Hi @Nils_Langner,
Thanks for your patience. I believe the scoring you’re seeing (in specific reference to the 2 documents in your screenshot) is due to the other fields containing the "file" term. I did a quick find on the document with the highest score and found there are 31 instances of the word "file" which would impact the score since you have indexed all fields.
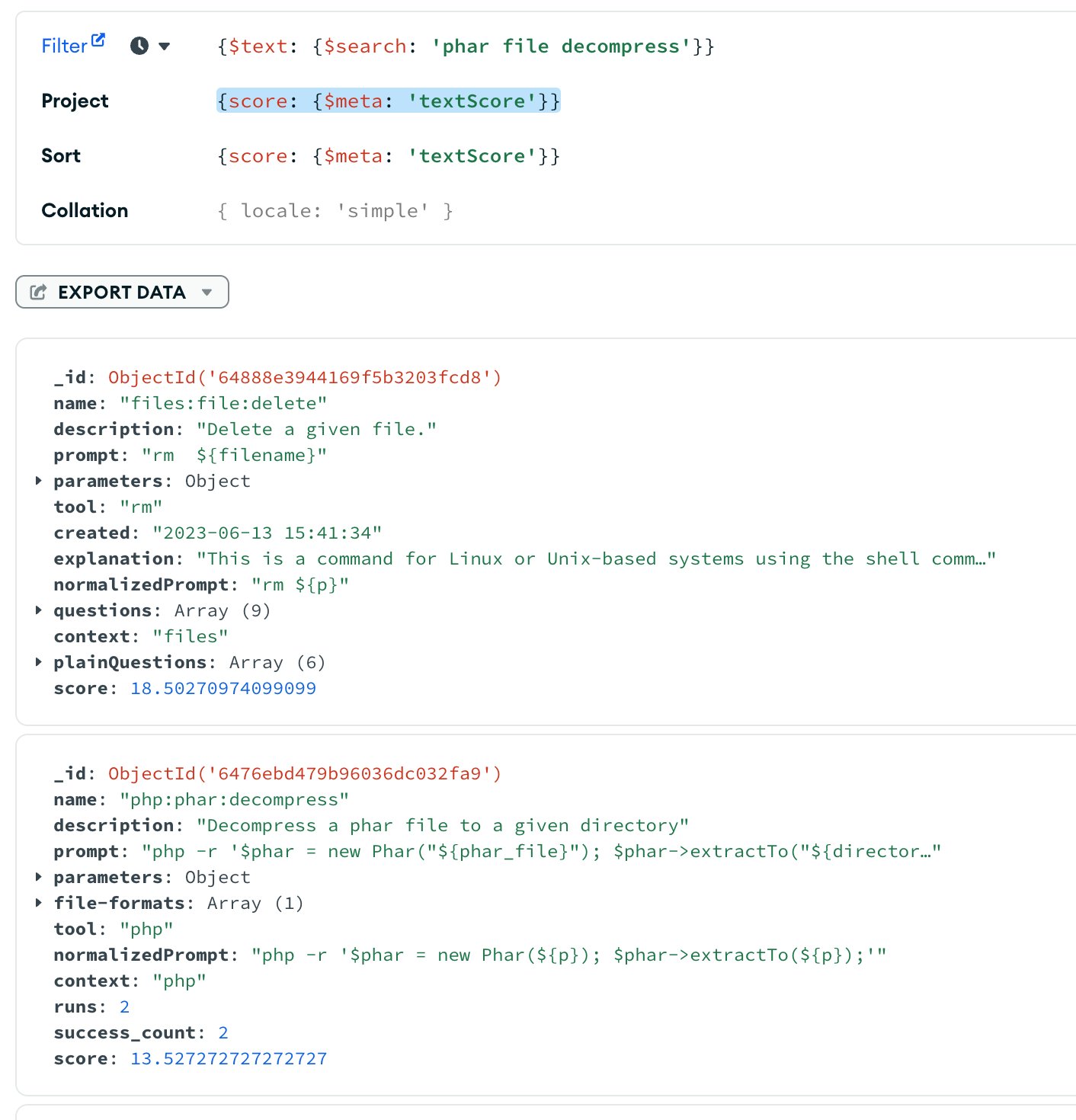
For example, in my test environment, I have the same 2 documents where the higher scoring document does not contain contain "phar file decompress" in the description:
db.text.find({$text:{$search:'phar file decompress'}},{score:{'$meta':'textScore'}})
[
{
_id: ObjectId("64888e3944169f5b3203fcd8"),
name: 'files:file:delete',
description: 'Delete a given file.',
prompt: 'rm ${filename}',
parameters: { filename: { type: 'forrest_filename' } },
tool: 'rm',
created: '2023-06-13 15:41:34',
explanation: 'This is a command for Linux or Unix-based systems using the shell command line interface. "rm" stands for "remove" and this command is used to delete a file or multiple files. \n' +
'\n' +
'"${filename}" is a variable that contains the name of the file you want to remove. The syntax of ${variable_name} is used to refer to the value stored in a variable. So in this case, the command is telling the system to remove the file whose name is stored in the variable filename. \n' +
'\n' +
'For example, if the variable filename is set to "myFile.txt", the command would remove that file from the system. \n' +
'\n' +
"It's important to note that this command is permanent, meaning that the file will be permanently deleted from the system and cannot be recovered. So, make sure you are absolutely sure that you want to delete the file before using this command.",
normalizedPrompt: 'rm ${p}',
questions: [
'remov file?',
'delet log file',
'delet txt file',
'delet file',
'delet excel file',
'remov excel file',
'delet empti file',
'wie kann ich ein datei löschen',
'remov file'
],
context: 'files',
plainQuestions: [
'How to delete an excel file?',
'How to remove an excel file?',
'How to delete a file?',
'How to delete an empty file?',
'wie kann ich eine Datei löschen',
'How to remove a file?'
],
score: 16.252709740990987
},
{
_id: ObjectId("6476ebd479b96036dc032fa9"),
name: 'php:phar:decompress',
description: 'Decompress a phar file to a given directory',
prompt: 'php -r \'$phar = new Phar("${phar_file}"); $phar->extractTo("${directory_to_decompress_to}");\'',
parameters: {
phar_file: {
name: 'phar file',
description: 'Phar file that should be extracted',
type: 'forrest_filename',
'file-formats': [ 'phar' ]
},
directory_to_decompress_to: []
},
'file-formats': [ 'phar' ],
tool: 'php',
