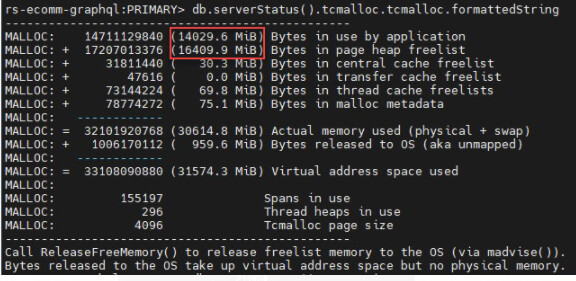
I have a RS with cache set to 18 GB and OS with 32 GB. The MongoDaemon always achieve 30GB. I know there is a lot other operations such sorts, aggregations, connections ( 1mb per connection ) queries and others that uses memory outside of cache.
My point is: How can i know where is distributed the whole memory beyond the cache ? And which means “Bytes in page heap freelist” ?
Thanky you for attentions guys, be safe and healthly!
Hi, it’s possible that wiredTiger cache could be one of the greedy consumers of your OS physical memory. Could you check ‘wiredTiger.cache’ field returned by db.serverStatus() ?
Hi Zhen, there is a lot of counters in wiredTiger.cache but i choose some could be intersting:
bytes currently in the cache => 12 GB
bytes dirty in the cache cumulative => 320 GB although that number is cumulative since the last restart
bytes allocated for updates => 400 MB
eviction worker thread evicting pages => 12717598
I didn’t see any other counter with relative larger numbers.
The way the mongod server currently works is that it will reserve a certain portion of the system RAM as the WiredTiger cache which is 50% of (RAM - 1 GB) (see WiredTiger memory use). Technically, the term “cache” here actually means that this is the memory that will be used by WiredTiger as its working memory.
In general, you are correct that operations such as incoming connections, sorting, aggregation, etc. are using the memory not reserved for the WiredTiger cache, up to the system’s available RAM. However there is currently no tracked metrics that I’m aware of that keeps track of those individual things.
Outside of WiredTiger, a mongod instance was designed to wholly take over the system in order to give you the best performance possible out of the hardware you have. Coincidentally, this is also the reason why running more than one mongod per server is discouraged, since then you’ll have two mongod processes competing with each other and end up lowering overall performance.
I guess a follow-up question I have in mind is: are you seeing any detrimental issues with regard to the mongod process taking 30GB of your system’s RAM? Regardless of the magnitude of the numbers in the statistics, are you seeing the server struggle, or underperforming? What I’m trying to say is, if you’re not seeing any issues, then the big numbers you’re seeing is the mongod process working as intended
Hi @kevinadi , thank you for the clarifications and great as usual.
My daemon is taking 29GB of 32GB, my cache is configured to 18GB running just a one database, with 40GB of data and index, and the server is struggling althouhg not any issues or underperforming.
Which scares is that daemon is using 50% of my cache for giving me the best performance. I can’t imagine that workload running in a O.S. with 16 GB.
I have a lot of other workloads with 2 TB running in a OS with 64 GB and the daemon doesn’t take over so many memory. I think that is a some particular from the app althoug i’m wondering if is it possible check all that things in serverStatus().
Yes at this point you’re getting into trickier territory of figuring out the working set size
I can’t imagine that workload running in a O.S. with 16 GB.
It appears that that specific workload basically demands at minimum a 32GB machine. Anything less than that, then the working set won’t fit in memory anymore, and you’re faced with high frequency of swapping data in and out of disk. Since disk is typically the slowest part of a machine, everything just stops and wait until the disks has finished their job.
I have a lot of other workloads with 2 TB running in a OS with 64 GB and the daemon doesn’t take over so many memory
It is also possible that even though your total data size is large, the actual working set (data that is being worked on by the server the vast majority of time) is actually much smaller, and thus you’ll have great performance even with a smaller machine. Hence, usually there is little correlation between data size and the required RAM size for good performance.
For the best performance, you’ll need your working set to fit comfortably in RAM, irrespective of the total data you have stored in the server. This is very much workload dependent, as you have observed. However, as the first step, at least you should ensure your indexes fit in RAM.
As a side note, the MongoDB University offers a free course M201: MongoDB Performance that touches on many subjects about performance, should you be interested in learning more.