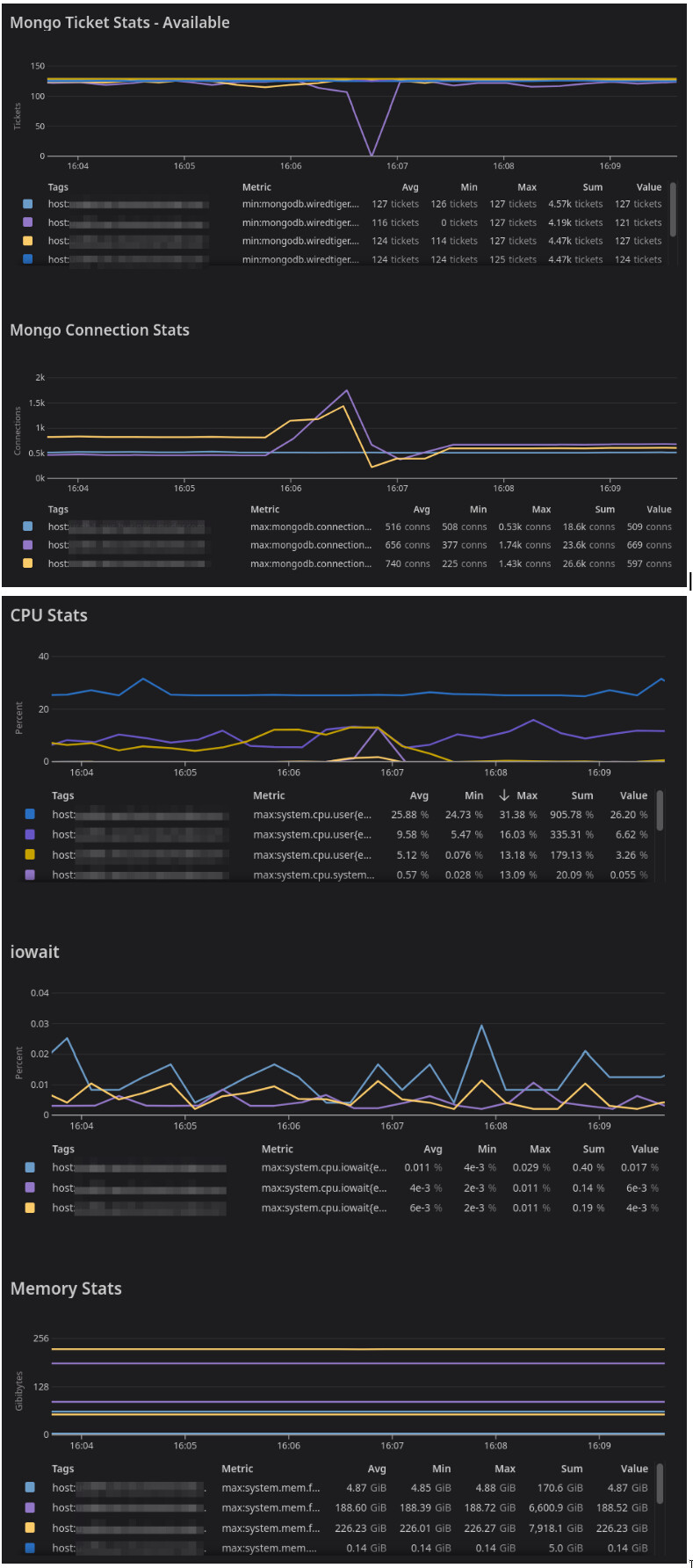
Hi all, I’m @a_ins’s coworker and I can add a little more detail to our issue. It’s a bit baffling and we’d definitely appreciate guidance from those with more specific Mongo experience.
This has been a recurring incident in which database response times and query run times spike. Queries that normally take tens of ms take several seconds. Read tickets drop and the cluster effectively locks up for a while. Then it eventually seems to work itself free and resume normal operation. The drop in read tickets occurs on both reader nodes, though sometimes one occurs before the other by seconds or minutes.
Connections do seem to spike, but I’ve found at least one incident where connections spiked after the drop in read tickets. The drop preceded the spike.
We definitely have some poorly optimized queries and indexes, and in the incident where tickets dropped prior to the connection spike there was an increase in documents returned and in unindexed queries. However, in other incidents we don’t see that.
If it was simply a slow query or queries, I wouldn’t expect it to consistently impact both readers in this way. And, while I’m still getting up to speed on the issues, my understanding of previous investigations is that there doesn’t appear to be a consistent pattern to the queries running during these incidents.
This really looks like a resource contention issue to me. My understanding of read tickets dropping to zero is that it’s usually a symptom of some other resource bottleneck that’s causing queries to hang on to read tickets for longer than usual, resulting in tickets getting used up and queries queuing. Is this an accurate understanding? Are there other potential root causes of read tickets dropping?
I struggle to think of a database scenario that should cause the whole database to lock up with out some sort of resource contention - but, granted, I’m far more experienced with relational databases than Mongo or NoSQL. And we haven’t come any where near any of our resource limits - like @a_ins said: CPU, disk, memory all look fine. We’ve got the readers on huge boxes and Mongo’s nowhere near the limits. Is it possible there’s some sort of internal resource limit preventing Mongo 4 from using all the resources on the boxes? Our writer is on a much smaller box - is it possible the resources available to the writer are limiting the readers in some way?
Is this something a poorly written or indexed query could cause: a complete lock up of the cluster with out apparent resource contention?
We’d definitely appreciate any thoughts or guidance!