normalizedPrompt: "php -r '$phar = new Phar(${p}); $phar->extractTo(${p});'",
context: 'php',
runs: 2,
success_count: 2,
score: 14.86060606060606
}
]
There are multiple instances of the term "file" inside the plainQuestions and questions field for the first document. After removing this and performing the same .find() with the $text operator, we can now see the score is lower than the file that contains the terms "phar file decompress" in the description field:
[
{
_id: ObjectId("6476ebd479b96036dc032fa9"),
name: 'php:phar:decompress',
description: 'Decompress a phar file to a given directory',
prompt: 'php -r \'$phar = new Phar("${phar_file}"); $phar->extractTo("${directory_to_decompress_to}");\'',
parameters: {
phar_file: {
name: 'phar file',
description: 'Phar file that should be extracted',
type: 'forrest_filename',
'file-formats': [ 'phar' ]
},
directory_to_decompress_to: []
},
'file-formats': [ 'phar' ],
tool: 'php',
normalizedPrompt: "php -r '$phar = new Phar(${p}); $phar->extractTo(${p});'",
context: 'php',
runs: 2,
success_count: 2,
score: 14.86060606060606
},
{
_id: ObjectId("64888e3944169f5b3203fcd8"),
name: 'files:file:delete',
description: 'Delete a given file.',
prompt: 'rm ${filename}',
parameters: { filename: { type: 'forrest_filename' } },
tool: 'rm',
created: '2023-06-13 15:41:34',
explanation: 'This is a command for Linux or Unix-based systems using the shell command line interface. "rm" stands for "remove" and this command is used to delete a file or multiple files. \n' +
'\n' +
'"${filename}" is a variable that contains the name of the file you want to remove. The syntax of ${variable_name} is used to refer to the value stored in a variable. So in this case, the command is telling the system to remove the file whose name is stored in the variable filename. \n' +
'\n' +
'For example, if the variable filename is set to "myFile.txt", the command would remove that file from the system. \n' +
'\n' +
"It's important to note that this command is permanent, meaning that the file will be permanently deleted from the system and cannot be recovered. So, make sure you are absolutely sure that you want to delete the file before using this command.",
normalizedPrompt: 'rm ${p}',
context: 'files',
score: 7.169376407657658 /// <--- lowered score after changing the document
}
]
Note: The above test collection contained the following indexes:
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{
v: 2,
key: { _fts: 'text', _ftsx: 1 },
name: 'textIndex',
weights: { '$**': 1, description: 2, name: 3 },
default_language: 'english',
language_override: 'language',
textIndexVersion: 3
}
]
Although I understand removing those fields is not what you’re after, I hope it helps in understanding the scoring behaviour you had seen. In comparison to this, with the unaltered versions of the same 2 documents, I created a similar index with following weights:
