i am trying to see if there is a way to do this within a notebook.
pyspark --conf “spark.mongodb.input.uri=mongodb://localhost:27017/db.coll?readPreference=primaryPreferred”
–conf “spark.mongodb.output.uri=mongodb://localhost:27017/db.coll”
–packages org.mongodb.spark:mongo-spark-connector_2.12:3.0.1
from my notebook, i have this:
spark = SparkSession
.builder
.appName(“spark”)
.config(‘spark.driver.memory’, ‘32g’)
.config(“spark.mongodb.input.uri”, “mongodb://localhost:27017/collection.coll”)
.config(“spark.mongodb.output.uri”, “mongodb://localhost:27017/collection.coll”)
.config(“spark.mongodb.output.database”, “db”)
.enableHiveSupport()
.getOrCreate()
i create my dataframe with no issue. but when i try to write it to mongo with this command:
df2.write.format(“mongo”).mode(‘overwrite’).save()
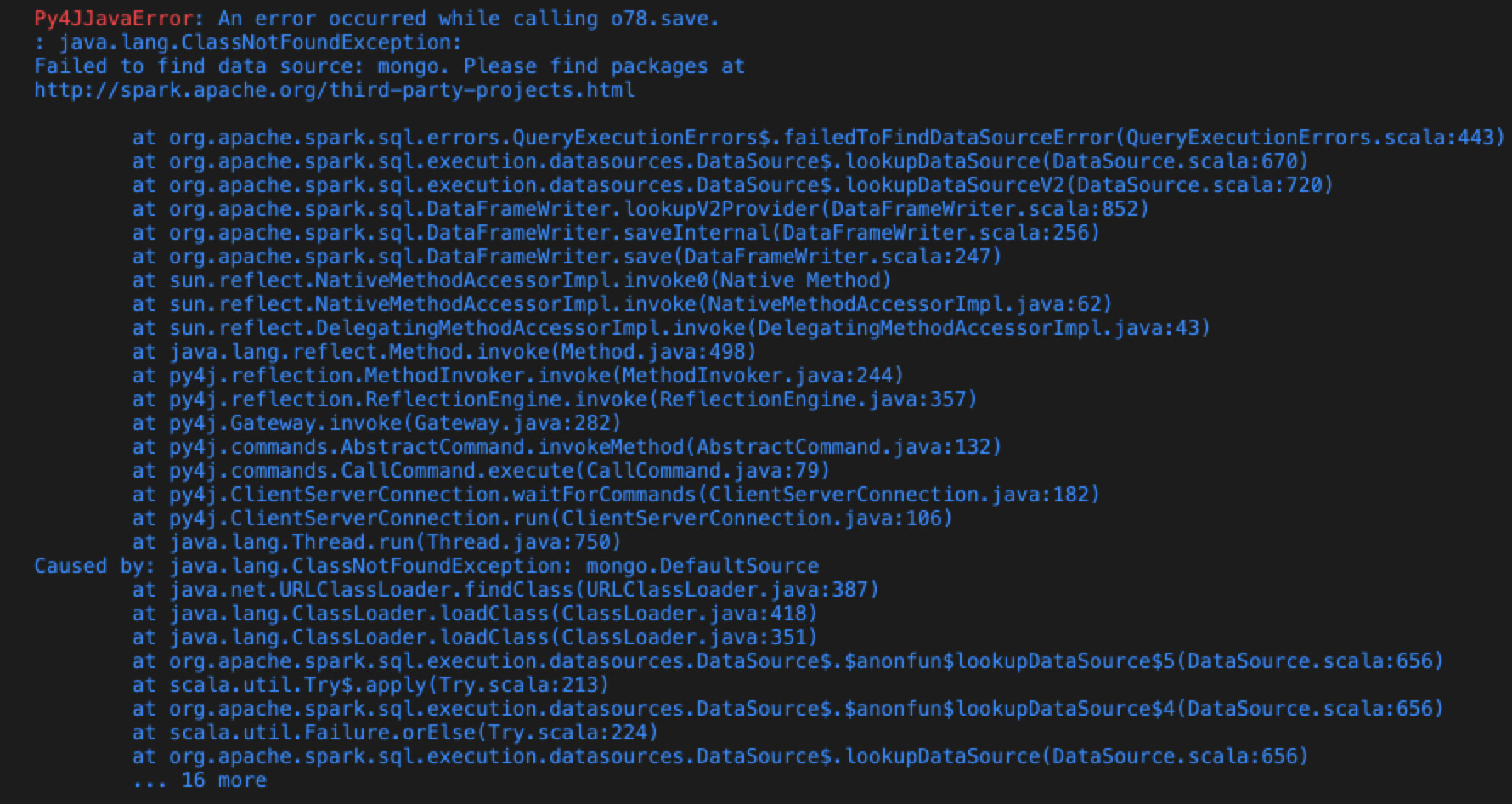
directly from pyspark directly
>>> df2.write.format("mongo").mode('overwrite').save() 22/03/21 00:14:09 WARN CSVHeaderChecker: CSV header does not conform to the schema. Header: ID, SPEED, TRAVEL_TIME, STATUS, DATA_AS_OF, LINK_ID, LINK_POINTS, ENCODED_POLY_LINE, ENCODED_POLY_LINE_LVLS, OWNER, TRANSCOM_ID, BOROUGH, LINK_NAME Schema: ID, Speed, TravelTime, Status, timedate, LinkId, LinkPoints, EncodedLinkPoints, EncodedPolyLineLvls, Owner, TranscomId, Borough, Link_Name Expected: TravelTime but found: TRAVEL_TIME
any suggestions?