I’m currently researching read and write operations on various NoSQL datastores in my master theses. I would like to know specifically which kind of caches are involved during a read and write of documents with mongodb. I’ve found an older presentation from percona (slide no. 9 - https://www.percona.com/sites/default/files/presentations/Monitoring-MongoDBs-Engines-in-the-Wild.pdf ) which is describing what I’m searching for. But of course I would like to have a more reliable source for my research. My main question is if there is any technical paper, documentation or something similar that could help me?
That’s funny - I’m comparing mongodb to cassandra and I really love the datastax guide (nice graphics, which makes it even better understandable): How Cassandra reads and writes data
It would be great if some mongodb/wiredtiger dev could help me out!
WiredTiger uses memory as a cache for all the data on the disk and the data in memory forms the current working set, overall it is similar to any key-value system will look like. It uses a least-recently-used algorithm to continuously moves data to disk that is currently not being accessed out of the memory to free up enough space to read data that are requested by the user but currently reside on the disk back into memory.
Consider two options while reading data from WiredTiger.
The data requested by MongoDB is in the WiredTiger cache.
WiredTiger receives the request from MongoDB, iterate over the btree to find the page (requested information), and return the relevant value from the update chain.
The data requested by MongoDB is not in WiredTiger cache
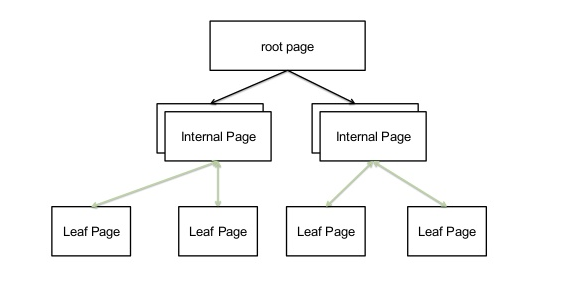
Suppose the requested information is not in the WiredTiger cache, then it has to search on-disk. If btree is not loaded then it gets the root page of the btree from on-disk, put in WiredTiger cache, traverses the btree’s internal pages to get the address (or disk address), load the page from on-disk to cache and gives the reference to MongoDB.
Cache management is a huge portion of WiredTiger. Can you be more specific on what you are looking for. ?
first of all - thank you very much! This made it much more clear how a read works. To be a bit more specific about my research issue I would like to refer to my newsgroup post: https://groups.google.com/g/wiredtiger-users/c/lyS1HoGVErU/m/5XZSYEW5BgAJ Maybe you can clarify the question I’ve brought up there
In addition to @Lewis_Chan question: My guess is that the data is organized (in cache / on-disk) as a b-tree? Is the “_id”-index seperate from the data in another b±tree?
Is somebody maybe explain to explain why I do see way less “pages read into cache” then “pages requested from cache”. How is WiredTiger able to request pages that are not in the cache yet? Or does the request just means an request which doesn’t need to return a page as result (like a non fulfilled request)?
Pages read into the cache is actually Pages read into the cache from disk, and Pages requested from the cache is actually Pages requested by the workload from the cache.
Suppose you/workload are trying to read a key/value pair, we will search the btree to find the particular page and that page is considered as page requested from the cache. If that page is already in the cache then no need to do anything, but if the page is not in cache then we go read it from disk and that becomes pages read into the cache.
Hence, pages read into the cache are lesser and those are the ones we are reading from the disk and putting into the cache. But pages requested from cache is basically all the read you/workload is doing.
Imagine a two-layer approach:
One Workload/you requesting a page from cache.
If the requested page is not in cache then it reads from the disk to satisfy the request (pages read from cache).
That is the reason more pages are requested from the cache (in your simulation example), most of the btree that are being used for IO fits into the cache, But once you have the btree in the cache then all the reads can be done without going to the disk.
The requests always return the page but if that page is already in the cache then it need not be read from the disk to cache.
you’re my hero - thank’s for that perfect explanation. This makes totally sense! Just one more question: Does the Pages read into the cache from disk and Pages requested by the workload from the cache both talking about internal pages (size of 32kb) or leaf pages (size of 4kb)?