Hi @Jason_Tran thanks for replying.
Yes, your assumption about mongoose findById is correct.
-
The collection where this operation is run on only contains 1 document
Yes
-
The operation using findById returns the same document in 1. above
Yes
-
The size of the document in the collection
Very simple json:
{
_id: ObjectId("6359c4a3783fe200522d4c44"),
abcd: 'AAAAA',
type: 'game',
description: 'description',
image: 'image',
productUrl: 'productURL',
tags: [],
active: false,
createdAt: ISODate("2022-10-26T23:37:07.300Z"),
updatedAt: ISODate("2022-10-26T23:37:07.300Z"),
__v: 0
}
-
The full findById operation being used
db.products.find({_id: ObjectId(‘6359cfa63e858ad8d44b1780’)});
-
Output of db.collection.getIndexes()
[ { v: 2, key: { _id: 1 }, name: '_id_' } ]
- The output of .explain(“executionStats”) for the findById operation
{
explainVersion: '1',
queryPlanner: {
namespace: 'dev.products',
indexFilterSet: false,
parsedQuery: { _id: { '$eq': ObjectId("6359cfa63e858ad8d44b1780") } },
queryHash: '740C02B0',
planCacheKey: 'E351FFEC',
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: { stage: 'IDHACK' },
rejectedPlans: []
},
executionStats: {
executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages: {
stage: 'IDHACK',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keysExamined: 1,
docsExamined: 1
}
},
command: {
find: 'products',
filter: { _id: ObjectId("6359cfa63e858ad8d44b1780") },
'$db': 'dev'
},
serverInfo: {
host: 'serverlessinstance.abcde.mongodb.net',
port: 27017,
version: '6.1.0',
gitVersion: ''
},
serverParameters: {
internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 16793600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 33554432,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600
},
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1666884172, i: 14 }),
signature: {
hash: Binary(Buffer.from("", "hex"), 0),
keyId: Long("")
}
},
operationTime: Timestamp({ t: 1666884172, i: 13 })
}
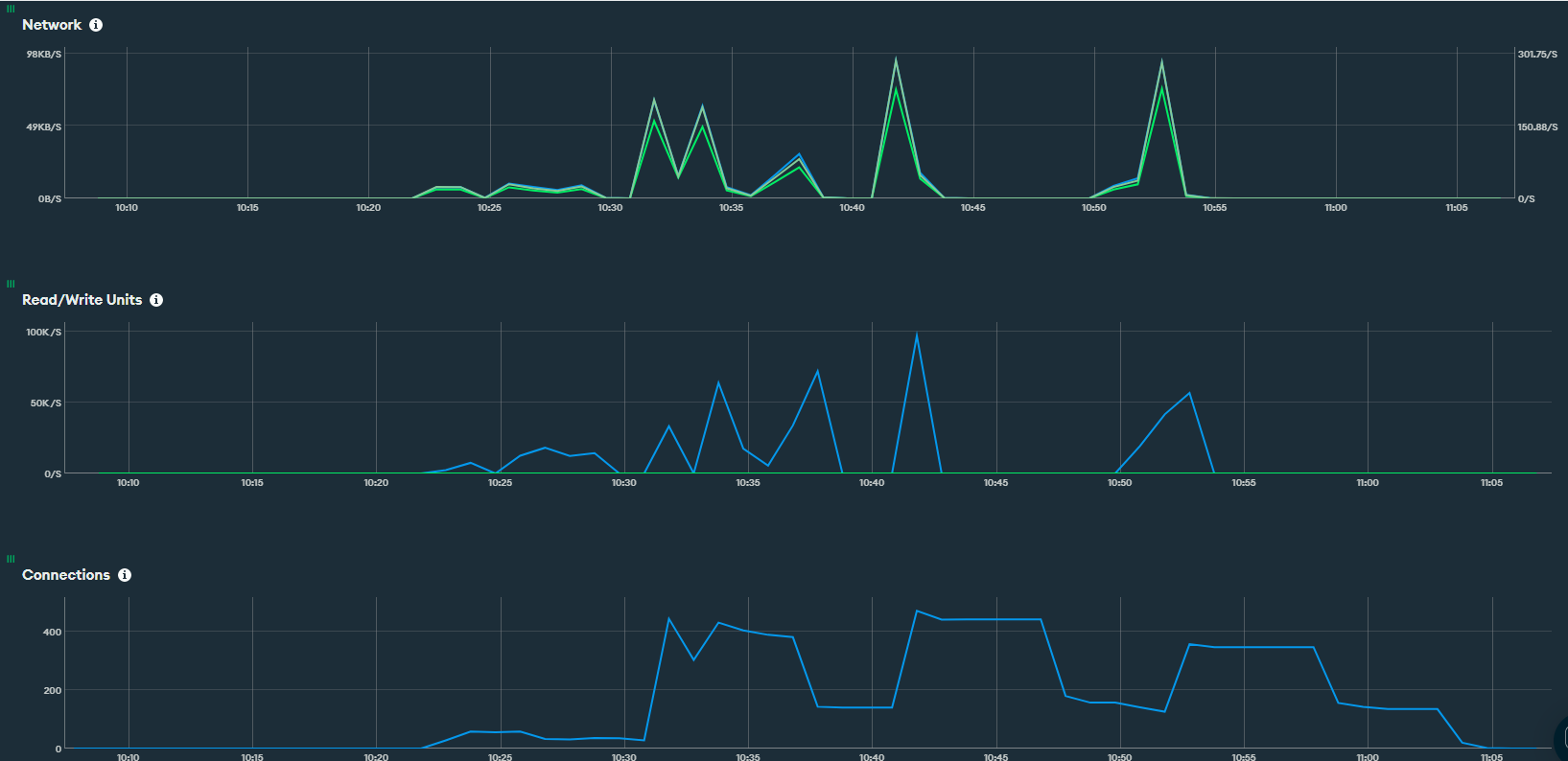
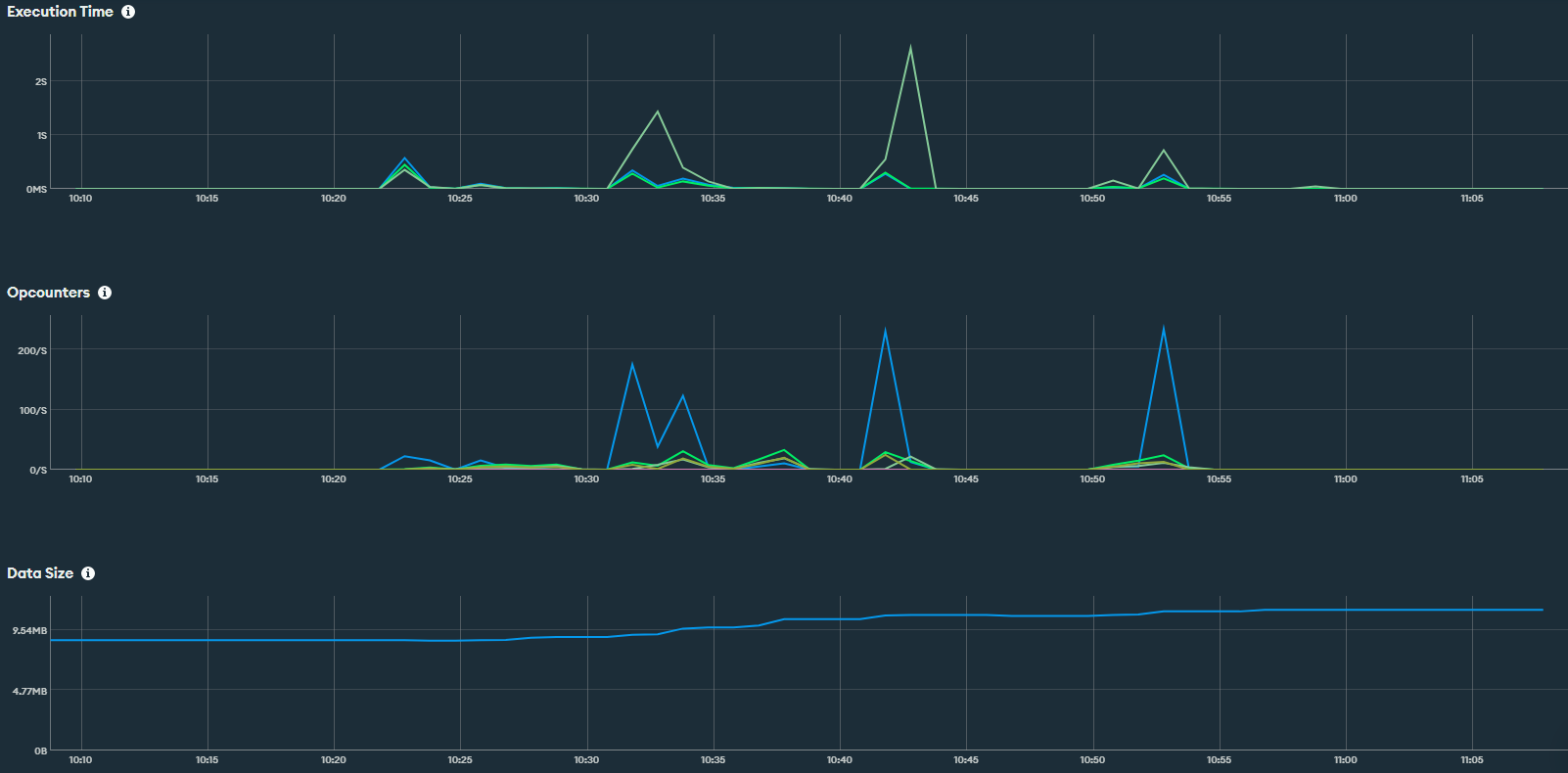
By increasing the lambda timeout I got the same behavior.
Can you provide more details regarding the load tests being performed?
I’m using [artillery.io] Artillery to run a couple of requests to a API which goes to a lambda connecting to MongoAtlas.
Getting the issue once I reach around 20req/s for a period of 20s. 400 requests in total.