Hi,
I migrate my application from Jboss to Spring Boot. I use the spring ReactiveMongoTemplate (in both jboss and Springboot) bean that requires a new version of mongodb-driver-core dependency.
FYI, I dont have any problem with the Jboss version but it seems a memory leak with the Spring Boot version
I have tried to play with minPoolSize and maxPoolSize but no matter the configuration, I always have always the same problem with my Spring Boot app.
Here is the difference:
mongodb-driver-core:3.12.2 with jboss (no problem after injecting 50 query/sec during 10 minutes)
mongodb-driver-core:4.6.1 witj spring boot(Java heap space after injecting 50 query/sec during 2 minutes)
I notice that the async code has a lot of change beetween the two versions.
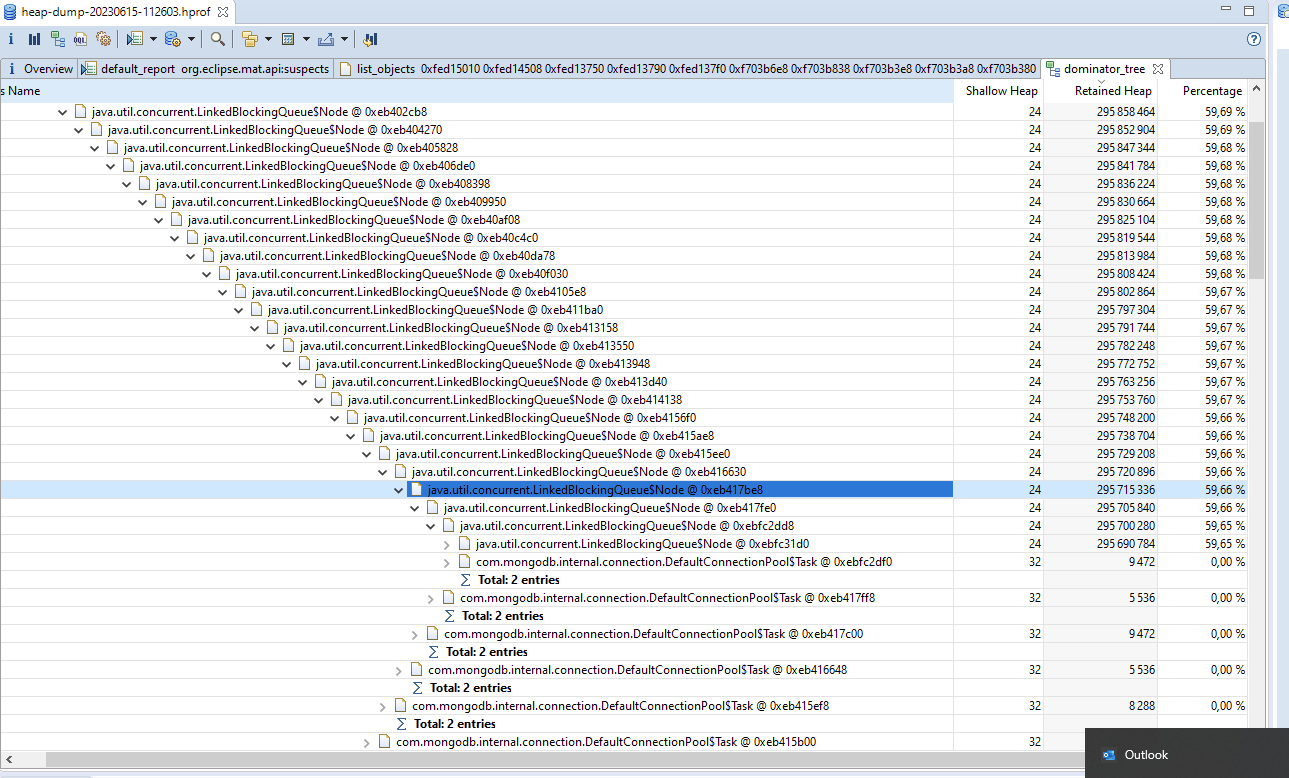
In my heap dump i see a lot of ``LinkedBlockingQueue` instances.
Leak Suspects
One instance of “com.mongodb.internal.connection.DefaultConnectionPool$AsyncWorkManager” loaded by “jdk.internal.loader.ClassLoaders$AppClassLoader @ 0xe085d958” occupies 295?880?152 (59,69 %) bytes.
Keywords
com.mongodb.internal.connection.DefaultConnectionPool$AsyncWorkManager
jdk.internal.loader.ClassLoaders$AppClassLoader @ 0xe085d958
Is there a bug in the driver or do I need to add configuration to support the same load as on my jboss instance?
Here is the application code sample (same on jboss and springboot version):
import com.myCorp.model.MediaStatusRepository;
import com.myCorp.model.PushStatus;
import org.springframework.data.mongodb.core.ReactiveMongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import javax.inject.Inject;
import javax.inject.Named;
@Component
@Named("myRepository")
public class MyMongoMongoRepository {
private static final String COLLECTION_NAME = "my_collection";
private static final int LIMIT = 50;
@Inject
private ReactiveMongoTemplate mongoTemplate;
public Mono<PushStatus> save(PushStatus pushStatus) {
return mongoTemplate.insert(pushStatus, COLLECTION_NAME)
.doOnSuccess(p -> System.out.println("saved"))
.doOnError(t -> System.out.println("error"));
}
public Flux<PushStatus> find(String myKey, String myRef) {
Query query = new Query();
query.addCriteria(Criteria.where("myKey").is(myKey));
query.addCriteria(Criteria.where("myRef").is(myRef));
query.limit(LIMIT);
return mongoTemplate.find(query, PushStatus.class, COLLECTION_NAME);
}
}
Thanks