Hi.
On my 4.4.2 deployment, I’ve created one database with 20000 collections. When I issue show dbs or db.adminCommand( { listDatabases: 1}) in mongo shell for several minutes, mongod will always log the slowQuery message:
{"t":{"$date":"2021-05-18T16:51:38.567+08:00"},"s":"I", "c":"COMMAND", "id":51803, "ctx":"conn839","msg":"Slow query","attr":{"type":"command","ns":"admin.$cmd","appName":"MongoDB Shell","comma
nd":{"listDatabases":1.0,"nameOnly":false,"lsid":{"id":{"$uuid":"eed01c17-7afa-4207-9144-b7aec97721fa"}},"$clusterTime":{"clusterTime":{"$timestamp":{"t":1621326575,"i":1}},"signature":{"hash":{"$b
inary":{"base64":"AAAAAAAAAAAAAAAAAAAAAAAAAAA=","subType":"0"}},"keyId":0}},"$db":"admin"},"numYields":0,"reslen":405,"locks":{"ParallelBatchWriterMode":{"acquireCount":{"r":5}},"ReplicationStateTr
ansition":{"acquireCount":{"w":5}},"Global":{"acquireCount":{"r":5}},"Database":{"acquireCount":{"r":4}},"Collection":{"acquireCount":{"r":20014}},"Mutex":{"acquireCount":{"r":4}},"oplog":{"acquire
Count":{"r":1}}},"storage":{},"protocol":"op_msg","durationMillis":715}}
As the number of collections get bigger, the durationMillis gets larger.
Another thing I’ve noticed that if nameOnly: true is given, it’ll be fast and no slow query.
The following metrics are those that are noticeable. We can see the latency of commands goes up.
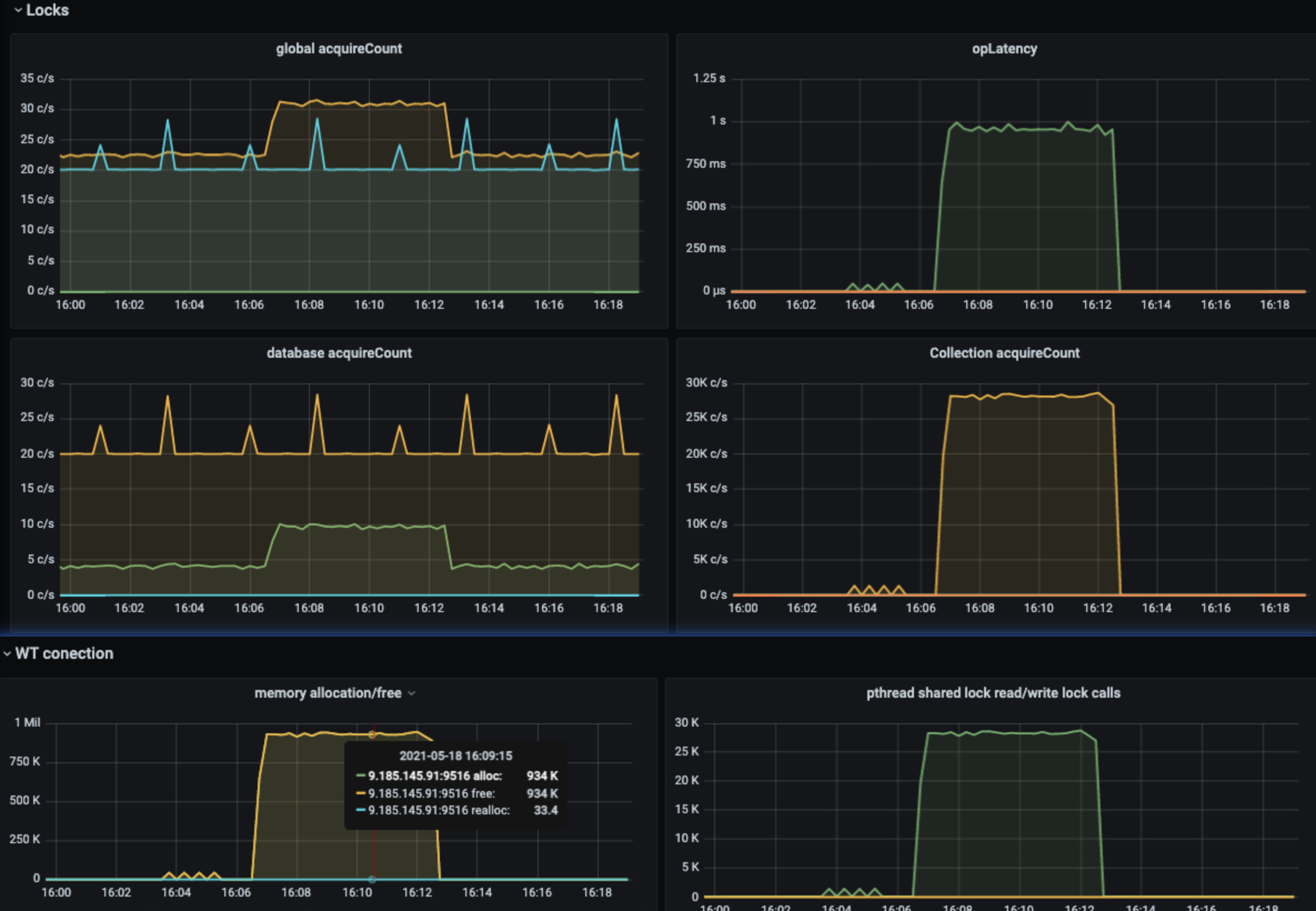
- Is the case expected ? Can we make
show dbsfast even if there’re many collections ? - I’ve noticed
db.stats()also has slow query log, butshow tableshasn’t. Any possible requests include any CRUD will have slow query log under this situation ?
