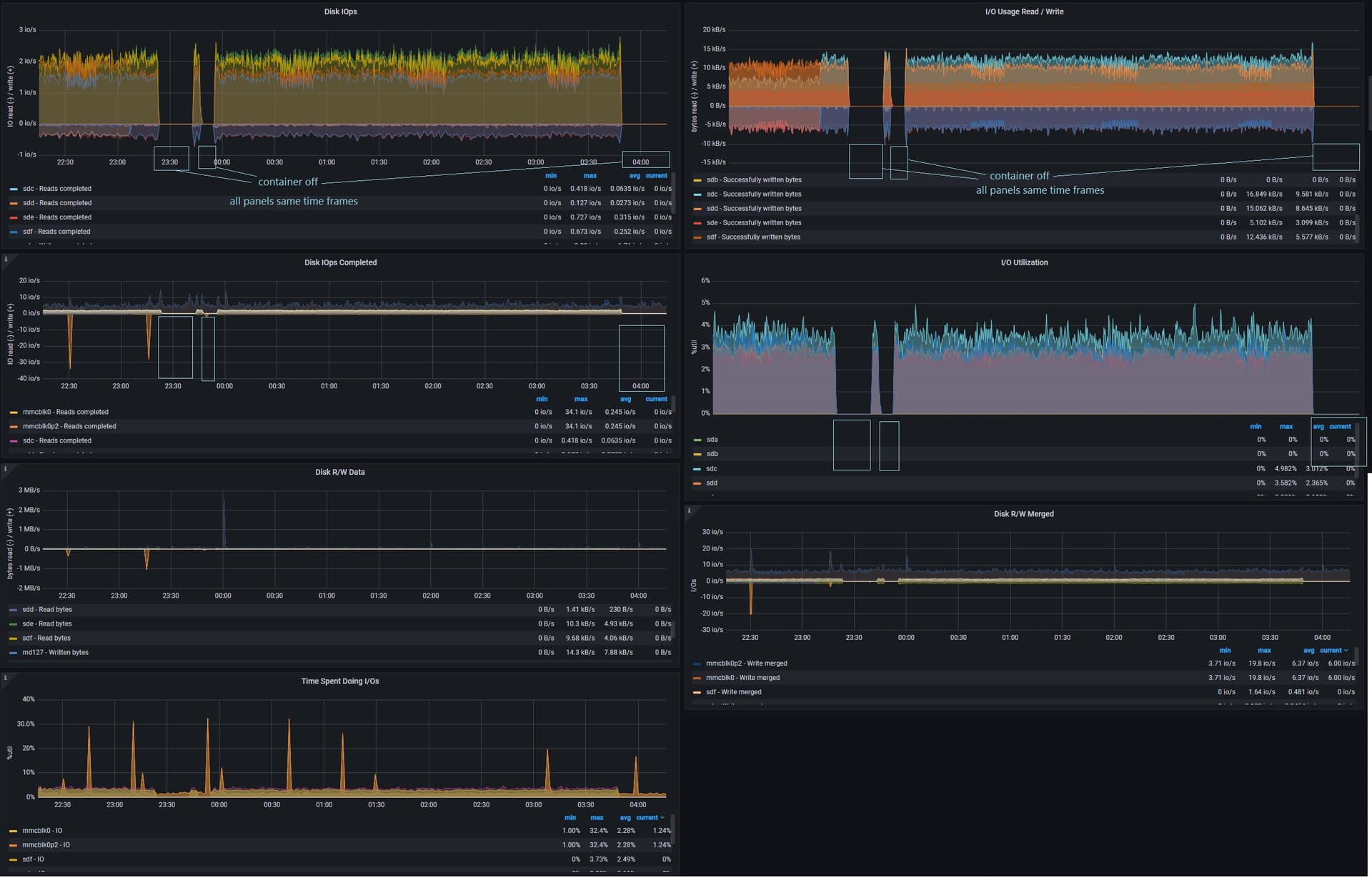
Hey I just expanded my RAID array for an upcoming project and after i did this I noticed the drive heads NEVER stopped moving, you could hear the heads moving back and forth 24/7. Originally I thought this isn’t normal and so I decided to investigate. It took me a while as I couldn’t find anything that was utilizing the hard drives using tools like iotop but I knew something was going on because during monitoring with Prometheus I could see around 2 IO operations /sec reading/writing about 10kB /sec on each of the drives in the RAID array. Finally I stopped the MongoDB container and everything settled down but picked right back up after starting the container.
This happens during idle, meaning the container this is in simply exists I am not currently writing to any database/collection or querying for any info, it’s just sitting there waiting for me to finish the part of my project that utilizes mongoDB.
So my question is this normal and expected? If so what exactly is gong on that requires mongoDB to access the drives constantly? Is there a way to mitigate this behavior?