can anyone help me to find a best solution for the following performance related problem.?
i have collection with fields
_id
sensorId
dateTime(including timestamp)
value1
value2
this collection has millions of data and also its increasing day by day. The query execution time is increasing day by day. Most of the time(more that 90%) i called this collection with sensorId and dateTime(with $gt or $lt or both). So, i think it should be better to create a compound index with sensorId and dateTime. Really its gives good result. but, the index size is increased dramatically. So, is it a good method? can anyone make good suggestion on this?
Welcome to the community. As I understand it, you’re facing query performance issues, tried to solve it using a compound index, but you are currently concerned by the index sizes. Is this accurate?
It would help if you can provide more context:
Please post your queries, and the query explain output by using db.collection.explain('executionStats').find(...)
Please post some example documents so it’s clear the shape of the documents in question.
Please post the output of db.collection.stats() which will show the index sizes and please point out the numbers that you’re concerned about.
Finally please include your MongoDB exact version.
In general, having indexes to back your queries is a recommended practice in all databases, not just MongoDB. See Create Indexes to Support Your Queries for some examples.
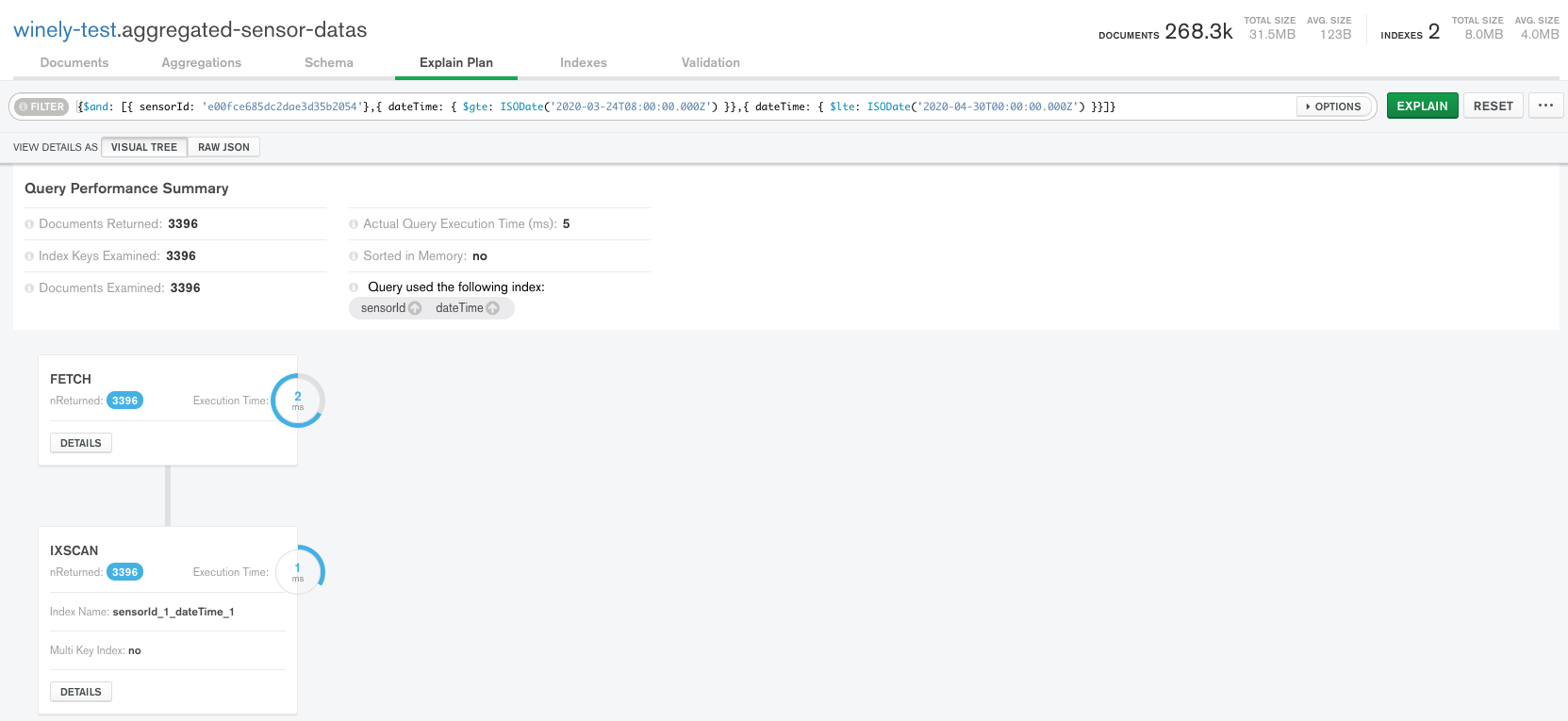
This is our test database result. same as original. Right now we have 360K documents in our data. Using this index i can fetch data correctly with good performance. but issue will be in future within months. 100X more data are coming. So, the index size will increase dramatically.
