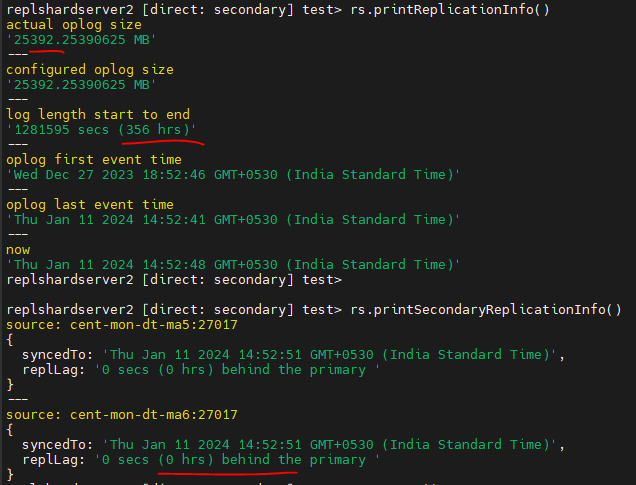
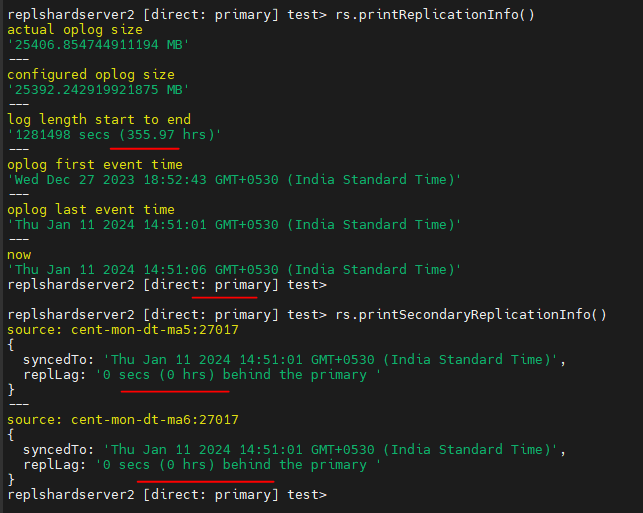
Another screenshot for error logs for mongosync -
{“time”:“2024-01-11T14:50:22.032011+05:30”,“level”:“fatal”,“serverID”:“3b199ea3”,“mongosyncID”:“coordinator”,“stack”:[{“func”:“(*ChangeStreamReader).run.func1”,“line”:“291”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/cea/change_stream_reader.go”},{“func”:“Retryer.RunForTransientErrorsOnly.func1”,“line”:“67”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/retry/retry.go”},{“func”:“(*looper).loop.func1”,“line”:“238”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/retry/retry.go”},{“func”:“RunAndDetect”,“line”:“37”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/util/slowness/slowness.go”},{“func”:“(*looper).loop”,“line”:“233”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/retry/retry.go”},{“func”:“Retryer.runRetryLoop”,“line”:“130”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/retry/retry.go”},{“func”:“Retryer.RunForTransientErrorsOnly”,“line”:“69”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/retry/retry.go”},{“func”:“(*ChangeStreamReader).run”,“line”:“234”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/cea/change_stream_reader.go”},{“func”:“(*ChangeStreamReader).Run”,“line”:“151”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/cea/change_stream_reader.go”},{“func”:“(*Mongosync).startCEAComponents.func1”,“line”:“165”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/change_event_application.go”},{“func”:“(*MongoErrGroup).NewRoutine.func2”,“line”:“49”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/internal/mongosync/util/routines.go”},{“func”:“(*Group).Go.func1”,“line”:“75”,“source”:“/data/mci/104f37d051a93bddf6d52dbbf2ffab39/src/github.com/10gen/mongosync/vendor/golang.org/x/sync/errgroup/errgroup.go”},{“func”:“goexit”,“line”:“1598”,“source”:“/opt/golang/go1.20/src/runtime/asm_amd64.s”}],“error”:“failed to iterate change stream: Change Stream Reader (CRUD) could not retrieve the next change event (last resume token is {"_data": "826585257600005E0A2B042C0100296E5A10048E9BFDBD5705491BB0D8EAAD1ED87755463C6F7065726174696F6E54797065003C696E736572740046646F63756D656E744B657900463C5F6964003C303038363734656566356461633363363662666335613032313336326336636600000004"}): (ChangeStreamHistoryLost) Error on remote shard cent-mon-dt-ma6:27017 :: caused by :: Executor error during getMore :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.”,“message”:“Error during replication”}
==========================================================