Hello,
For a consequent amount of time, i have been struggling to run a simple timeseries database.
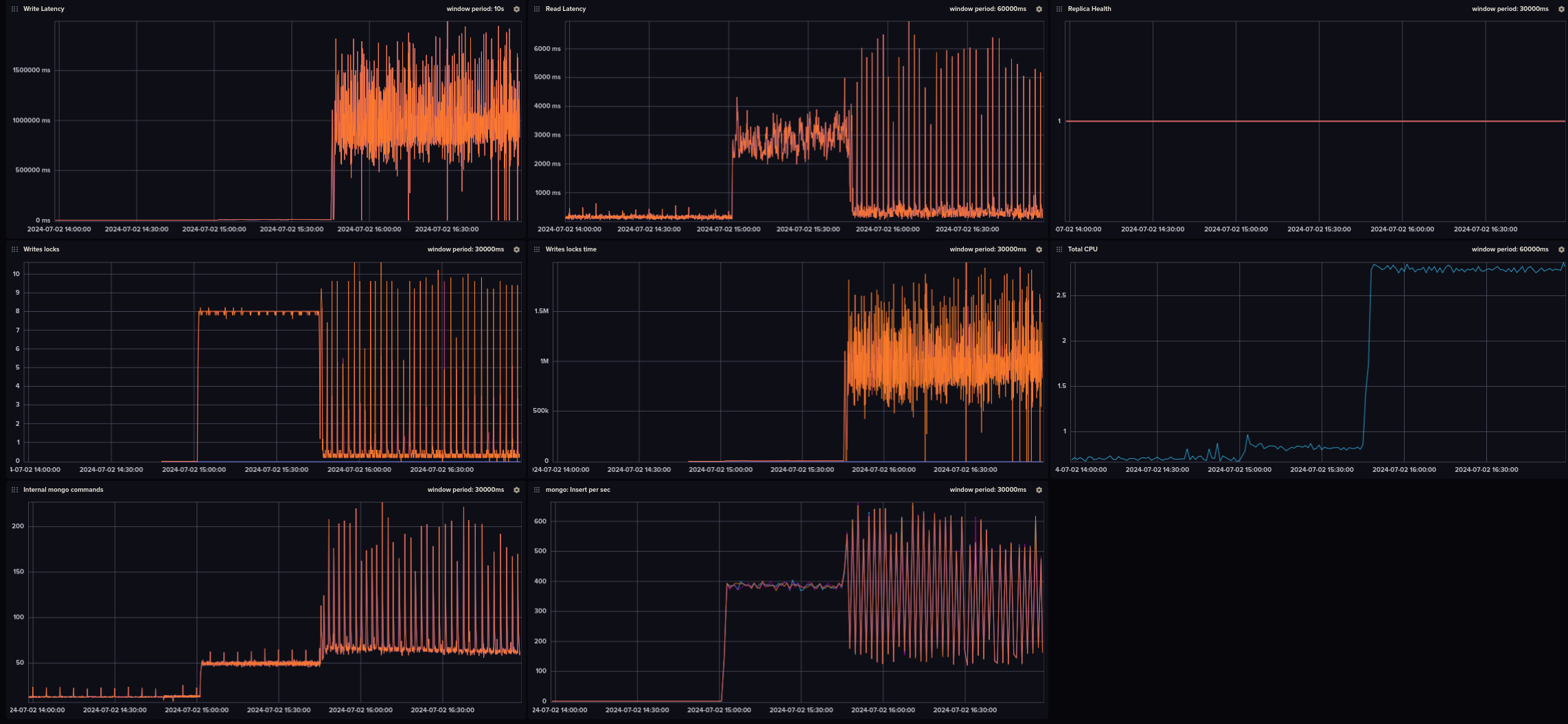
I have a 3 replica set by 3 replica cluster with a sharded timeseries collection with 2 mongos routers. This collection receives around 1000 messages / second. The timeseries use the default sharding index (metadata + timestamp).
The issue I am facing is an unstable and low ingestion rate.
When the collection is empty, the rate is “normal” (can go up to 2000 messages / sec), but after a few minutes, the rate goes down finally to stay around 100 messages / sec.
It is fed by a Kafka sink connector for mongoDB
Here are the specs and metrics:
The cluster is running in docker (on a single server)
Not really. But by having all your instances running off a single server they are all competing for the same resources. If you only have 1 machine, I would try without sharding.
There is extra work to do when sharding that I do not think you can benefit when it is not done over different hardware.
That is what I did prior to the cluster. the behavior was a single thread being always at a 100% load. The sharding allowed to distribute the load more evenly. The disk are not 100% used. Overall is seems more balance in term of load.
Also, the described behavior is the same with a single instance.