If you have 2 nodes + 3 arbiters, it means majority = 3 because you have a total of 5 nodes.
So first of all, it means you need to be able to write on 3 nodes if you use the write concern = “majority”. Which is impossible in your case so each write operations emitted with w=“majority” will fail.
Also, because majority = 3, it means that you won’t be able to elect a primary if 3 nodes are down. So for example if your 3 arbiters are down, you will be stuck with 2 secondaries that are not able to elect a primary. This would not happen if you had only one arbiter because the majority would be at 2 so they would be able to elect a primary.
Arbiters in general are not recommended. The minimum configuration that MongoDB Atlas is deploying is 3 nodes RS with P+S+S.
If you use a P+S+A, it means you can only write on 2 machines. If something happens to the P or the S, it means that you are now only able to write to one machine which means that all the write operation with w=“majority” will fail. So P+S+A is not HA for durable write operations (ie using w=“majority”).
With P+S+S, you can continue to write with w=“majority” if you lose one machine (any of them).
With P+S+A, you can continue to write with w=“majority” only if you lose the A so it means your P & S are weak points.
I don’t understand what is your motivation for using more than one arbiter. Can you please explain why you are considering 3? It’s only more troubles. Zero arbiter is the best way to go.
With P+S+S, you can take one machine out for maintenance, backups and rolling upgrades and still accept durable write operations.
With P+S+A, you can’t afford to do this.
In summary, if there is no “write” concern of majority, then there shouldn’t be any worry overall.
In our case, we have a 3 node High Availability Managing cluster, that we wanted to re-purpose with 27017 port allotted for arbiters. That way we will be able to handle the HA of Mongo as well, with the existing machines without deploying new nodes ONLY for arbiter.
Also I got your feedback on the P+S+S again based on the write concern. As I mentioned we were using Single node anyways for the existing system where we were not using the write concern anyways.
Also definitely we won’t run into the situation of all Arbiter nodes being down at the same time.
In summary the proposal for 3 arbiter nodes is for consistency on the High Availability nodes (from a deployment stand-point) and nothing else.
Please let me know if we should be considering any other factors for our case, other than write concern.
An arbiter is only required when you’re running an even number of MongoDB nodes in a replica set, to round up the number of instances to an odd number, which is required for quorum. Running more than one arbiter doesn’t add any benefit. It doesn’t increase consistency, but it does add needless complexity to your cluster.
Running more than one arbiter means you cannot use majority write concern with your cluster (as @MaBeuLux88_xxx mentioned already). Unless you’re okay with losing data, or with downtime, you should use majority write concern, and you should have at least 3 full mongod nodes in your cluster.
Having more than 1 arbiter is useless / doesn’t make sense.
It’s not supported nor tested.
It deteriorates the majority. MongoDB replica set maintain the “majority commit point” up to date which is the latest write operation that has been acknowledged by the majority of the data bearing nodes. If the majority commit point can’t move forward, the primary will keep 100% of the versions of 100% of the data in cache which will overflow at some point (swap). Even worst, ALL the data not majority-committed will be checked by the eviction server which will make the cache purge go more and more slowly as you go. So even for a setup like a PSSAA, if you happen to lose a S, it will prevent the primary from moving the majority commit point forward and cause a big cache pressure on the 2 remaining nodes. PSAAA simply doesn’t work as the majority commit point can NEVER move forward as the majority of data bearing nodes can never be reached.
There is no advantage to it, ever. None. I don’t know what consistency with your other system even means, but it’s a non-reason - your other system isn’t a three arbiter system so there is no consistency.
Thanks a lot Max and Mark for your detailed replies. And Stennie too.!
Asya, I agree with your team’s thoughts as you are the experts in this area.
To make this thread complete, also wanted to share more details on our thoughts and reasoning around our proposal.
The failover and High Availability is maintained in general by a set of servers outside of the actual data nodes. An example could be Sentinel monitoring for Redis, Or Zookeeper monitoring for Solr/Kafka etc.
The difference with Mongo is that the data nodes also participate in the voting which is different than the systems mentioned above.
We have a high availability setup of 3 nodes, that generally monitors the data nodes as mentioned above.
So we thought we would fit in the arbiters as well into the three nodes of High availability cluster, to keep the installation consistent in our High Availability cluster nodes.
But we realized late that Mongo doesn’t work this way as the data nodes (primary and secondary) also participate in voting process.
