If for example somebody click on the page from a user then my node.js webserver will make a query to the Mongo database to fetch all user infos, the database will look for the user infos and give back the result. I am thinking now about how cache works and if here something like cache will be use automatic or if you need to code something.
For example if somebody did try to open the same user page before and if anyway the databse or the webserver script does see that this database request was make before and the data from the use is still same, then it could use something like cache, that would usual make the website work faster because you dont make always a new database query, is it possible that here the database or the webserver will use something like a cache? Does somebody understand about what i am thinking and how this works with Mongo db and node.js webserver?
Hi @Florian_Silbereisen,
It’s impossible to guarantee that the data didn’t change between your first and second query. If you cache the data, you might just show stale data to your second user.
You could totally add a cache layer in your Node app if this is the expected behaviour you want. But it’s probably not what I would do.
That being said, MongoDB is already using RAM to “cache” the most recently used document in RAM. So next time you ask for these documents, mongod doesn’t have to fetch them from disk, as they are already available in RAM. This concept is called the “working set”.
For this to work efficiently, you have to make sure that you have enough RAM for your indexes + working set + query execution (evil sort in-memory, etc), and you have to make sure that you don’t evict these documents from RAM too quickly. Else this might be a sign that you need more RAM.
Cheers,
Maxime.
3 Likes
Does this RAM concept from Mongo automaticly take place from hisself or do i need to code it or do i jsut need to buy a vps with enough RAM?
Nothing to do. MongoDB just does it. But remember that each new document you query is fetch from disk, unless it’s already in RAM. If your RAM is full (or reserved for something else like the OS or the queries), then mongod will have to evict old documents from the RAM to make some room for the new ones. If your working set is too large for your RAM, you will just continuously evict documents from RAM and fetch them again from the disk a few seconds later.
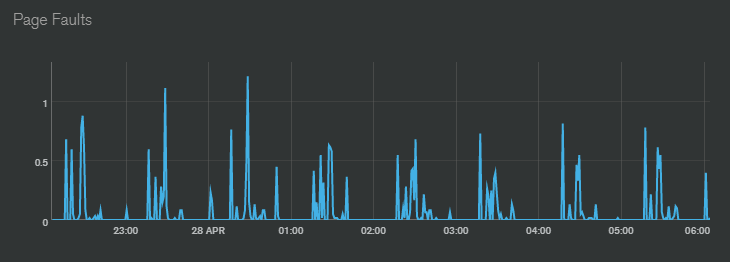
You can track this in MongoDB Atlas by checking the Page Faults.
Here is one of my cluster:
Each time my cluster runs “out” of RAM and needs to make room, I get more page faults.