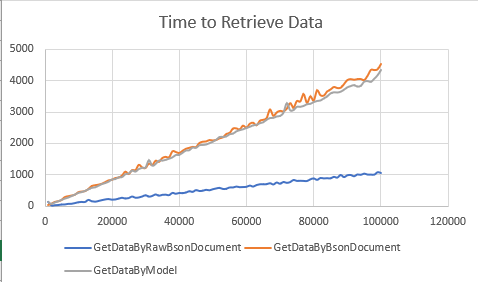
Out of interest how long does the generation routine take on your machine? It’s taking a long time to run on my workstation with local mongo.
Debugging it seems that nearly all of the time is the re-creation of the faker class within each function call.
Not using the faker, takes about 10ms to create 100 data points, with faker takes about 500ms per 100.
Pulling the faker class outside the loop and passing into the generation routines takes about the same (10ms) so spinning up a faker class is REALLY expensive:
.RuleFor(x => x.GrossProfitWoReturn_TMC_Spec, f => f.Random.Double(0, 2000));
var faker = new Faker();
var issueDate = GenIssueDate(faker);
s.IssueDate = issueDate.IssueDate;
s.IssueYear = issueDate.IssueYear;
private static (DateTime IssueDate, int IssueYear, string IssueMonth, string IssueQuater) GenIssueDate(Faker faker)
{
var issueDate = faker.Date.Between(new DateTime(2012, 1, 1), DateTime.Now);
int issueYear = issueDate.Year;
string issueMonth = issueDate.Month.ToString().PadLeft(2, '0');
string issueQuater = ConvertMonthToQuater(issueDate.Month);
return (issueDate, issueYear, issueMonth, issueQuater);
}
Example without faker class:
private static (DateTime IssueDate, int IssueYear, string IssueMonth, string IssueQuater) GenIssueDate2()
{
int range = (DateTime.Now - new DateTime(2012, 1, 1)).Days;
var issueDate = DateTime.Now.AddDays(_random.Next(range));
int issueYear = issueDate.Year;
string issueMonth = issueDate.Month.ToString().PadLeft(2, '0');
string issueQuater = ConvertMonthToQuater(issueDate.Month);
return (issueDate, issueYear, issueMonth, issueQuater);
}
private static (int Qty, decimal UnitCost, decimal Amount, decimal AmountLocalCurrency) GenSalesCost2()
{
var qty = _random.Next(2000);
var unitCost = _random.Next(2000);
var amount = qty * unitCost;
var amountLocalCurrency = amount * (0.5m + (decimal)_random.NextDouble() * 30m);
return (qty, unitCost, amount, amountLocalCurrency);
}
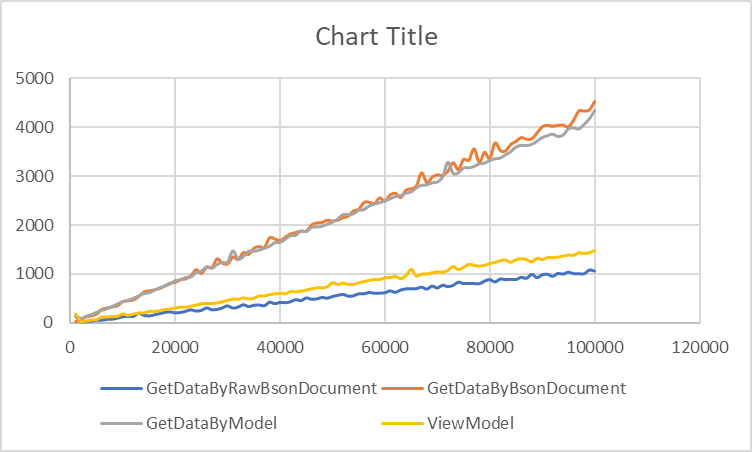
Shall take a look at the retrieval code next.