As you guys suggested, we will trade-off the write concern to the deploying of additional hardware. We will have the decision made on this by next week and will keep you posted on the decision progress.
Many thanks again for all your help and guidance on this. Truly insightful every feedback.
We have been testing more combinations of fail-over and arbiter combinations of 1 and 3.
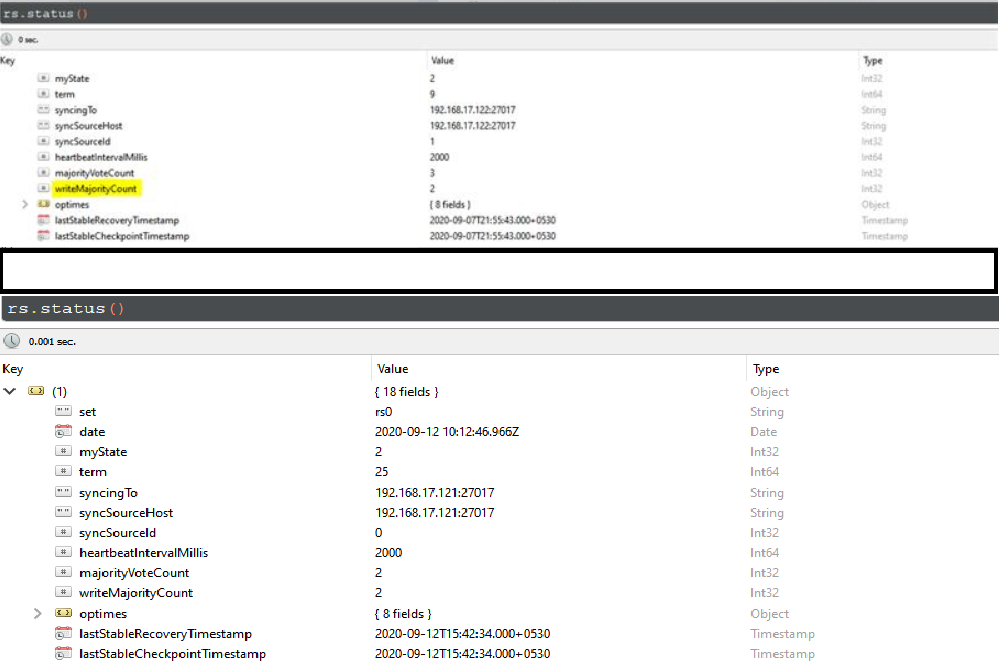
The main observation that stood out is, writeMajority is not affected by the number of arbiter nodes. i.e. if there are two data nodes, P and S, then the writeMajority is always 2, even if Arbiters are 1 or 3.
Only difference as you pointed out, majorityvotecount would be 2 for the replicaset if there is only 1 arbiter, while it would be 3 if there are a total of 5 nodes (including 3 arbiters).
Also the statement PSAAA won’t move forward is not true, as the number of data bearing nodes is unchanged from 2 irrespective of 1 arbiter or 3 arbiters.
Also the hypothetical situation you mentioned that all 3 arbiter nodes might be down, would still be possible even for the single arbiter as well. So there’s no difference.
Sorry for the persistence on this. But we need to vet this down to ensure there are no shortcomings in our testing.
If you have 1 arbiter and it’s down you still have majority (two data nodes). If you have three arbiters and they are down you no longer have majority (as majority is 3).
While this is definitely a fetching point for a single arbiter based, this is a hypothetical situation that all three arbiter nodes would be down at the same time.
On the contrary, if the primary is also down, obviously the three node PSA cannot recover and elect a new primary with single Secondary alone alive in the ReplicaSet. However if a single arbiter is down and primary is also down, the remaining two arbiters along with Secondary, can make Secondary as primary, and hence enabling the better stability and availability for the ReplicaSet.
In both the cases, I have clarified with the images above, on writeMajorityCount being unchanged from 2 (with PSAAA and PSA). While majorityVoteCount is changed from 3 to 2 when it is PSAAA and PSA.
Thanks again and hope the above explains the better reliability with PSAAA.
In the case of the PSAAA you explained above, you actually do NOT want your S to become P because you are actually creating a potential massive rollback.
Let’s compare side by side PSA and PSAAA.
Let’s start with PSAAA.
One Arbiter goes down.
You need to stop your S for maintenance or backup (automated at midnight). Or maybe your S just goes down for some reason.
Meanwhile, your P continues to accept write operations for 2 hours because P+A+A = majority.