test> db.text.createIndex({'$**':'text'},{weights:{description:6,name:8}})
$**_text
Which then resulted in the document containing all the terms of the text search in description to score higher:
test> db.text.find({$text:{$search:'phar file decompress'}},{score:{'$meta':'textScore'}})
[
{
_id: ObjectId("6476ebd479b96036dc032fa9"),
name: 'php:phar:decompress',
description: 'Decompress a phar file to a given directory',
prompt: 'php -r \'$phar = new Phar("${phar_file}"); $phar->extractTo("${directory_to_decompress_to}");\'',
parameters: {
phar_file: {
name: 'phar file',
description: 'Phar file that should be extracted',
type: 'forrest_filename',
'file-formats': [ 'phar' ]
},
directory_to_decompress_to: []
},
'file-formats': [ 'phar' ],
tool: 'php',
normalizedPrompt: "php -r '$phar = new Phar(${p}); $phar->extractTo(${p});'",
context: 'php',
runs: 2,
success_count: 2,
score: 28.727272727272727
},
{
_id: ObjectId("64888e3944169f5b3203fcd8"),
name: 'files:file:delete',
description: 'Delete a given file.',
prompt: 'rm ${filename}',
parameters: { filename: { type: 'forrest_filename' } },
tool: 'rm',
created: '2023-06-13 15:41:34',
explanation: 'This is a command for Linux or Unix-based systems using the shell command line interface. "rm" stands for "remove" and this command is used to delete a file or multiple files. \n' +
'\n' +
'"${filename}" is a variable that contains the name of the file you want to remove. The syntax of ${variable_name} is used to refer to the value stored in a variable. So in this case, the command is telling the system to remove the file whose name is stored in the variable filename. \n' +
'\n' +
'For example, if the variable filename is set to "myFile.txt", the command would remove that file from the system. \n' +
'\n' +
"It's important to note that this command is permanent, meaning that the file will be permanently deleted from the system and cannot be recovered. So, make sure you are absolutely sure that you want to delete the file before using this command.",
normalizedPrompt: 'rm ${p}',
questions: [
'remov file?',
'delet log file',
'delet txt file',
'delet file',
'delet excel file',
'remov excel file',
'delet empti file',
'wie kann ich ein datei löschen',
'remov file'
],
context: 'files',
plainQuestions: [
'How to delete an excel file?',
'How to remove an excel file?',
'How to delete a file?',
'How to delete an empty file?',
'wie kann ich eine Datei löschen',
'How to remove a file?'
],
score: 25.169376407657666
}
]
In saying all the above, hopefully the Assign Weights to Text Search Results documentation may be of use to you.
Regards,
Jason