1 primary + 2 secondary + 1 arbiter; the secondary node sometimes needs to go to the primary to read the oplog long ago. When it reads the data, the main node host cpu is 100%, and the database cannot provide services at all. I want to know under what circumstances will trigger this situation and how can I avoid it from happening.
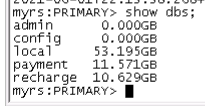
At present, the size of my oplog is 52g (storagesize). Is it too large?
Hi @liu_honbo and welcome in the MongoDB Community !
The first question is why do you have a secondary nodes that is lagging so far behind that it needs to catch up a big part of the oplog?
That isn’t healthy because it means that this secondary node isn’t available for an election in case something happens to your primary and you need to elect a new primary which means that your replica set isn’t really Highly Available.
A 52GB Oplog isn’t very shocking. It all depends on how much write operations you are supporting. Ideally your oplog window should cover at least a few days so you can sleep on your 2 ears during a weekend for example .
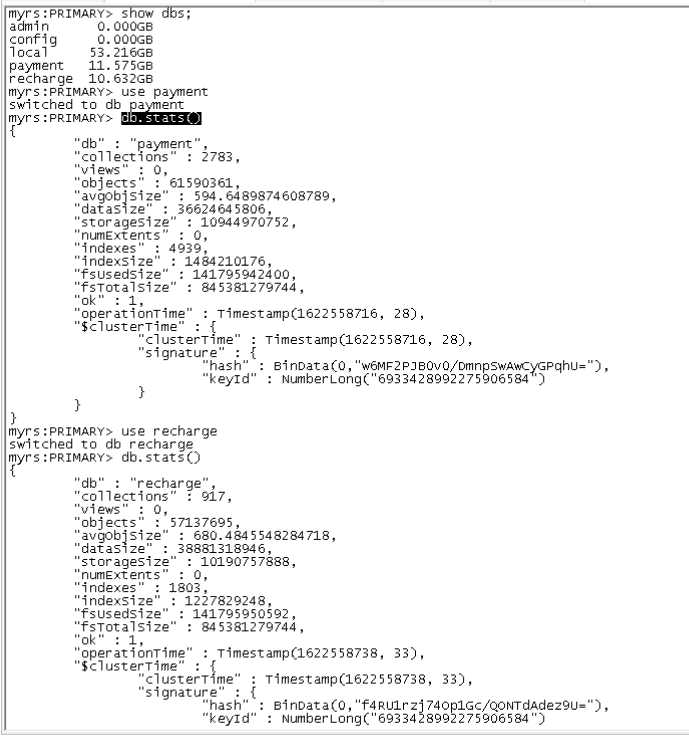
If you have the hardware to support a 52GB oplog, you probably have a big cluster. Can you share some numbers maybe like RAM, nb CPUs, type of drives, rs.printReplicationInfo(), database sizes and total size of your indexes, average nb of read/writes operations per secs and how much data is inserted each day?
I guess this could help to start to understand what is happening. But the first problem is why your secondary node isn’t already in sync to begin with.
Was your secondary node down for a few months? Is this the reason why it’s lagging behind the primary. If it needs to catch up 2 months of write operations, it’s kinda normal that it is struggling a bit…
Can I block the automatic reading of a large number of oplog logs when the secondary node fails?
Or can I specify to synchronize the failed node with another secondary node?
Looks like you have 252GB RAM for 11.5+10.5 = 22GB of data which is completely overkill so it should work without any problem in theory.
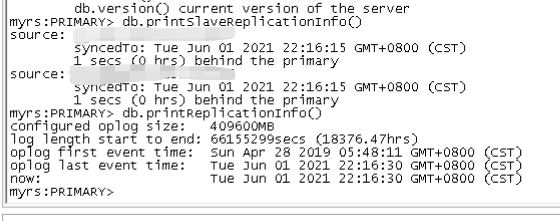
Your oplog is “oversized”. You have 18376h of history in it which is more than 2 years! That’s VERY confortable. Usually a few days is more than enough to allow you to resync a server that had an issue for a few hours.
