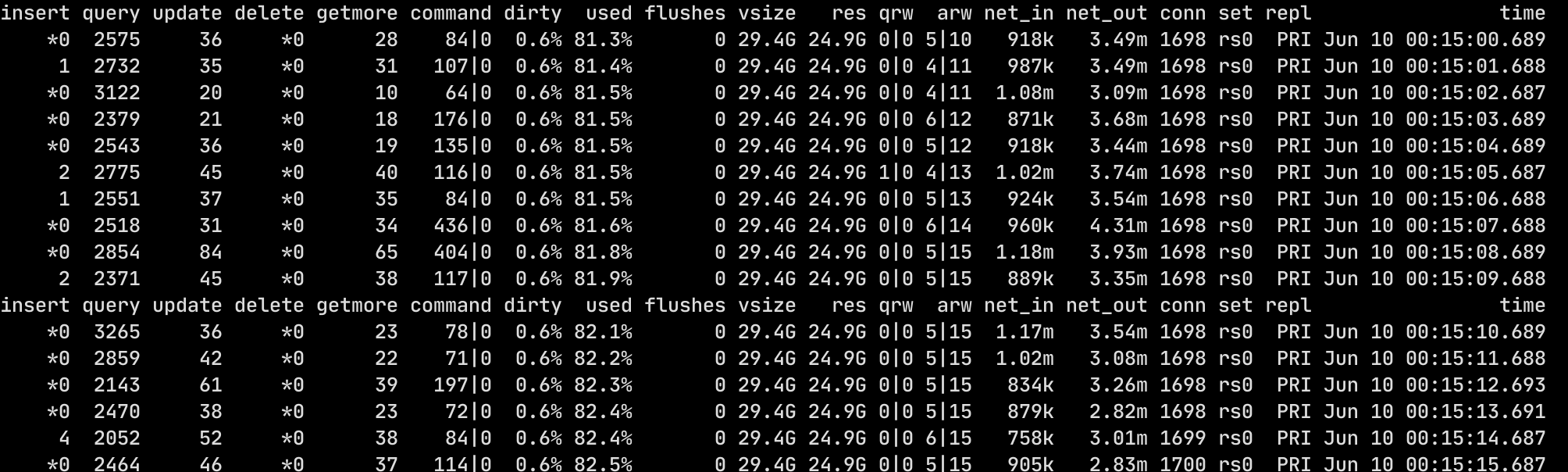
2022-06-08T01:48:02.822+0000 I NETWORK [listener] connection accepted from 172.16.106.98:44388 #68446 (1636 connections now open)
2022-06-08T01:48:02.836+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.853+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.867+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.881+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.895+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.909+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:02.923+0000 I ACCESS [conn68446] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44388
2022-06-08T01:48:03.004+0000 I NETWORK [listener] connection accepted from 127.0.0.1:35332 #68447 (1637 connections now open)
2022-06-08T01:48:03.315+0000 I COMMAND [conn26646] command db1.products command: find { find: “products”, filter: { is_active: true, is_deleted: false }, sort: { created: -1 }, projection: {}, skip: 119900, limit: 100, returnKey: false, showRecordId: false, lsid: { id: UUID(“c0889d15-d2a2-4891-8f54-bf6d8e11d368”) }, $clusterTime: { clusterTime: Timestamp(1654652882, 10), signature: { hash: BinData(0, 5DB339F8B7F72F5E1A38A2F261F3525DD1C33118), keyId: 7057813452781256841 } }, $db: “db1” } planSummary: IXSCAN { is_active: 1, created: -1 } keysExamined:120000 docsExamined:120000 cursorExhausted:1 numYields:938 nreturned:100 reslen:139555 locks:{ Global: { acquireCount: { r: 939 } }, Database: { acquireCount: { r: 939 } }, Collection: { acquireCount: { r: 939 } } } storage:{ data: { bytesRead: 14742, timeReadingMicros: 14 } } protocol:op_msg 219ms
2022-06-08T01:48:03.487+0000 I COMMAND [conn68332] command local.oplog.rs command: collStats { collstats: “oplog.rs”, $readPreference: { mode: “secondaryPreferred” }, $db: “local” } numYields:0 reslen:7143 locks:{ Global: { acquireCount: { r: 1 } }, Database: { acquireCount: { r: 1 } }, oplog: { acquireCount: { r: 1 } } } storage:{ data: { bytesRead: 56654174 } } protocol:op_query 56654ms
2022-06-08T01:48:03.487+0000 I COMMAND [conn68364] command local.oplog.rs command: collStats { collstats: “oplog.rs”, $readPreference: { mode: “secondaryPreferred” }, $db: “local” } numYields:0 reslen:7143 locks:{ Global: { acquireCount: { r: 1 } }, Database: { acquireCount: { r: 1 } }, oplog: { acquireCount: { r: 1 } } } storage:{ data: { bytesRead: 63527346 } } protocol:op_query 63527ms
2022-06-08T01:48:03.487+0000 I COMMAND [conn68440] command local.oplog.rs command: collStats { collstats: “oplog.rs”, $readPreference: { mode: “secondaryPreferred” }, $db: “local” } numYields:0 reslen:7143 locks:{ Global: { acquireCount: { r: 1 } }, Database: { acquireCount: { r: 1 } }, oplog: { acquireCount: { r: 1 } } } storage:{ data: { bytesRead: 23466243 } } protocol:op_query 23466ms
