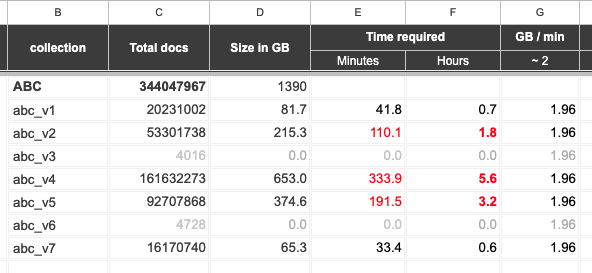
There is a collection ABC with ~350 Millions documents.
I want to partition ABC based on one key that has 7 unique values (say - v1, v2, v3, v4, v5, v6, v7) throughout the collection.
I.e. Want to partition ABC into 7 different collections (abc_v1, abc_v2, abc_v3, abc_v4, abc_v5, abc_v6, abc_v7)
I don’t want to go for sharding as it will double the cost & we have not reached to that level yet.
I can easily sustain for next 2 years if we are partitioning the ABC into 7 different collections.
I have completed a POC on taking query based mongodump & restore it into the separate collection.
i.e. I took a query based mongodump (for all the docs of that has v1) & restored it into abc_v1.
I did the same 7 times. I have attached the image of POC result.
I tried mongodump, mongoexport, $out/$merge - out of all mongodump is giving me better result but that is not enough as even mongodump/restore is taking huge time.
am I doing something wrong or what is the optimised way to partition such huge collection?
Each collection needs at least 2 files. So for this single collection will go from 2 files to 14 files for the same data. Your code will not be more complicated because it will have to determine which collection to query. You gonna use more resources for the same amount of data. What is your goal?
We have 13 indexes as we can’t fire a single query without index so I can’t reduce the indexes.
That it affecting on writes (insert/update) a lot.
As of now all the insert, updates & reads are happening based on 7 unique values only so instead of firing query on ABC with {“field_3”: v1} we can fire it on abc_v1 collection
See we have very clear sight on
coding
complexity
resource utilisation
expected read/write throughput
I am looking for optimised way to split 1 collection into 7 collections.
Will the 13 indexes still exist in the 7 partitioned collections? If the 13 indexes still exist in each collection, then you end up with 91 indexes and files. Updating an index is O(log n) so if you still update 13 indexes per collection you are roughly looking at the same amount of work.
Your splitting has some potential performance improvement if and only if you can eliminate some indexes for some of the collections. For example, abc_v4 might not need all the 13 original indexes, so an update on abc_v4 will touch less indexes. This is assuming that some indexes are not needed for abc_v4.
If you think that updating indexes is the culprit, then optimizing the indexes might be a better avenue. Since all your queries including field_3 with a specific value (v1 to v7), field_3 is probably (should be) present in all indexes. One way to reduce the number of indexes to update is to have more indexes but partial indexes. This is with, again, assuming that some indexes are not needed for some collections. The partialFilterExpression will be on field_3. Basically, you would partition the indexes without partitioning the data.
I am surprised that
compared to $out/$merge as there is extra disk I/O involve with mongodump/restore and potentially network I/O if mongodump/restore is performed from another machine. I think $merge will be a very bad choice for your use-case since it compares existing documents, while $out does not perform this check. I really cannot understand how dump/restore could be faster than $out. So if your performance numbers are based on $merge rather than $out, then you should revise them. What ever path you choose create your indexes after the partitioning.
As I wrote disk I/O above, I thought that partitioning per database rather than per collection could be much better as you could leverage the directoryPerDB option where you make each database directory be a symlink to 7 different disks.
7 partitioned collections will have 2-4 indexes/collection & there will be a huge performance improvement.
We have already created 7 collections & added 1 document in it with required indexes such that when we insert documents into the collection, mongodb will take care of updating/sorting the indexes as per the newly inserted documents.
Partial indexes -
Earlier I thought to create partial indexes only but you can consider -
with partial index we will improve performance by 2x without flexibility
with partitioning we will improve performance by 3x with huge flexibility for the individual collection.
It’s quite difficult to explain it here why partition is the best & suitable way to fullfill all our requirements.
We have deployed ATLAS Cluster on AWS & we have created a large EC2 instance (to mongo dump/restore) in the same region.
I think that’s the reason network latency is not there in case of mongo dump/restore.
I didn’t understand how mongo dump/restore will take more IOPS as compare to $out?
I mean in both the cases (mongo dump/restore & $out) we are reading the same data & writing into the separate collections.
I might have wrongly assume that your mongodump is written to disk and mongorestore read from disk, hence more disk I/O.
But still, with $out you only have mongod doing all the work. With mongodump/restore, you will have 3 processes so 3 times the amount of context switch. With $out the data stays on the server, with dump/restore data is exchanged from mongod to mongodump, then from mongodump to mongorestore and finally from mongorestore to mongod. That is a lot of extra IPC compared to $out. So I am really surprised. But that is the thing about performances, our intuition is often wrong.