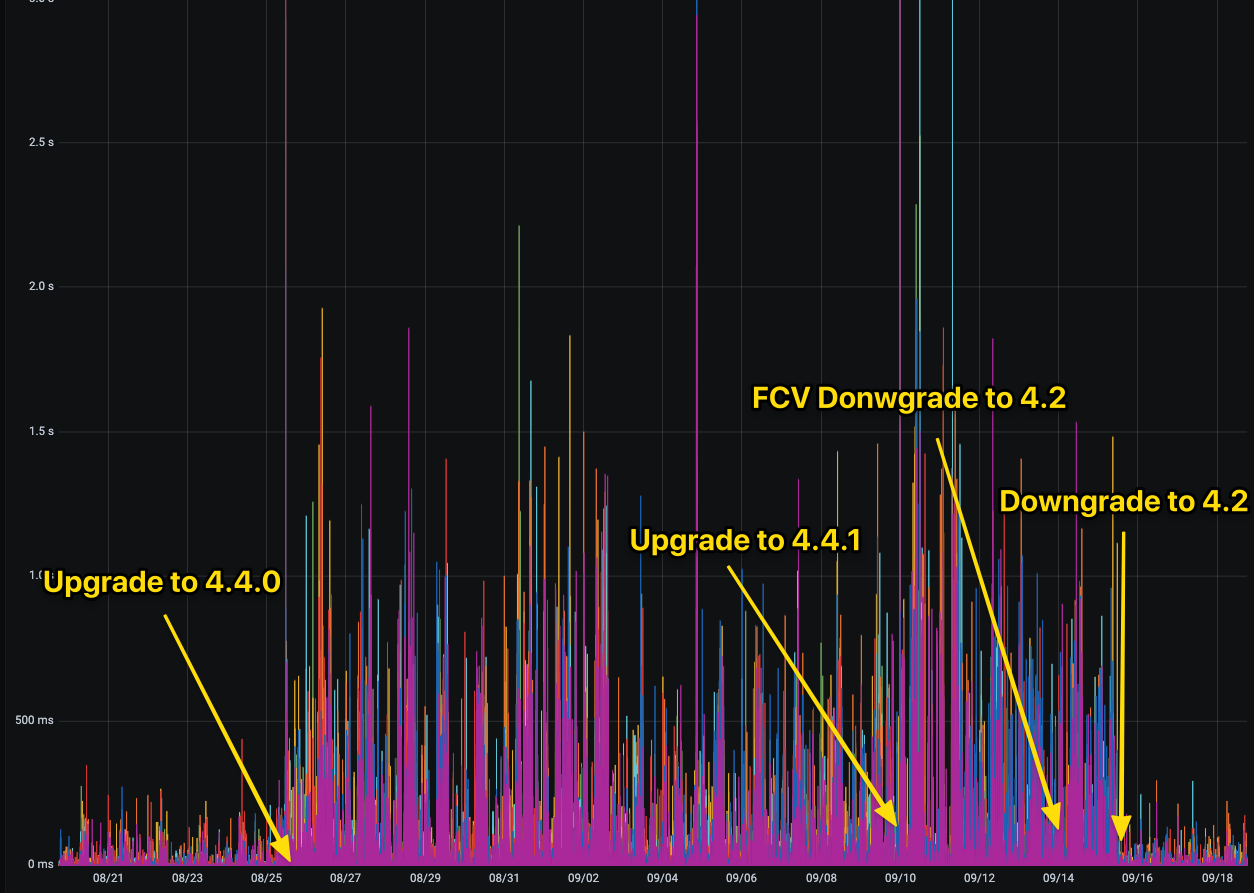
Our MongoDB deployment looks like this: 6x mongos instances (n1-highcpu-8), 3x config instances (n1-standard-1), 15 (shards) *3 (replica members) mongod instances (n1-highmem-16). Hosted on a GCP cloud. After upgrading to 4.4, we noticed immediate performance degradation across the entire system. Even queries by sharding key, which returns one document from the small collection (~30k documents), started to degrade in performance. For example, we saw cases where log entry on the mongos side says that the Slow query took 6-7 sec, but we have nothing on the mongod side which means, that query took less than 100ms. We tried to find bottlenecks, tried to temporarily resize instances, add more mongos instances, but the results were the same. Then the 4.4.1 version came out, but the upgrade didn’t change anything. So we decided to downgrade to the 4.2 release. At this time, we monitored various system parts as downgrade was performed. And the performance was back as soon as we restarted mongos instances with the 4.2 binaries and stayed at the same levels as we downgraded all the shards one by one.
An interesting thing, that basic server metrics like CPU, Load, Memory, Disk Activity didn’t change at all during upgrade and downgrade. Just mongos instances became slower with version 4.4 for some reason.
Any ideas what could slow down mongos instances so much? May others experienced something like this?
Is this on MongoDB Atlas or are you running your own cluster on MongoDB?
It is our own cluster with a community version. OS Ubuntu 18.04 installed by extracting binaries from tgz.
I spoke to our engineering team. They recommend raising a SERVER ticket on our JIRA system.
Hi Žygimantas Stauga and welcome to the new community forums! I’d very much like to learn more about your performance issue – please let me know if you have any issues filing a SERVER project ticket.
Thanks
Dan
Hi, sorry for the late response. Just did it: https://jira.mongodb.org/browse/SERVER-51104
Thanks! We’ll follow up on the ticket.
hi all,
we encountered the same performance degradation with version 4.4.3, so we downgraded to 4.2.12 and things run fine again.
I see no evolution anymore in this SERVER ticket #51104 since Jan-27 this year from David Gotlieb, it’s status is “Waiting for user input” . What input does that user need to provice? About the situation with 44.3 ? Cos we were running 4.4.3 and had the exact same issue.
I see that the currently latest available version is 4.4.4 but hard to figure out from its release notes if anything relevant has been changed or fixed with regards to this (quote David Gotlieb) “internal to MongoDB cluster communication” problem.
Does someone have any update, please ?
brgds
Rob
Hi Rob,
Although it’s possible that you are experiencing the same issue, we never found a root cause for that issue. It seemed possible that the original ticket was around DNS resolution in sharded cluster, but was not confirmed and the original reporter stopped providing information. I’d very much like to get to the bottom of your issue – would it be possible to create a new SERVER ticket describing your issue which includes log files and FTDC files?
Dan
hi Dan,
thx for your comment!
We currently run 4.2.12 and thus to provide a clear description of this issue under 4.4.x with logfiles and FTDC files, obviously requires that we upgrade the entire cluster again. This would be an action of which we currently do not yet feel very confident that it would lead to a stable and performant situation.
On top of that, during our previous downgrade we encountered a corrupted (14TB…) database due to FCV issues.
Needless to say that we want first to very carefully study the upgrade path to ensure that we keep a reliable downgrade option open.
I will keep this post updated of any progress from our side.
brgds
Rob
I totally understand your reluctance to upgrade until you see some progress on this issue. If your downgrade was less than one week ago, you may still have the forensic data (FTDC an log files) needed to do an analysis. If it was longer than that, it will be difficult to do much.
The side note about a corrupted database due to FCV issues did pique my curiousity – if you have any more information about that issue please file a ticket.
Hello, Any updates on upgrading 4.4, as I also had same issue. Also I would like to understand how to use mtools with these new logs