We have a sharded cluster with 2 shards Shard A and Shard B, each in primary + 2 replicas configuration.
Shard A and B are in two different zones so that Shard A should contain recent data up to a cutoff and ShardB historical data.
Shard A is a machine with SD drive, shardB has a normal disk (since it is supposed to have lower usage patterns)
Initially there was only Shard A which grew to almost 7GB and around 600k chunks, with standard max chunk size.
We then attached ShardB, hoping to be able to move all the historical data in a relatively quick amount of time.
Since ShardB has been attached, the balancer has started moving chunks from A to B. The speed was already initially pretty bad but we have noticed that it got much worse with time, as you can see here:
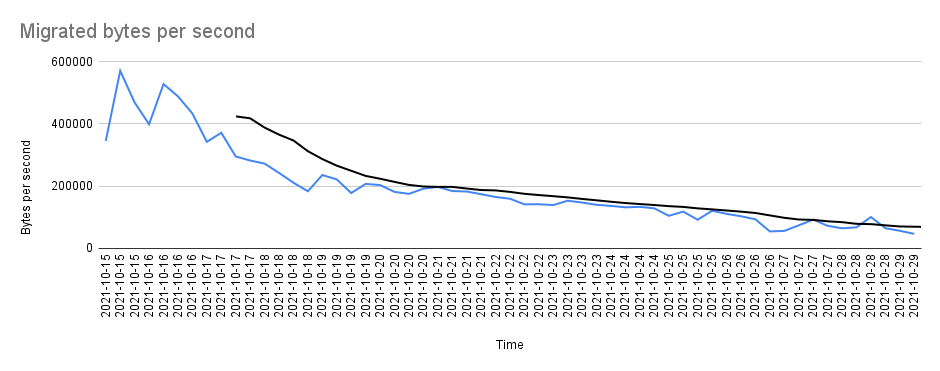
At this speed it will take probably years to move the amount of data that we need to move.
Note that we’ve also tried to:
- Completely stop the traffic to the cluster. This improved things a bit but didn’t make a huge difference.
- Merge chunks to increase their size. This is not helping. The last few very bad datapoints you can see in the charts are due to a series of chunks that are currently being moved that have an average size of 200Mb. When those chunks will be done we hope things will get slightly better.
A transfer rate of 200k/s seems really really low, so we basically want to know what kind of options we have.
Have we hit some kind of intrinsic bottleneck? How can we debug this issue?
Any help would be appreciated.