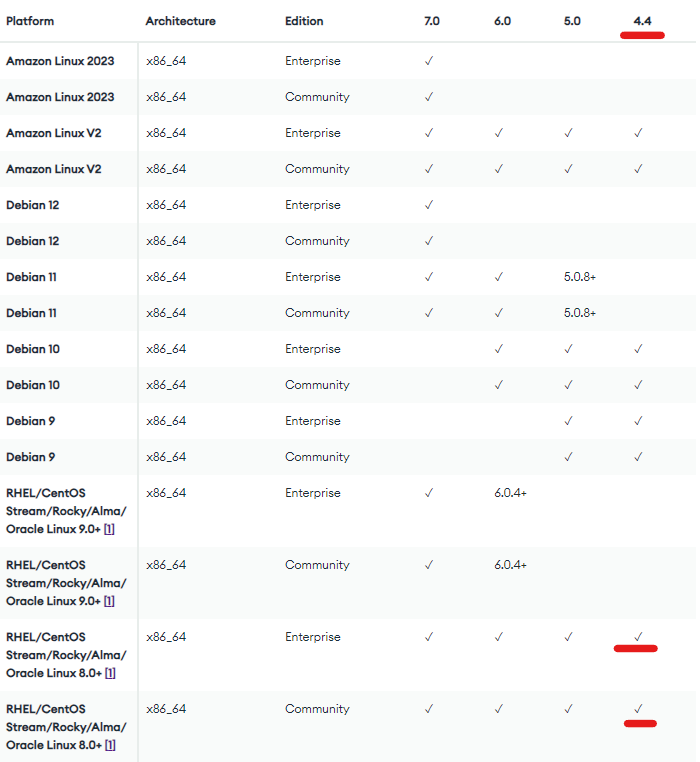
I plan to upgrade 6 RHEL servers that run MongoDB 4.4 from 7.9 to 8.8 in a few days - on my Replica set of 5 which is compatible and will go through all prior check and after check for a seamless upgrade.
After this upgrade I would need to upgrade MongoDB to 5.0 as 4.4 is becoming EOL, although, prior to this what I have found is that the application drivers that connect to the replica set are using legacy versions:
The icon in the Java driver compatibility guide indicated that the driver will connect to those versions of MongoDB but not support all the features of that version. You may be able to upgrade the server and catch up on the driver later, but it is always recommended to be running the latest version of the driver This is best tested in a test/staging environment.
Hi @chris
I see, so since the driver that currently connects to MongoDB 4.4 is in the category that it would connect but not support all features, there is an instance where data extracts are happening through aggregates sent from Spark.
Version: Scala/2.11.12:Spark/2.4.8.7.1.9.0-387
and what happens is,