Your P goes down as well.
Your boss starts yelling because the “high available system” is down…
You panic and restart the former S. S+A+A = majority = election.
Your old S is now P.
You start accepting write operations.
You restart the old P. It joins the cluster as a S after rollbacking all the 2 hours of write operations he did earlier.
2 hours worth of write operations are in your rollback folder in your old P. Some of them are likely conflicting with new write operations in the new P.
You explain to your boss that each single write operations need to be investigated VS the new version of the database manually.
As you have 1000 writes per sec = 3600*1000 = 3 600 000 operations to check manually.
Boss is mad.
You get fired.
Now the PSA.
The arbiter is down.
You need to stop your S for maintenance or backup (automated at midnight). Or maybe your S just goes down for some reason.
Your P detects that the majority of nodes can’t be reached (as A+S are down) and immediately stops accepting write operations and steps down into a S.
Your boss starts yelling because the “high available system” is down…
You panic and restart whatever you want (S or A).
Your P and S oplogs are already in sync. Whichever node becomes primary already has the latest version of the data.
Boss isn’t mad.
You are not fired.
Of course my little story is a little “worst case scenario”. This kind of troubles could also happen with network partitioning.
But MongoDB was designed to sustain the worst case scenarios already. One arbiter is already NOT recommended (cf the doc above).
Having one arbiter already increases your “chances” to be rollbacked. As I demonstrated above, with similar issues and more arbiters, you actually increased your chances of being rollbacked.
Writing with w=“majority” is recommended if you want to avoid a potential rollback of your data but this is only achievable if you use 3 data bearing servers because using a PSA in this scenario would not make your replica set highly available.
I really hope this helps !
If you want to have a more robust and forward looking replica set, I would definitely recommend a PSS rather than a PSAAA which may even cost more $ in the end as you can’t regroup these machines of course.
With a PSS, you would have more room for maintenance and backup operations. It would be easier to take down a node and keep accepting w=“majority” writes in the meantime so rollback operations would be definitely out of the table in every possible scenarios.
Thanks again and hope the above explains the better reliability with PSAAA.
It does not. PSAAA is not more reliable, it’s borderline unsupported. We do not expect anyone to be using multiple arbiters except as an extremely transient situation (I can just barely see maybe needing something like that when doing some major moving of nodes in a cluster but that would be a one time thing).
While it’s unlikely for any three nodes to be down at once in a cluster, what’s not unlikely are network partitions. So if you have PSA no matter how they get partitioned (two on one side, one on the other side) the side that has two nodes will be able to elect a primary. If you have PSAAA then any partition that leaves P and S partitioned from the arbiters will not be able to elect a primary on either side of the partition.
Adding more arbiters gains you nothing but it creates new complex scenarios that may fail in unpredictable ways.
You have multiple mongodb employees, some of them extremely experienced, explaining why you should not do this. You should take this advise.
Adding a non-employee voice to the mix:
Your first second and third options for a replicaSet should be 3 data nodes. Only do a PSA as a last resort.
If I came across the monstrosity you propose the first order of business would be tearing it down to a PSA and prioritising making the remaining arbiter a data node.
To summarize the feedback (preferred options are with regards to reliability):
#1 preferred option - PSS
Pros: No impact to RS with any node failures and no concerns to write acknowledgements overall, and can sustain network partitioning without any issues
Cons: 3x h/w costs (cpu, memory) as compared to single node
#2 preferred option - PSA
Pros: No impact to overall RS with any node failures
Cons: Inconsistent topology with two data bearing nodes and one voting node (arbiter), and there are impacts of network partitioning
#3 preferred option - PSAAA
Pros: Low overall cost involved (of course this is our specific case, and shouldn’t be generalized)
Cons: Less reliable for network partitioning cases.
Also specific to our case, From #3 to #1 the reliability increases and so is the cost. We will have this reviewed along with our team and let you know if there are follow-up questions.
As I mentioned earlier, this is specific to our case as we planned to repurpose the hardware, hence the reason for low cost (also inherently bringing the advantage of consistency) without deploying a new node. If you read the above thread, you will find those details.
Hi Mark, the challenge with that for us is we use automation for some of the vm deployments and we wanted to keep those set of high availability ensuring vms as consistent, which will simplify the deployment process.
As I said, we are reviewing these options and would follow-up if there are any other questions.
Thanks again for pitching in and providing your thoughts.