2022-06-08T01:48:03.488+0000 I COMMAND [conn2348] command db3.balances command: find { find: “balances”, filter: { created: { $lt: new Date(1654534800000) } }, sort: { created: -1 }, projection: {}, limit: 1, lsid: { id: UUID(“6b230d18-ede8-4fba-aa73-cc97a901b51b”) }, $clusterTime: { clusterTime: Timestamp(1654652812, 125), signature: { hash: BinData(0, 74934498926F07BC1FA12E736332F8EAAD2D6A0C), keyId: 7057813452781256841 } }, $db: “db3” } planSummary: IXSCAN { created: 1 } keysExamined:0 docsExamined:0 cursorExhausted:1 numYields:0 nreturned:0 reslen:231 locks:{ Global: { acquireCount: { r: 1 } }, Database: { acquireCount: { r: 1 } }, Collection: { acquireCount: { r: 1 } } } storage:{ timeWaitingMicros: { handleLock: 28808, schemaLock: 70536054 } } protocol:op_msg 70564ms
2022-06-08T01:48:03.488+0000 I NETWORK [conn68332] end connection 172.16.106.98:44040 (1636 connections now open)
2022-06-08T01:48:03.491+0000 I WRITE [conn39654] update db2.orders command: { q: { _id: ObjectId(‘629ffb1ca8338b7e97dce04f’) }, u: { $set: { somefield: “value” } }, multi: false, upsert: false } planSummary: IDHACK keysExamined:1 docsExamined:1 nMatched:1 nModified:1 keysInserted:1 keysDeleted:1 numYields:1 locks:{ Global: { acquireCount: { r: 3, w: 3 } }, Database: { acquireCount: { w: 3 } }, Collection: { acquireCount: { w: 3 } } } storage:{ data: { bytesRead: 12714, timeReadingMicros: 11 }, timeWaitingMicros: { handleLock: 2551, schemaLock: 60845939 } } 60850ms
2022-06-08T01:48:03.491+0000 I COMMAND [conn39654] command db2.$cmd command: update { update: “orders”, updates: [ { q: { _id: ObjectId(‘629ffb1ca8338b7e97dce04f’) }, u: { $set: { somefield: “value” } }, upsert: false, multi: false } ], ordered: true, lsid: { id: UUID(“880af29e-6d0b-41bf-878c-11029ac879d7”) }, txnNumber: 42, $clusterTime: { clusterTime: Timestamp(1654652820, 20), signature: { hash: BinData(0, D892514641C0A21507EBE33BA230A731093091B0), keyId: 7057813452781256841 } }, $db: “db2” } numYields:0 reslen:245 locks:{ Global: { acquireCount: { r: 6, w: 4 } }, Database: { acquireCount: { w: 4 } }, Collection: { acquireCount: { w: 4 } }, Metadata: { acquireCount: { W: 1 } } } storage:{} protocol:op_msg 60850ms
2022-06-08T01:48:03.493+0000 I COMMAND [conn26295] command db4.costs command: insert { insert: “costs”, documents: [ { status: “pending”, currency: “USD”, _id: ObjectId(‘629fffce9d7f4312150e83c5’), order: ObjectId(‘629f5020a8338bba4adc4c5e’), created: new Date(1654652878704), __v: 0 } ], ordered: true, lsid: { id: UUID(“73feff84-ee1f-4334-a69c-663409705397”) }, txnNumber: 2, $clusterTime: { clusterTime: Timestamp(1654652878, 4), signature: { hash: BinData(0, C99B37FB735574CB01648E132D4B1CB1D56E15EA), keyId: 7057813452781256841 } }, $db: “db4” } ninserted:1 keysInserted:6 numYields:0 reslen:230 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 2 } } } storage:{ data: { bytesRead: 104055, timeReadingMicros: 2071 }, timeWaitingMicros: { handleLock: 7271, schemaLock: 4776151 } } protocol:op_msg 4786ms