All my documents are in same structure. Sample one
{
“_id”:{"$oid":“5e813859eea99fb8a1cdcd1a”},
“sensorId”:“e00fce685dc2dae3d35b2054”,
“dateTime”:{"$date":“2020-03-30T00:07:53.000Z”},
“pH”:3.928,
“temperature”:14.9,
“capTemperature”:15,
“sg”:1.195
}
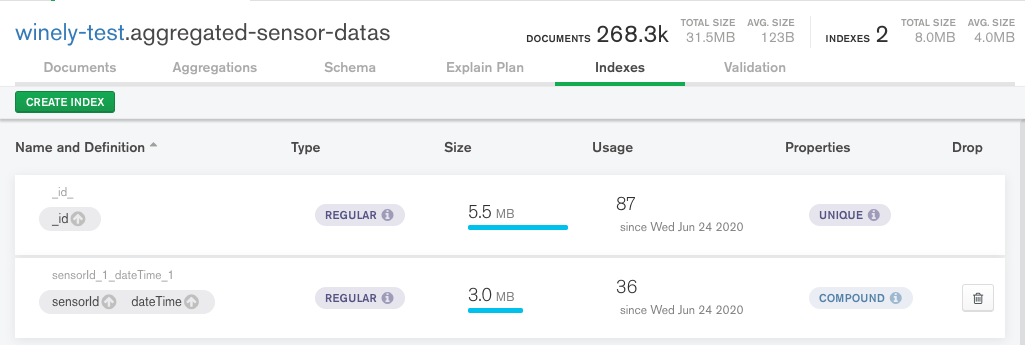
Please take a look on the image. As i said my concern is increase of index size. Now our DB has less data but by next it will increase up to 100X and will increase dramatically after that. As per my calculation, if i use this compound index, index size of the particular compound index will be 20% of the actual data.
The index you have is optimal for your query, so if your collection gets much larger, the query still should return relatively quick (with caveat of data size vs. hardware capabilities, of course).
I see you have two indexes: the mandatory _id index and the compound index. The compound index itself is 3MB, which is a bit less than 10% of the collection size.
As with most things in computing, it is a balancing act. If you feel that returning queries quickly in a large collection is worth the space tradeoff, then I encourage you to keep the compound index. Case in point, your first screenshot shows that in a collection of 268k documents, the query returned in just 5ms. For most use cases, this space vs. speed tradeoff is worth it.
However, if you feel that you can tolerate much slower query response time and if space is much more important to you, then dropping the index is an option.
Another option is to create an index only on sensorId, so your query won’t be totally unindexed.
All three options have advantages & disadvantages, so it’s up to you to choose which option is “best” for your use case.
Having said that, be aware that as your collection gets larger, scanning unnecessary documents to return a query will have other side effect as well, such as pushing your working set off memory and could possibly make everything slower (since irrelevant documents are constantly being paged into memory to be examined, only to be thrown out again).
how about a partial index just in case only a subset of the dates is need…
Actually in combination with dates I have never used a partial index. That probably only makes sense when you e.g. drop the index every X month and rebuild with $gt( today -x month). However dropping and creating an index would need to be planed.