Hi @Thomas_Bianchi and welcome in the MongoDB Community  !
!
I think it would be more efficient to lookup from users => messages rather than do a lookup from messages => users and then do a match to eliminate all the messages without a user with a phone number.
That way, you are not joining 2.5M docs and then eliminate a bunch of them.
Let me illustrate with an example. I made a little script in Python to generate a fake database. 50% of the users have a phone number (1 => 50).
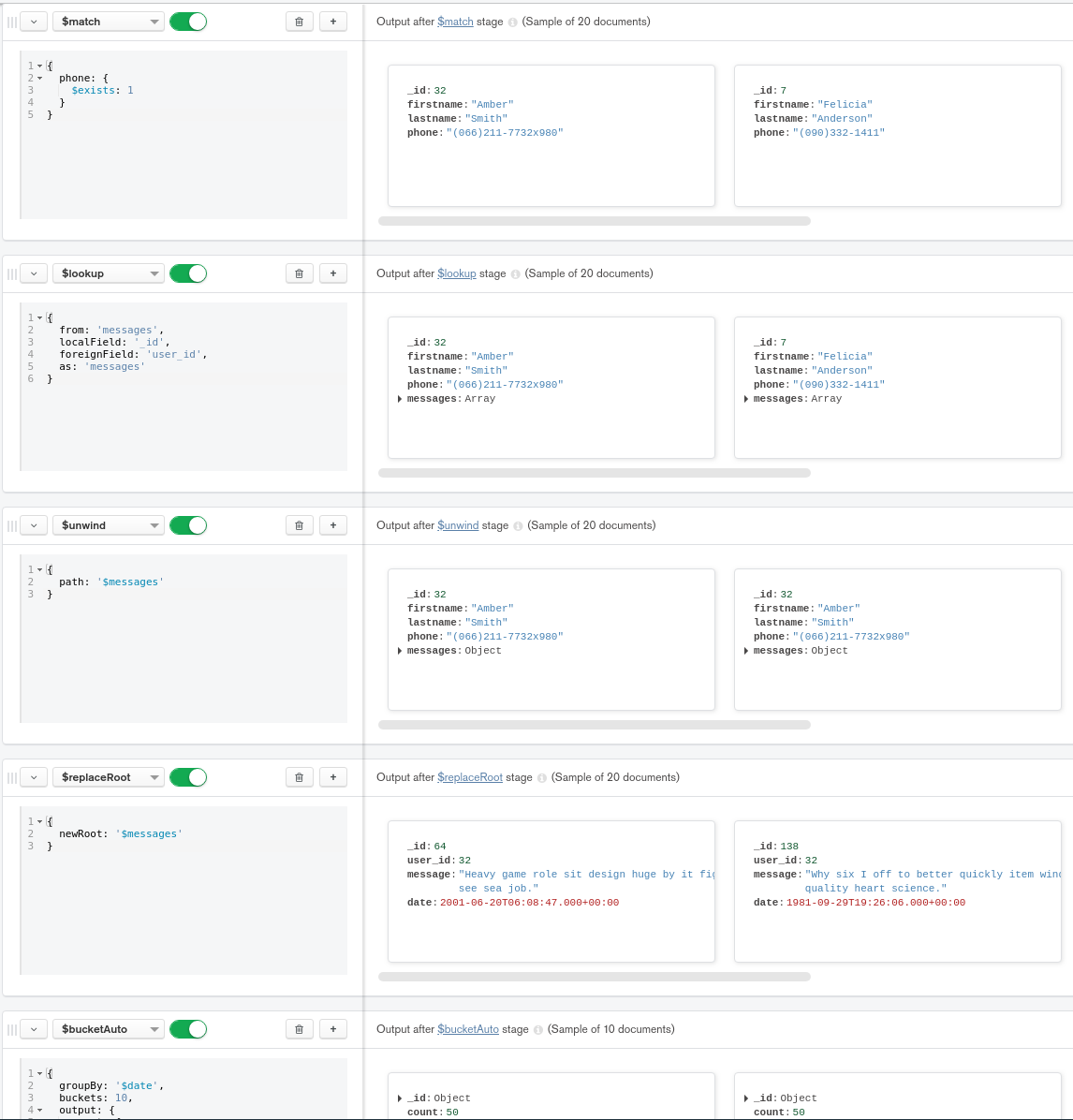
At the end, I’m also executing my pipeline and I’m showing the results in 10 date buckets. As you can see below, I’m doing:
- $match => exists phone (it uses the index
{phone:1})
- $lookup => fetch the messages associated to a user with a phone number.
- Then you can do whatever you need to shape the data the way you need it for your chart. Some of my steps are not necessary in my pipeline I guess but it helped me thinking in MongoDB Compass (see screenshot).
Note that to support the lookup, I also created the {user_id:1} index on the messages collection.
from datetime import datetime
from faker import Faker
from pymongo import MongoClient
fake = Faker()
def random_messages():
docs = []
for _id in range(1, 1001):
doc = {
'_id': _id,
'user_id': fake.pyint(min_value=1, max_value=100),
'message': fake.sentence(nb_words=10),
'date': datetime.strptime(fake.iso8601(), "%Y-%m-%dT%H:%M:%S")
}
docs.append(doc)
return docs
def random_users_with_phones():
docs = []
for _id in range(1, 50):
doc = {
'_id': _id,
'firstname': fake.first_name(),
'lastname': fake.last_name(),
'phone': fake.phone_number()
}
docs.append(doc)
return docs
def random_users_without_phones():
docs = []
for _id in range(51, 101):
doc = {
'_id': _id,
'firstname': fake.first_name(),
'lastname': fake.last_name()
}
docs.append(doc)
return docs
if __name__ == '__main__':
client = MongoClient()
db = client.get_database('test')
messages = db.get_collection('messages')
users = db.get_collection('users')
messages.drop()
users.drop()
messages.insert_many(random_messages())
users.insert_many(random_users_with_phones())
users.insert_many(random_users_without_phones())
print('Import done!')
users.create_index("phone")
messages.create_index("user_id")
pipeline = [
{
'$match': {
'phone': {
'$exists': 1
}
}
}, {
'$lookup': {
'from': 'messages',
'localField': '_id',
'foreignField': 'user_id',
'as': 'messages'
}
}, {
'$unwind': {
'path': '$messages'
}
}, {
'$replaceRoot': {
'newRoot': '$messages'
}
}, {
'$bucketAuto': {
'groupBy': '$date',
'buckets': 10,
'output': {
'count': {
'$sum': 1
}
}
}
}
]
print('Result aggregation:')
for doc in users.aggregate(pipeline):
print(doc)
I hope it helps  .
.
Cheers,
Maxime.