Hey Folks.
I’m seeing a weird thing in Atlas with Online archive. This is a time series collection in question and originally we set 365 days for the age limit and then set deletion to 180 days. Now I’m seeing it keep 365+180 days of data per the time field in the collection instead of just 365 days.
I know the deletion age says it’s in preview, but doesn’t seem to be working as I think it should. Now I’ve blanked out the deletion age and so far no change.
Anyone know how to reset an archive somehow so that I only keep 365 days in the collection?
Thanks,
Steven
Hello @Steven_Tate ,
I think what you are describing is actually working as expected. The way that Online Archive + Expiration works is that data expires from the cluster after the period of time that you have set in your rule based on the date field in the time series collection, data then stays in the archive for the period of time specified in the expiration rule based on when it was written to the archive (not based on the date field in the document).
So if you had a bunch of data that should immediately archive once you set the rule, then that data should be archived as soon as possible, but it would then stay in the archive for 180 days from the day it was archived.
Does that make sense?
I understand that that’s how is supposed to work. Makes sense to be in the cluster for the “archival age limit” per the time series date field AND THEN move to the archive when it hits that number of aged days.
And then yes, it should remain in the archive for the deletion age limit and then get deleted after that point. This is NOT the way it is working.
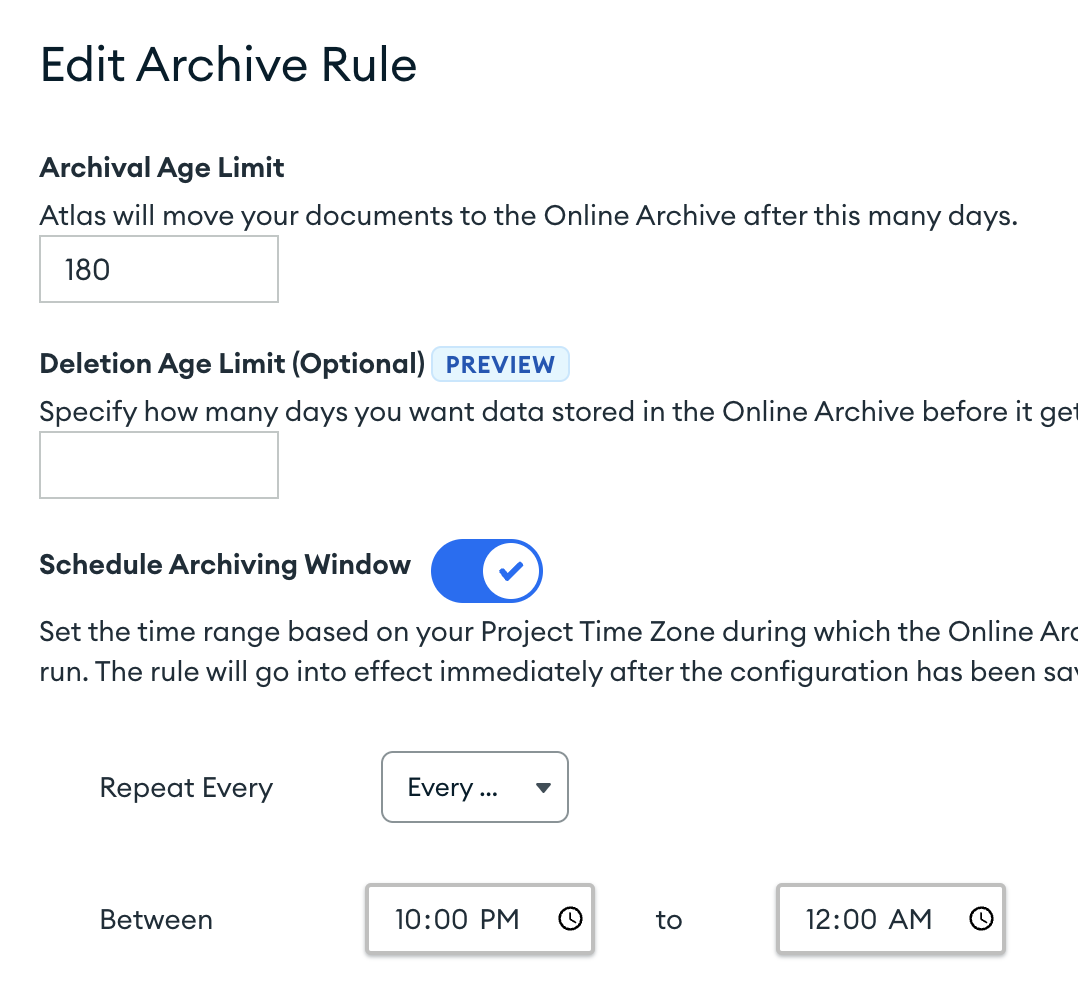
For now, I’m desperate to get this stuff archived so I have removed the limit to see if it would matter and lowered the archive to 180 days. Here’s a screenshot of my current serttings:
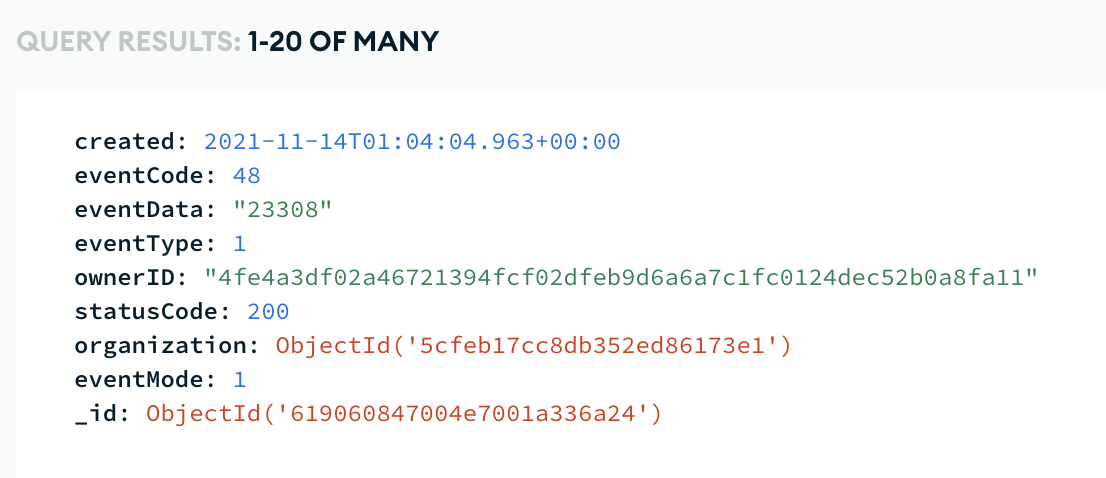
And here is the collection as of right now showing records from almost 2 years ago (well more than 180 days):
I’ve read all the blogs and all the docs. And it seems that it is simply not doing what it is supposed to be doing.
Also, I have a 2 hour archiving window set and when it hits, it basically uses all resource of my M10 for the duration and then still does not seem to move anything to the archive.
Any ideas? I’m at the point of creating a support ticket as I have to get this aged data out of my collection.
Thanks Benjamin. Keep up the awesome work!
Steven
Ahh thanks for clarifying @Steven_Tate and pardon the misunderstanding.
Based on these details it would there is something inefficient happening during the archival job which is causing it to fail if there are no documents being moved at all.
It’s possible that the archival query is just extremely inefficient which is why you are running out of resources. You have an index index on the date field you’re using for archival right?
Also, have you connected to the archive only and validated that no docs have been moved into it at all? It is possible it’s just running slowly and hasn’t gotten all of the old documents off yet.
