I resynchronized the data of a node through the internal mechanism of the MongoDB replica set. After the synchronization was completed, I found that the total number of data in some collections was not equal. I checked the node status through rs.status(). The status is already SECONDARY, and the optime is also consistent with the PRIMARY node.
I have newly synchronized a SECONDARY node, and the total number of data in the collection of this node is consistent with that of the PRIMARY node.
But after a long time, the node data synchronized for the first time, the total number of data in some collections is still inconsistent with the PRIMARY node.
I haven’t found any similar phenomena in the official documents.
I would like to know what are the possible reasons for this problem?
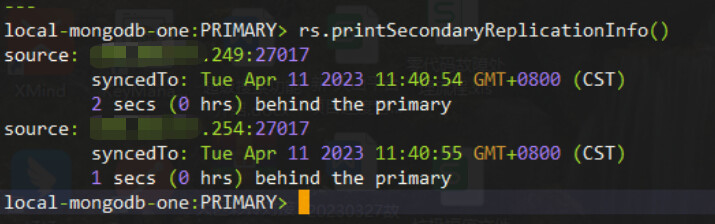
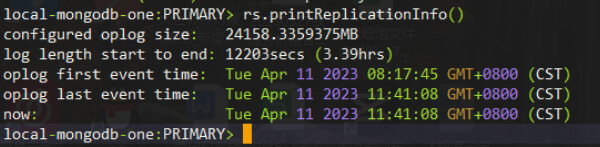
I notice your oplog is ~24GB but you only have 3.39 hours of headroom.
Are you doing a lot of inserts to this cluster? It seems busy.
Could a few seconds equal a discrepancy of 1000 documents?
If the write concern is {w: "majority"} it could be the other members that are more up to date, if the write concern is {w:1} then both secondaries could be behind if there is a corresponding high insert rate.
If you think this is unlikely then it might be prudent to create a bug report on https://jira.mongodb.org
I was thinking the same thing the oplog headroom is very small, I wonder if the oplog was too small and that’s why it didn’t get all the documents when he was doing the sync? But
Yes, our MongoDB replica cluster writes a lot of data.
The write level of the program is: {w: “majority”}
Initially, this MongoDB replica cluster had three nodes, but two of them went down, and I removed the two down nodes from the cluster.
Then I newly deployed a node of the same version, added it to the original replica set, and synchronized data through the internal synchronization mechanism of the MongoDB replica set. When the node role is normal and the optime is consistent through rs.status(), I observe the newly synchronized node There are missing data in the collection.
I later deployed another node to join the cluster. After the latest node synchronization is completed, this node has the same data as the master node. So far, among the three nodes, the node data for the first synchronization is still missing collection records.
During the synchronization of the first node, business reading and writing are suspended.
Only the new node is synchronizing the data of the primary node through the internal mechanism of the replica set.