2022-06-08T01:48:03.496+0000 I COMMAND [conn68441] serverStatus was very slow: { after basic: 0, after advisoryHostFQDNs: 0, after asserts: 0, after backgroundFlushing: 0, after connections: 0, after dur: 0, after extra_info: 0, after freeMonitoring: 0, after globalLock: 0, after logicalSessionRecordCache: 0, after network: 0, after opLatencies: 0, after opReadConcernCounters: 0, after opcounters: 0, after opcountersRepl: 0, after oplog: 1694, after repl: 1694, after security: 1694, after storageEngine: 1694, after tcmalloc: 1694, after transactions: 1694, after transportSecurity: 1694, after wiredTiger: 1694, at end: 1695 }
2022-06-08T01:48:03.496+0000 I COMMAND [conn68441] command local.oplog.rs command: serverStatus { serverStatus: 1, advisoryHostFQDNs: 1, locks: 0, recordStats: 0, oplog: 1, $readPreference: { mode: “secondaryPreferred” }, $db: “admin” } numYields:0 reslen:33408 locks:{ Global: { acquireCount: { r: 3 } }, Database: { acquireCount: { r: 1 } }, oplog: { acquireCount: { r: 1 } } } storage:{} protocol:op_query 1695ms
2022-06-08T01:48:03.502+0000 I ACCESS [conn68440] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44314
2022-06-08T01:48:03.503+0000 I NETWORK [conn68364] end connection 172.16.106.98:44112 (1635 connections now open)
2022-06-08T01:48:03.515+0000 I ACCESS [conn68441] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44318
2022-06-08T01:48:03.516+0000 I ACCESS [conn68440] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44314
2022-06-08T01:48:03.530+0000 I ACCESS [conn68440] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44314
2022-06-08T01:48:03.533+0000 I ACCESS [conn68441] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44318
2022-06-08T01:48:03.546+0000 I ACCESS [conn68440] Successfully authenticated as principal mms-monitoring-agent on admin from client 172.16.106.98:44314
2022-06-08T01:48:03.547+0000 I WRITE [conn39369] update db2.orders command: { q: { _id: ObjectId(‘629ffb1ca8338b7e97dce04f’) }, u: { $set: { date: new Date(1654652823741) } }, multi: false, upsert: false } planSummary: IDHACK keysExamined:1 docsExamined:1 nMatched:1 nModified:1 keysInserted:1 keysDeleted:1 writeConflicts:780 numYields:780 locks:{ Global: { acquireCount: { r: 782, w: 782 } }, Database: { acquireCount: { w: 782 } }, Collection: { acquireCount: { w: 782 } } } storage:{} 59783ms
