In our project records look something like this:
{
name: "foo",
businessDate: 20221113,
version: 3
...
}
My problem is I need to find the highest versioned record for each name and date. If I have an index on name:1, businessDate: -1, version -1, then I can take the first record for each index. Something like so:
{
$sort: {
name: 1,
businessDate: -1,
version: -1
}
}
{
$group: {
_id: {
name: '$name',
date: '$businessDate'
},
first: {
$first: '$$ROOT'
}
}
}, {
$replaceRoot: {
newRoot: '$first'
}
}
This works fine, and appears to be leveraging the index. However it goes a LOT slower than a simple query to find the oldest version: {$match: { version: 0}} - which ideally should be equally fast! Worse if the query is big enough I get out-of-memory errors with my group stage.
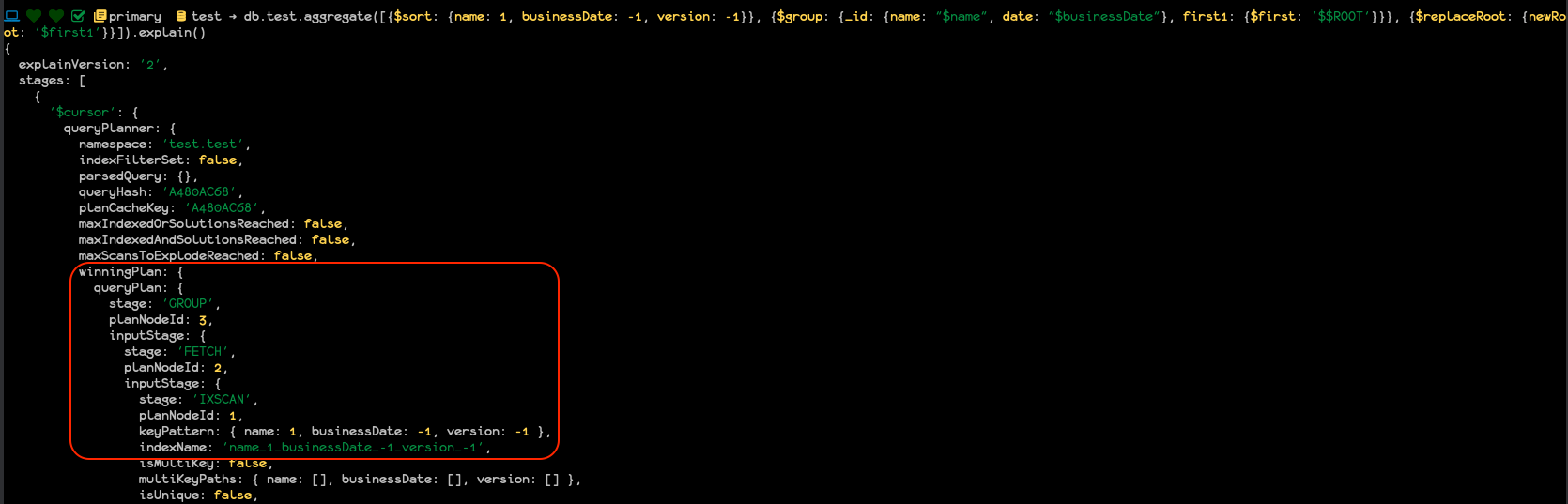
According to the documentation $group can use an index in this situation to speed things up. However when I did an explain I couldn’t see any evidence for this.
Is it possible to check this optimisation is taking effect?
How can I get the query that returns the latest version to be just as fast as the query that returns the oldest version?
Hi @Matthew_Shaylor , and welcome back to the community forums. 
I just tested your query against a very small number of documents and I see that the aggregation is using an index:
Can you state how many documents are in your collection? It appears that there are other fields that are not being shown. Are there a large number of these fields? Is the document size large? All of this can play into things being slow.
Not knowing anything about your data it’s hard to build a representative test to say for sure how to speed things up, but the query should indeed be using an index.
@Doug_Duncan yeah I can see it uses an index. But it will use that index even if I pick a non-trivial GroupBy such as $count() - so that use of the index alone is not enough to show any optimisation has occured.
There are other fields in the documents, average document size is 25kb. There are a few million documents in the collection - though for a given name and date usually there’s only a single document, sometimes up to 3 or 4 but rarely more than that.
Here’s another way of looking at the issue: Let’s say I have the following pipline:
{
$match: {
businessDate: 20221114,
version: 1
}
},
{
$sort: {
name: 1,
businessDate: -1,
version: -1
}
}
{
$group: {
_id: {
name: '$name',
date: '$businessDate'
},
first: {
$first: '$$ROOT'
}
}
}, {
$replaceRoot: {
newRoot: '$first'
}
}
If I query this way, it should be VERY fast because each groupby will contain a single document (because all index fields are either in the $match filter or the $groupby index, and the collection index is unique). However it seems MongoDb isn’t able to leverage this, so the query is slow. I think that even though the indexes guarantee there’s only a single document in the groupby, the pipeline has to wait until all documents have been processed before returning anything!