Hello Admins,
I’d like to ask the same question because I have a hunch that this is the issue that I am facing. I am a student who is fairly new to MongoDB, I am attempting to import a tweeter json data which is currently 917mb.
That is remove the opening and closing square brackets and the comma separating each tweet. The document structure is simple and you could also use an text editor to reformat.
Thank you!
From the thread that I was reading, the guy mentioned the same. When I came back here, I felt so stupid coz the answer was already given to my stupid head and I neglected it.
@steevej
After removing the commas (using jq), I am now faced with another error:
“{Failed: error processing document #1: invalid character ‘\x1b’ looking for beginning of value}”
I tried to reformat my file in jq using the switch --ascii-output to force it to use UTF-8 chars only. But I still get this error. A quick google says its an escape char… but I really do not understand coz when I grep for this exact character (to hopefully remove it)… I don’t see an output.
Hi @Jim_Labilles welcome to MongoDB and the community!
This error “{Failed: error processing document #1: invalid character ‘\x1b’ looking for beginning of value}” seems to correspond to the screenshot you have earlier, where the field Tweet contains an emoji:
Could you copy that actual document and post it here (not the screenshot) so we can reproduce what you’re seeing?
On another note, typically it’s best not to post screenshots in posts, since it’s not searchable, and on a certain screen size it may be very difficult to read. Thanks!
Apologies for the screen shot. I’ll do as requested from here on.
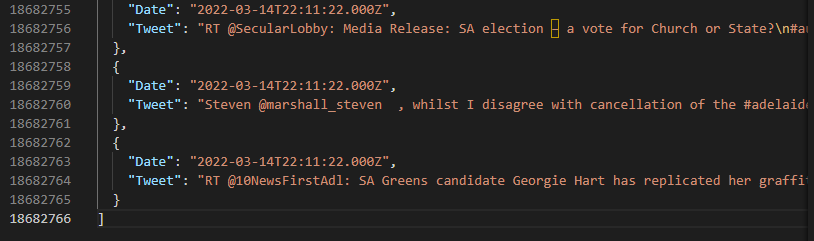
Here is the exact snippet of the first 2 JSON tweets (line 1-8)
{
"Date": "2022-03-21T21:58:35.000Z",
"Tweet": "#HomeGrowAmnesty\ud83d\udc68\u200d\ud83c\udf3e \n#SAPARLI #SAVotes #LegalLikeTomatoes https://t.co/KD9W1iove8"
}
{
"Date": "2022-03-21T21:58:35.000Z",
"Tweet": "RT @VitalSparkCapt: @SBSNews Squatters residing in Australia's Kirribilli House, complain that they are living in a dump, and intend to 'Lo\u2026"
}
See when I use the --ascii-ouput switch in JQ, I thought that would have corrected these emoji’s… I guess it didn’t
I tried creating an example document based on your posted example with different kinds of emojis, and was able to import it correctly using mongoimport.
I assume you tried to import this using mongoimport. Could you try to update the MongoDB tools by downloading from MongoDB Database Tools download page and try again?
@kevinadi
I’ve actually just tried it myself and I can confirm that it did indeed go through.
2022-03-23T19:39:36.317-0400 using write concern: &{majority false 0}
2022-03-23T19:39:36.317-0400 using 4 decoding workers
2022-03-23T19:39:36.317-0400 using 1 insert workers
2022-03-23T19:39:36.318-0400 will listen for SIGTERM, SIGINT, and SIGKILL
2022-03-23T19:39:37.044-0400 filesize: 520 bytes
2022-03-23T19:39:37.044-0400 using fields:
2022-03-23T19:39:37.044-0400 connected to: mongodb+srv://[**REDACTED**]@cluster0.1zfo5.mongodb.net/election
2022-03-23T19:39:37.044-0400 ns: election.tweets_try
2022-03-23T19:39:37.078-0400 connected to node type: replset
2022-03-23T19:39:37.150-0400 2 document(s) imported successfully. 0 document(s) failed to import.
So I’m guessing it might be a size issue. Because the only difference now is that the main file has about (approx) 3.7M objects inside vs this which has only two…
the main subject of this post has been resolved by @steevej, which I am truly grateful for and to @kevinadi for putting on the right track in finally getting this solved.
Size of the file should have nothing to do with invalid character errors. I created some example documents totalling 1.4 GB with some emojis sprinkled in and was able to import them all without errors.
If you’re using jq, I’m guessing that jq messed up the emoji codes somehow. That, or the program you used to modify this file mangled the emojis. Could you try to convert your file as per @steevej 's suggestion (remove commas, remove the [ and ]) without using jq?
Hello @kevinadi,
to be honest, JQ is the only tool I know to use confidently at this stage…
But now that I’ve finally finished the whole process, I can definitely say that JQ is the culprit (even after doing exactly as @steevej has suggested). It is doing something in the background while converting the files. To be fair, maybe my methods are also wrong.
What worked for me is:
I filtered the large file into 5 JSON files that contains 1 key:value only per file
Then I uploaded each file to the same collection one by one.
I successfully uploaded 46900 documents in mongoDB ready for analysis
The JSON filtering with JQ was done in terminal of Kali (my ubuntu is in a login loop and needs to be fixed lol). I really think this process is making the mess. A few things I noticed:
1.If I filtered the key:value pair (5 total) that I need from the main JSON file and save it to one file, it saves to a very large file - 1.7GB. While the original file was only 120MB which contains at least 20 key:value pairs per object.
2. If I took just one key:value pair and save to a file (separately)… it only saved as a 1MB files. So with 5 files they are only 5MB total.
Any way… I hope this helps someone out, that is probably as ‘noob’ as me and are having the same issue.
Thanks again @kevinadi … the things I’ve learned along the way… is so gratifying… it made the whole frustration in the beginning so… worth it!