2022-06-08T01:48:03.549+0000 I COMMAND [conn39369] command db2.$cmd command: update { update: “orders”, updates: [ { q: { _id: ObjectId(‘629ffb1ca8338b7e97dce04f’) }, u: { $set: { date: new Date(1654652823741) } }, upsert: false, multi: false } ], ordered: true, lsid: { id: UUID(“ebed48c8-dc08-46df-9a04-b76f179353b0”) }, txnNumber: 39, $clusterTime: { clusterTime: Timestamp(1654652823, 6), signature: { hash: BinData(0, A69CE8B3E8DBDF008051A969595868A30CB2CBDF), keyId: 7057813452781256841 } }, $db: “db2” } numYields:0 reslen:245 locks:{ Global: { acquireCount: { r: 785, w: 783 } }, Database: { acquireCount: { w: 783 } }, Collection: { acquireCount: { w: 783 } }, Metadata: { acquireCount: { W: 1 } } } storage:{} protocol:op_msg 59785ms
2022-06-08T01:48:04.327+0000 I COMMAND [conn26646] command db1.products command: find { find: “products”, filter: { is_active: true, is_deleted: false }, sort: { created: -1 }, projection: {}, skip: 120000, limit: 100, returnKey: false, showRecordId: false, lsid: { id: UUID(“c0889d15-d2a2-4891-8f54-bf6d8e11d368”) }, $clusterTime: { clusterTime: Timestamp(1654652883, 8), signature: { hash: BinData(0, 13CB05DE002D356B635E7EB9CE4BBD2FD0D287A4), keyId: 7057813452781256841 } }, $db: “db1” } planSummary: IXSCAN { is_active: 1, created: -1 } keysExamined:120100 docsExamined:120100 cursorExhausted:1 numYields:939 nreturned:100 reslen:141777 locks:{ Global: { acquireCount: { r: 940 } }, Database: { acquireCount: { r: 940 } }, Collection: { acquireCount: { r: 940 } } } storage:{ data: { bytesRead: 58688, timeReadingMicros: 42 } } protocol:op_msg 204ms
2022-06-08T01:48:04.673+0000 I ACCESS [conn68434] Successfully authenticated as principal __system on local from client 172.16.106.98:44278
2022-06-08T01:48:04.680+0000 I ACCESS [conn68442] Successfully authenticated as principal __system on local from client 172.16.106.98:44326
2022-06-08T01:48:04.794+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:04.884+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:04.896+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:04.908+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:04.920+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:04.933+0000 I ACCESS [conn68435] Successfully authenticated as principal __system on local from client 172.16.134.149:35916
2022-06-08T01:48:05.125+0000 I COMMAND [conn26646] command db1.products command: find { find: “products”, filter: { is_active: true, is_deleted: false }, sort: { created: -1 }, projection: {}, skip: 120100, limit: 100, returnKey: false, showRecordId: false, lsid: { id: UUID(“c0889d15-d2a2-4891-8f54-bf6d8e11d368”) }, $clusterTime: { clusterTime: Timestamp(1654652883, 8), signature: { hash: BinData(0, 13CB05DE002D356B635E7EB9CE4BBD2FD0D287A4), keyId: 7057813452781256841 } }, $db: “db1” } planSummary: IXSCAN { is_active: 1, created: -1 } keysExamined:120200 docsExamined:120200 cursorExhausted:1 numYields:939 nreturned:100 reslen:137342 locks:{ Global: { acquireCount: { r: 940 } }, Database: { acquireCount: { r: 940 } }, Collection: { acquireCount: { r: 940 } } } storage:{ data: { bytesRead: 83510, timeReadingMicros: 60 } } protocol:op_msg 204ms