There is a procedure to resize the oplog but to be honest, I wouldn’t bother. It’s just more confortable and you clearly have room so it shouldn’t be an issue.
You mentioned that you have 3 servers (PSS). Are the 3 servers identical?
If one of your server is completely out of sync, I would reset completely this server and restart it from a backup at this point. It’s probably easier because the sync would just have to sync the difference between the primary and the backup so hopefully that shouldn’t take more than a few minutes / seconds (if your backup is recent, and it should be).
It’s weird that your oplog is that big. By default, it’s supposed to be 5% of free disk space… So I guess you have a very large disk or a specific value in your config file.
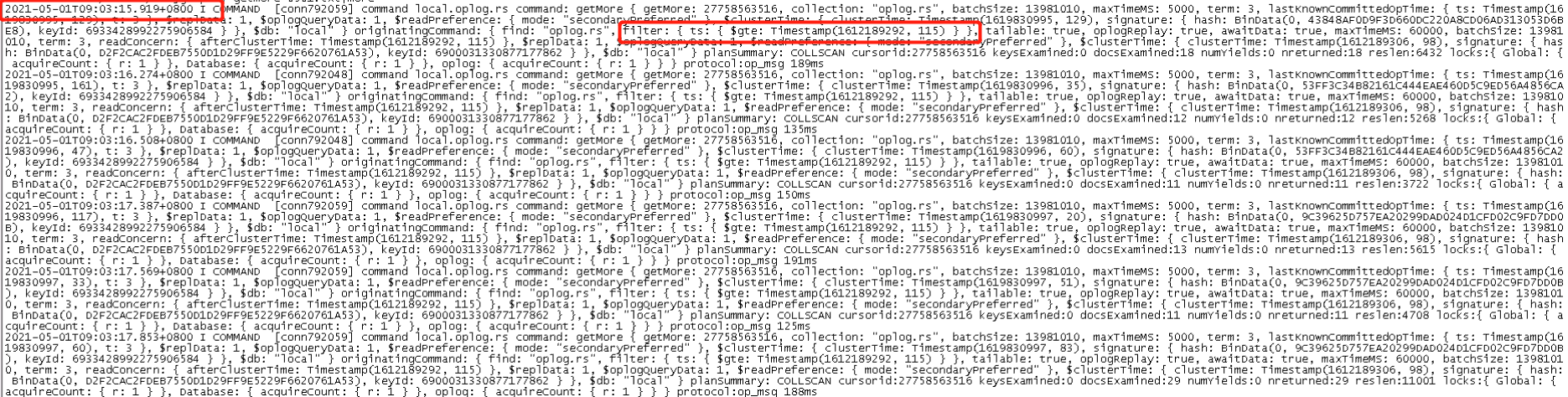
From this log, I guess your cluster was failing since February 1st at least and it’s trying to catch up all the write operations that happened since then.
So the question is: what is the fastest way to recover our secondary? Let it replay 4 months worth of write operation or reset everything and restart from a backup that will just need to replay a few hours worth of write operations (present - backup time)?
From what I see, it’s completely normal to have these operations logged in the logs. That’s because operations slower than 100ms are logged by default but it’s expected for this kind of operation with an oplog this large. It’s not an issue as this will stop once our 3 nodes are in sync.
Also, it’s apparently syncing from your other secondary (see readPreference) so your primary shouldn’t be impacted at all and your client workload should be fine I guess.
The rectification of the cluster resource configuration is completely consistent
All businesses run on the primary node
The priority of the primary node is 100, and the priority of the secondary node is 50 and 30 respectively.
No abnormality occurred in the cpu of all secondary nodes
 !
! .
. ![dbsize|205x106]
![dbsize|205x106]