Hey @Jascha_Brinkmann,
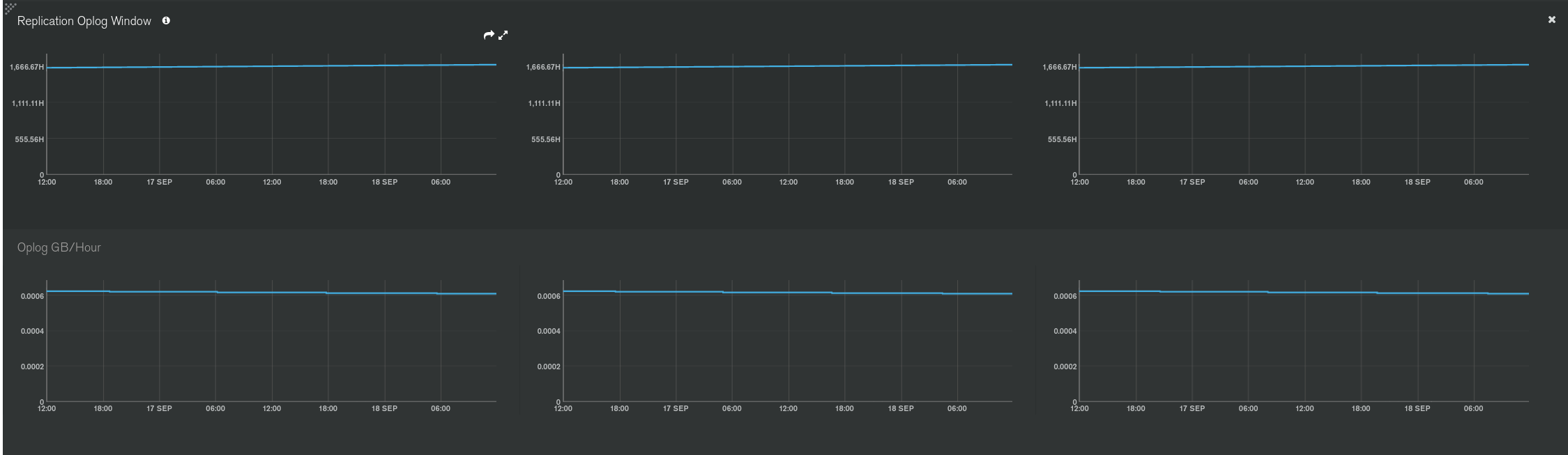
Your oplog is “only” 1GB. From what you provided here, it means that every ~30h, you write 1GB of data to MongoDB (mix of insert / update / delete operations) and each new operations is overwriting the one from 30h ago.
It’s OK as is, but could be more if you want to recover smoothly on Monday morning a node that failed at 10pm on a Friday evening.
Also if you have large batch of insertions, updates or deletions (>1GB here), that’s going to bring this down to only a few seconds (the time for the batch to execute) and suddenly, it’s not healthy at all because it means that a node will be “lost” (won’t be able to catch up) only after a few seconds of network partition or just a reboot for an OS update.
This log length start to end must be monitored and should be as large as possible.
Here are the metrics available in Atlas to monitor the Oplog:
Cheers,
Maxime