I noticed the following behavior:
When a new collection is made, by default a unique index over the _id field is made. This index maps between the _id field to an auto generated reference that points to the relevant document in the main btree containing the actual documents for the collection.
So while the index is sorted by the _id field, the documents on disk are actually sorted by the order in which they were inserted, and not by any user-controlled key (for example the user could choose to write his own _id field)
Therefore, any range query, such as - “calculate the total account balances of users that start with the letter ‘b’” Will have to go over an index mapping user names to documents, and for all documents of users that start with “b” (which is a sequential range read within the index) will read the relevant documents from the main collection tree but not in sequential order.
Therefore it seems MongoDB by default doesn’t use disk sequential reads to accelerate range queries by user-key.
My questions are:
Is that always the case that documents are not sorted on disk by the order of some user key?
if 1 is false - how can this be done? even in capped collections the data is maintained by insertion order and not user key, and the _id unique index exists (According to docs)
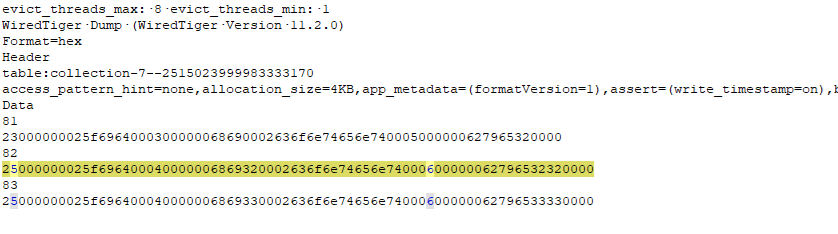
I have created a normal collection, inserted some documents and looked at the data files. Each data file is a sorted Btree mapping between some keys and some values. The data file for the unique index of the _id (I have overwritten it to be my own user key) mapped between the _id and a seemingly auto-generated and ever increasing reference to the main data file. The data file for the actual documents themselves, used those references as the key, and the documents themselves as values. The following is a dump of the document file. Each two lines contain the reference as key and the respective document BSON as value
true, but within each btree “block” (page) the documents are sorted by the key that mongoDB chose to use when storing them, in this case the auto-generated reference (i.e. by insertion order). Default block size is 32K, so it is still much better to read 32K sequential chunks containing several documents at once than reading each one on its own when doing the range query. because the order of the documents in the pages is not by the user-key they will not reside on the same blocks.