction",
"command":{
"count":"transaction",
"query":{
"_id":{
"$gt":“54aa7804e4b0210a3c108bf8”
}
},
"$db":"db",
"lsid":{
"id":“UUID(“2ea88fd1-7635-47c8-a8ca-a32971e49ba0”)”
}
},
"keysExamined":193236588,
"docsExamined":0,
"numYield":193236,
"queryHash":“650E7B4C”,
"planCacheKey":“70FCF2DA”,
"locks":{
"ReplicationStateTransition":{
"acquireCount":{
"w":“1”
}
},
"Global":{
"acquireCount":{
"r":“193238”
}
},
"Mutex":{
"acquireCount":{
"r":“1”
}
}
},
"flowControl":{
},
"storage":{
},
"responseLength":45,
"protocol":"op_msg",
"millis":35004,
"planSummary":"“COUNT_SCAN"{
"_id":1
},
"execStats":{
"stage":"COUNT",
"nReturned":0,
"executionTimeMillisEstimate":233,
"works":193236588,
"advanced":0,
"needTime":193236587,
"needYield":0,
"saveState":193236,
"restoreState":193236,
"isEOF":1,
"nCounted":193236587,
"nSkipped":0,
"inputStage":{
"stage":"COUNT_SCAN",
"nReturned":193236587,
"executionTimeMillisEstimate":194,
"works":193236588,
"advanced":193236587,
"needTime":0,
"needYield":0,
"saveState":193236,
"restoreState":193236,
"isEOF":1,
"keysExamined":193236588,
"keyPattern":{
"_id":1
},
"indexName":" *id* ",
"isMultiKey":false,
"multiKeyPaths":{
"_id":[
]
},
"isUnique":true,
"isSparse":false,
"isPartial":false,
"indexVersion":2,
"indexBounds":{
"startKey":{
"_id":“54aa7804e4b0210a3c108bf8”
},
"startKeyInclusive":false,
"endKey":{
"_id":"ffffffffffffffffffffffff"
},
"endKeyInclusive":true
}
}
},
"ts":"“2021-12-02T11":"19":19.880Z”,
"client":"IP",
"allUsers":[
],
"user":"
}
The machine is running on PC with specs
CPU : 5600X
Memory : 32GB RAM
HDD : WD BLUE 6TB 5400RPM
It is really only happening on my java spring application, and it’s really appreciated if anyone can give me some hints. thanks a lot and sorry for the long post