I am running a sharded MongoDB Cluster with a single shard and use change streams to listen to change evens in the database. I am getting the Following error a couple of times per day:
MongoError: Error on remote shard shard-01-01:27017 :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.
at MessageStream.messageHandler (/home/node/app/node_modules/mongodb/lib/cmap/connection.js:266:20)
at MessageStream.emit (events.js:314:20)
at MessageStream.EventEmitter.emit (domain.js:486:12)
at processIncomingData (/home/node/app/node_modules/mongodb/lib/cmap/message_stream.js:144:12)
at MessageStream._write (/home/node/app/node_modules/mongodb/lib/cmap/message_stream.js:42:5)
at writeOrBuffer (_stream_writable.js:352:12)
at MessageStream.Writable.write (_stream_writable.js:303:10)
at TLSSocket.ondata (_stream_readable.js:713:22)
at TLSSocket.emit (events.js:314:20)
at TLSSocket.EventEmitter.emit (domain.js:486:12)
at addChunk (_stream_readable.js:303:12)
at readableAddChunk (_stream_readable.js:279:9)
at TLSSocket.Readable.push (_stream_readable.js:218:10)
at TLSWrap.onStreamRead (internal/stream_base_commons.js:188:23)
Not sure what it is caused by or how to prevent it. Does anybody encountered the problem before or has any pointers?
Why use a sharded cluster with a single shard? Why not just a single replica set? Is it to be future proof because you are planning to scale or something like that?
As you have a single replica set, can you run the following command in your shard so we can have an idea of the health status of your oplog?
I suspect this is happening because you went through an election and your client is trying to restart the Change Stream but cannot because the previous known point has already been overwritten in the oplog because it’s too small.
29hrs seems plenty. Any reason why my resume point would exceed that time frame?
That being said, I haven’t seen the error within the last 24 hours. The last time I saw the error was at Wed Sep 16 2020 13:18:41 GMT+0000 (UTC) which unfortunately is now before the first event in the oplog.
So it might be possible that during peak times the log length start to end is considerable smaller than it was in the past 24 hours. I will try to check it again once I see the error.
Your oplog is “only” 1GB. From what you provided here, it means that every ~30h, you write 1GB of data to MongoDB (mix of insert / update / delete operations) and each new operations is overwriting the one from 30h ago.
It’s OK as is, but could be more if you want to recover smoothly on Monday morning a node that failed at 10pm on a Friday evening.
Also if you have large batch of insertions, updates or deletions (>1GB here), that’s going to bring this down to only a few seconds (the time for the batch to execute) and suddenly, it’s not healthy at all because it means that a node will be “lost” (won’t be able to catch up) only after a few seconds of network partition or just a reboot for an OS update.
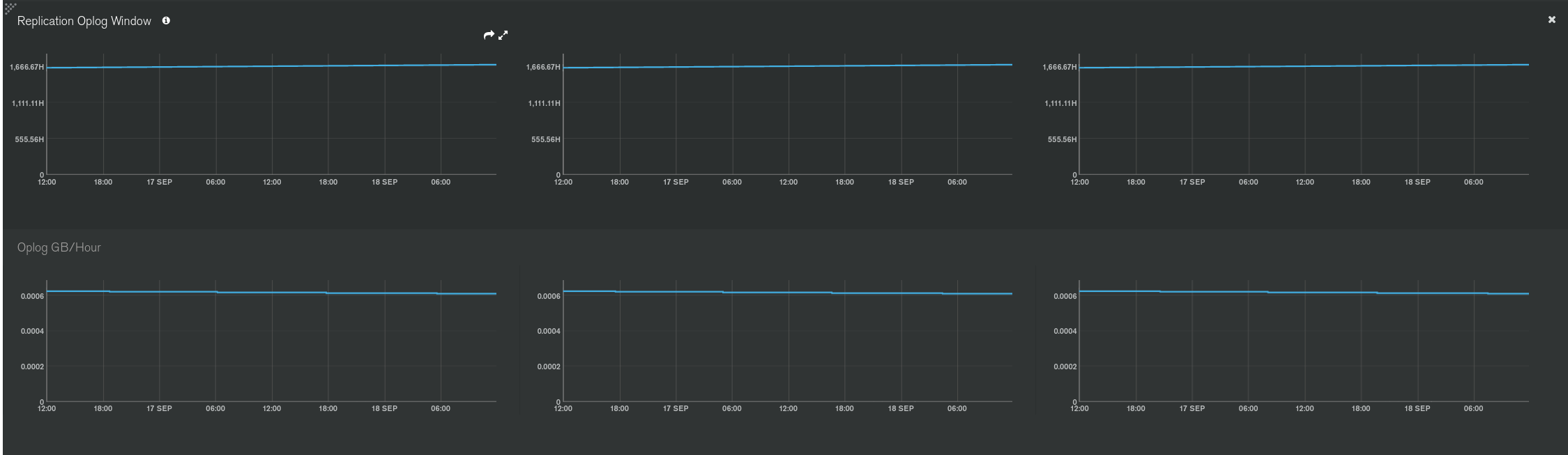
This log length start to end must be monitored and should be as large as possible.
Here are the metrics available in Atlas to monitor the Oplog:
Hi, @MaBeuLux88_xxx and @Jascha_Brinkmann !
I was also looking for a way to resolve this issue of Change Stream when the resume point is no longer in the oplog.
I understood your reply that increasing oplog size is necessary but I believe it is not that ultimate solution, because Change Stream must not lost resume point in production level. Even if I increase the size, there may be situations that much more data than I expect updates happen sometimes. What I mean is, the size I have already increased may not always be enough.
Is there any way to definitely prevent such a situation in advance?
+)
I have one more question.
If Mongo Source Connector is already stopped by the exception, how can I restart it to resume consuming Change Stream? It’s very hard to find a way to recover it with Mongo Source Connector in googling. T.T
Can you please give me some advice?
Thank you in advance.
No because you can’t keep ALL the oplog entries for ever. Else, it means that your oplog will contain every single write operation since the beginning of time and its size will increase indefinitely. You have to draw the line somewhere. It can be 1GB or 50GB or 100GB, but you need to draw a line somewhere and support this with the appropriate hardware.
I’d say that if you can find an oplog size that guarantees 1 or 2 weeks of “log length” (see rs.printReplicationInfo()), then it’s OK. But this is use case dependant so more or less could also be completely fine.
Another way to deal with this is to use new option (new in 4.4): --oplogMinRetentionHours
I never played with the MongoDB Source Connector yet, but here is some doc:
There is also a page in the doc dedicated to recover from an invalid resume token:
A resume token is the _id value of a change event. Doc here.
Here is an example in Python 3:
import pymongo
from bson.json_util import dumps
client = pymongo.MongoClient()
resume_token = {'_data': '8261AF0EDD000000022B022C0100296E5A10046803462D32FA458F8D539C1AEC72C0FC46645F6964006461AF0EDD151BABD5ABA613FA0004'}
change_stream = client.test.coll.watch(resume_after=resume_token)
for change in change_stream:
print(dumps(change))
print()
print(change_stream.resume_token)
print()