Hello,
I started this topic from another topic, but really deserves it’s own space.
I was given a mySql EventData database and some of the mySql queries that are typicallly run on this database to create “reports” for clients. (the EventData is part of a headless e-commerce platform).
The data is getting so large that the reports are taking longer to run; so we are considering mongoDB. I’ve been recreating some of the mySql queries. What is a simple sql line, takes mulitple lines to do in mongo - although I am happy with the speed of mongo, when it’s done right.
Here is whate the data looks like. I’m using Robo 3T to build my queries.
It’s very simple but there are 9 million and presumably will go up to over 100 Million, soon:
{
"_id" : ObjectId("613858b58bd4d7717a0a5c2c"),
"StatID" : 92836,
"SessionID" : "5o85spqrhbrtkrd87gjb5rsts4",
"Subject" : "Home Page",
"SubjectID" : 0,
"Action" : "View Page",
"Ref" : null,
"EventData" : "",
"DeviceID" : 1,
"CreatedDateTime" : ISODate("2020-05-17T13:04:53.000Z")
}
{
"_id" : ObjectId("613658b58bd5d7710a0a6e4d"),
"StatID" : 93413,
"SessionID" : "7sf6udr21m1qppa78geci84406",
"Subject" : "Product Details",
"SubjectID" : 84,
"Action" : "View Product",
"Ref" : null,
"EventData" : "Pizza Capricorn",
"DeviceID" : 1,
"CreatedDateTime" : ISODate("2020-05-17T17:57:53.000Z")
}
…etc * millions
The sql query that I am creating in mongo is:
SELECT Count(DISTINCT SessionID), count(*)
FROM reports_stats
WHERE Action = 'Search';
I had some help from Pravel here in the mongo community who first solved it with facet (brilliant)
here’s what it looks like in mongodb:
db.report_stats_2.aggregate([
{
$match: {
Action: "Search"
},
},
{
$facet: {
dist_count: [
{
$group: {
_id: "$SessionID",
count: { $sum: 1 },
},
},
],
count: [{ $count: "count" }],
},
},
{
$addFields: {
dist_count: { $size: "$dist_count" },
},
},
{
$project: {
_id: 0,
dist_count: 1,
count: { $first: "$count.count" },
},
},
]);
The result is…
{
“dist_count” : 96342,
“count” : 1629478
}
The time to run this query is 5.65 seconds (too long).
I have to say, in mySql this query takes 6-7 seconds.
To make this faster, another tool (big data tool) called Sphinx does it in 0.7 seconds.
What must I do to return this query in a competitive time?
I’ve set up indexing, which is getting me 5.65 seconds.
What else can I do? Should I be digging in to clusters, sharding, etc.?
Here’s an image of the index setup in Compass:
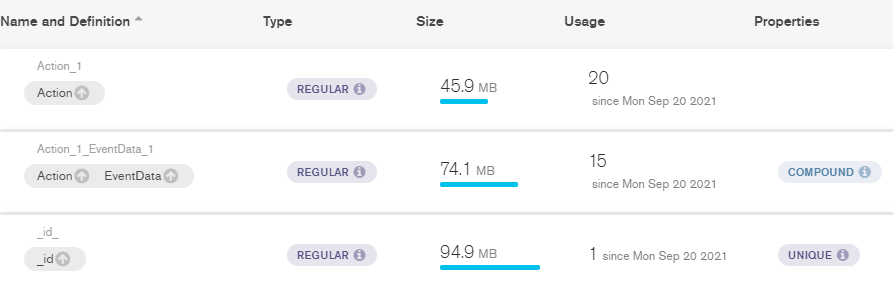
Thank you for your time and consideration!
Best,
Daniel