Hey Benjamin,
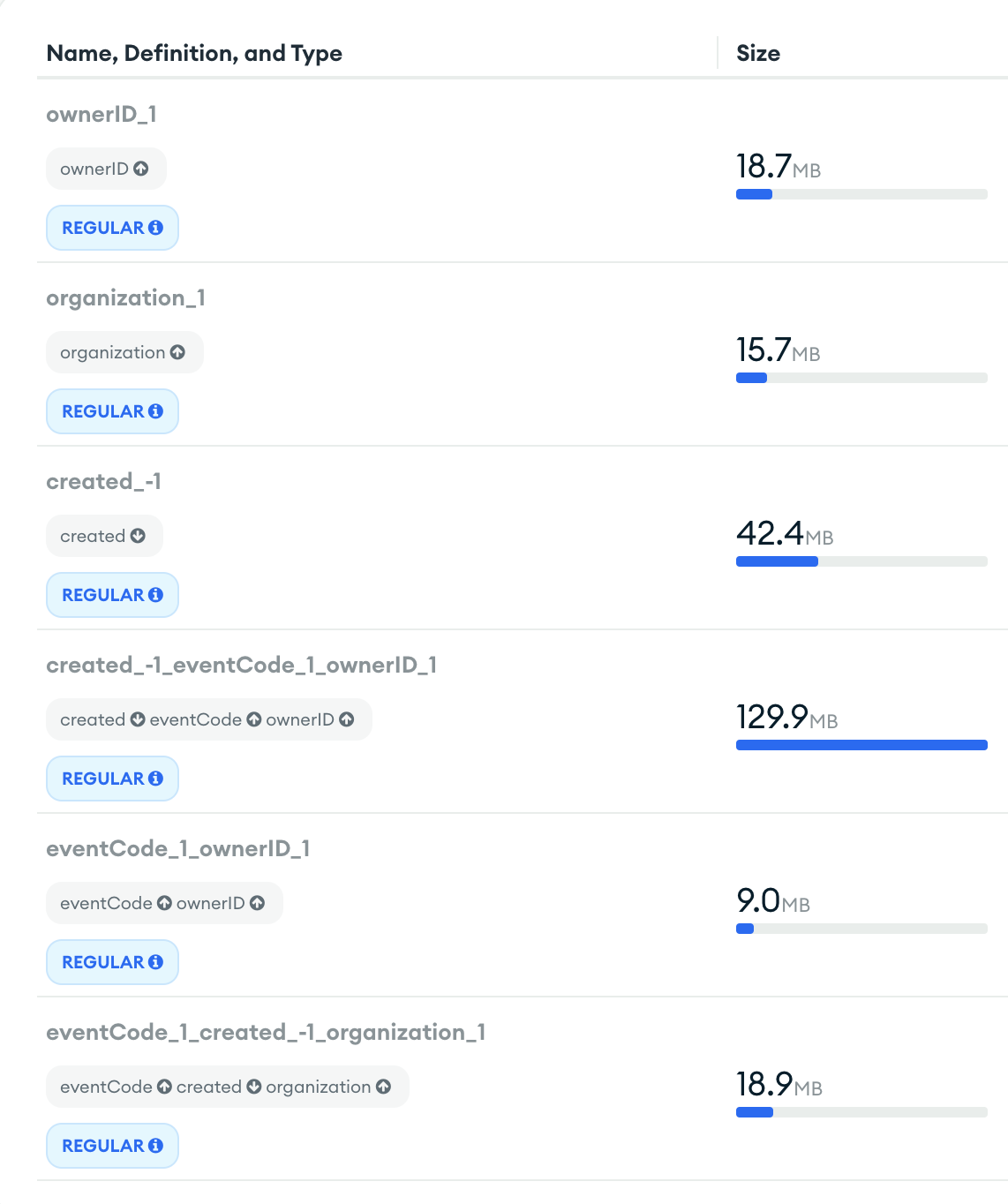
Thanks again. Yes there is an index on the created field which sits as the time field:
Also, there are 36 million records in the collection. So while that is alot, it shouldn’t be breaking the bank as a simple match and count of 180 days does use the index (and takes nearly a minute). Could certainly be an issue with my indexes:
I guess technically, it’d be doing the opposite which is querying anything more than 180 days old. That could certainly just be repeatedly timing our perhaps?
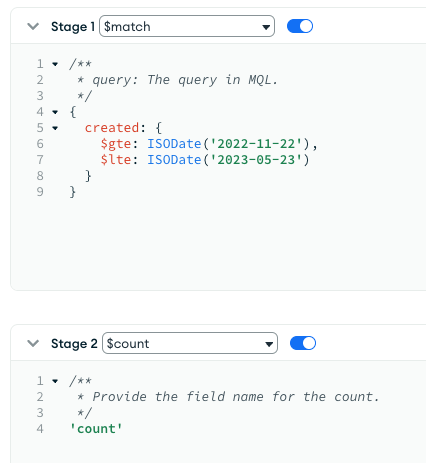
I have connected directly to the archive and seen that records are in there. But no records have been copied since I changed from 365 days and 180 to delete to 180 days and never delete.
How do you archive big data sets then if it doesn’t determine that the archival is efficient?
Thanks again,
Steven
There should not be any issue archiving large datasets as long as the indices allow for efficient archival jobs.
I think it would be good to open a support ticket, the team should be able to help guide you on whether or not we are able to take advantage of indices for the queries and they will be able to escalate this to a bug if that’s not happening.